 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactCheckmate: Preemptively Detecting and Mitigating Hallucinations in LMs
Oct 03, 2024



Language models (LMs) hallucinate. We inquire: Can we detect and mitigate hallucinations before they happen? This work answers this research question in the positive, by showing that the internal representations of LMs provide rich signals that can be used for this purpose. We introduce FactCheckMate, which preemptively detects hallucinations by learning a classifier that predicts whether the LM will hallucinate, based on the model's hidden states produced over the inputs, before decoding begins. If a hallucination is detected, FactCheckMate then intervenes, by adjusting the LM's hidden states such that the model will produce more factual outputs. FactCheckMate provides fresh insights that the inner workings of LMs can be revealed by their hidden states. Practically, both the detection and mitigation models in FactCheckMate are lightweight, adding little inference overhead; FactCheckMate proves a more efficient approach for mitigating hallucinations compared to many post-hoc alternatives. We evaluate FactCheckMate over LMs of different scales and model families (including Llama, Mistral, and Gemma), across a variety of QA datasets from different domains. Our results demonstrate the effectiveness of leveraging internal representations for early hallucination detection and mitigation, achieving over 70% preemptive detection accuracy. On average, outputs generated by LMs with intervention are 34.4% more factual compared to those without intervention. The average overhead difference in the inference time introduced by FactCheckMate is around 3.16 seconds.
AraTrust: An Evaluation of Trustworthiness for LLMs in Arabic
Mar 15, 2024



The swift progress and widespread acceptance of artificial intelligence (AI) systems highlight a pressing requirement to comprehend both the capabilities and potential risks associated with AI. Given the linguistic complexity, cultural richness, and underrepresented status of Arabic in AI research, there is a pressing need to focus on Large Language Models (LLMs) performance and safety for Arabic related tasks. Despite some progress in their development, there is a lack of comprehensive trustworthiness evaluation benchmarks which presents a major challenge in accurately assessing and improving the safety of LLMs when prompted in Arabic. In this paper, we introduce AraTrust, the first comprehensive trustworthiness benchmark for LLMs in Arabic. AraTrust comprises 516 human-written multiple-choice questions addressing diverse dimensions related to truthfulness, ethics, safety, physical health, mental health, unfairness, illegal activities, privacy, and offensive language. We evaluated a set of LLMs against our benchmark to assess their trustworthiness. GPT-4 was the most trustworthy LLM, while open-source models, particularly AceGPT 7B and Jais 13B, struggled to achieve a score of 60% in our benchmark.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
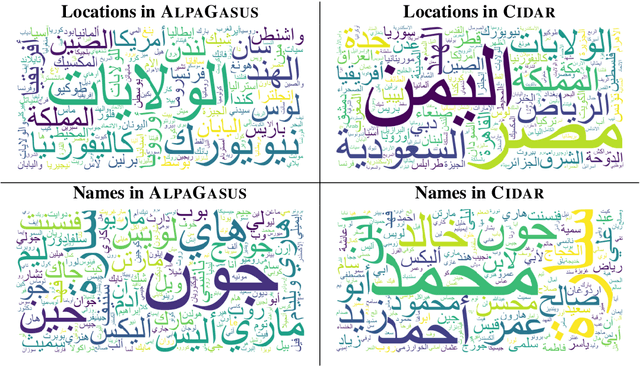
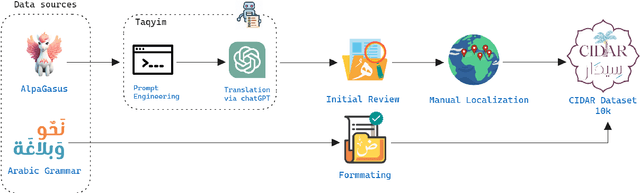

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.
Using Textual Interface to Align External Knowledge for End-to-End Task-Oriented Dialogue Systems
May 23, 2023



Traditional end-to-end task-oriented dialogue systems have been built with a modularized design. However, such design often causes misalignment between the agent response and external knowledge, due to inadequate representation of information. Furthermore, its evaluation metrics emphasize assessing the agent's pre-lexicalization response, neglecting the quality of the completed response. In this work, we propose a novel paradigm that uses a textual interface to align external knowledge and eliminate redundant processes. We demonstrate our paradigm in practice through MultiWOZ-Remake, including an interactive textual interface built for the MultiWOZ database and a correspondingly re-processed dataset. We train an end-to-end dialogue system to evaluate this new dataset. The experimental results show that our approach generates more natural final responses and achieves a greater task success rate compared to the previous models.
FaceChat: An Emotion-Aware Face-to-face Dialogue Framework
Mar 08, 2023



While current dialogue systems like ChatGPT have made significant advancements in text-based interactions, they often overlook the potential of other modalities in enhancing the overall user experience. We present FaceChat, a web-based dialogue framework that enables emotionally-sensitive and face-to-face conversations. By seamlessly integrating cutting-edge technologies in natural language processing, computer vision, and speech processing, FaceChat delivers a highly immersive and engaging user experience. FaceChat framework has a wide range of potential applications, including counseling, emotional support, and personalized customer service. The system is designed to be simple and flexible as a platform for future researchers to advance the field of multimodal dialogue systems. The code is publicly available at https://github.com/qywu/FaceChat.