 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeXtract: Light-Weight Metadata Extraction from Scientific Papers
Oct 08, 2025Metadata plays a critical role in indexing, documenting, and analyzing scientific literature, yet extracting it accurately and efficiently remains a challenging task. Traditional approaches often rely on rule-based or task-specific models, which struggle to generalize across domains and schema variations. In this paper, we present MeXtract, a family of lightweight language models designed for metadata extraction from scientific papers. The models, ranging from 0.5B to 3B parameters, are built by fine-tuning Qwen 2.5 counterparts. In their size family, MeXtract achieves state-of-the-art performance on metadata extraction on the MOLE benchmark. To further support evaluation, we extend the MOLE benchmark to incorporate model-specific metadata, providing an out-of-domain challenging subset. Our experiments show that fine-tuning on a given schema not only yields high accuracy but also transfers effectively to unseen schemas, demonstrating the robustness and adaptability of our approach. We release all the code, datasets, and models openly for the research community.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025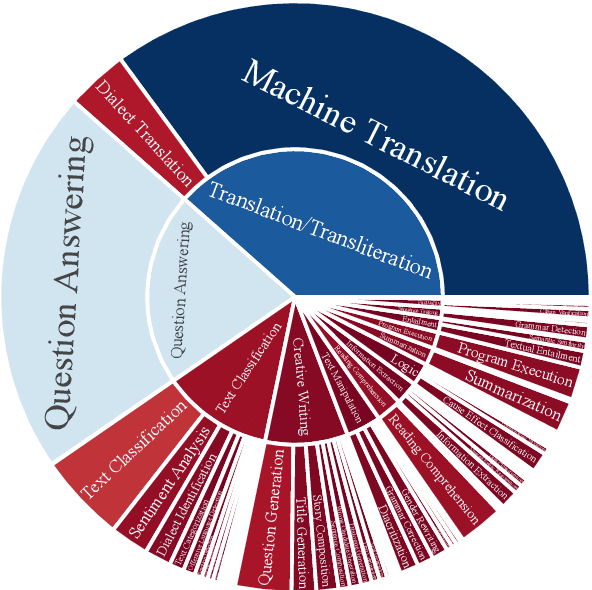



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs
May 26, 2025Metadata extraction is essential for cataloging and preserving datasets, enabling effective research discovery and reproducibility, especially given the current exponential growth in scientific research. While Masader (Alyafeai et al.,2021) laid the groundwork for extracting a wide range of metadata attributes from Arabic NLP datasets' scholarly articles, it relies heavily on manual annotation. In this paper, we present MOLE, a framework that leverages Large Language Models (LLMs) to automatically extract metadata attributes from scientific papers covering datasets of languages other than Arabic. Our schema-driven methodology processes entire documents across multiple input formats and incorporates robust validation mechanisms for consistent output. Additionally, we introduce a new benchmark to evaluate the research progress on this task. Through systematic analysis of context length, few-shot learning, and web browsing integration, we demonstrate that modern LLMs show promising results in automating this task, highlighting the need for further future work improvements to ensure consistent and reliable performance. We release the code: https://github.com/IVUL-KAUST/MOLE and dataset: https://huggingface.co/datasets/IVUL-KAUST/MOLE for the research community.
Poem Meter Classification of Recited Arabic Poetry: Integrating High-Resource Systems for a Low-Resource Task
Apr 16, 2025Arabic poetry is an essential and integral part of Arabic language and culture. It has been used by the Arabs to spot lights on their major events such as depicting brutal battles and conflicts. They also used it, as in many other languages, for various purposes such as romance, pride, lamentation, etc. Arabic poetry has received major attention from linguistics over the decades. One of the main characteristics of Arabic poetry is its special rhythmic structure as opposed to prose. This structure is referred to as a meter. Meters, along with other poetic characteristics, are intensively studied in an Arabic linguistic field called "\textit{Aroud}". Identifying these meters for a verse is a lengthy and complicated process. It also requires technical knowledge in \textit{Aruod}. For recited poetry, it adds an extra layer of processing. Developing systems for automatic identification of poem meters for recited poems need large amounts of labelled data. In this study, we propose a state-of-the-art framework to identify the poem meters of recited Arabic poetry, where we integrate two separate high-resource systems to perform the low-resource task. To ensure generalization of our proposed architecture, we publish a benchmark for this task for future research.
Arabic Stable LM: Adapting Stable LM 2 1.6B to Arabic
Dec 05, 2024Large Language Models (LLMs) have shown impressive results in multiple domains of natural language processing (NLP) but are mainly focused on the English language. Recently, more LLMs have incorporated a larger proportion of multilingual text to represent low-resource languages. In Arabic NLP, several Arabic-centric LLMs have shown remarkable results on multiple benchmarks in the past two years. However, most Arabic LLMs have more than 7 billion parameters, which increases their hardware requirements and inference latency, when compared to smaller LLMs. This paper introduces Arabic Stable LM 1.6B in a base and chat version as a small but powerful Arabic-centric LLM. Our Arabic Stable LM 1.6B chat model achieves impressive results on several benchmarks beating multiple models with up to 8x the parameters. In addition, we show the benefit of mixing in synthetic instruction tuning data by augmenting our fine-tuning data with a large synthetic dialogue dataset.
Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training
Oct 28, 2024



Recently published work on rephrasing natural text data for pre-training LLMs has shown promising results when combining the original dataset with the synthetically rephrased data. We build upon previous work by replicating existing results on C4 and extending them with our optimized rephrasing pipeline to the English, German, Italian, and Spanish Oscar subsets of CulturaX. Our pipeline leads to increased performance on standard evaluation benchmarks in both the mono- and multilingual setup. In addition, we provide a detailed study of our pipeline, investigating the choice of the base dataset and LLM for the rephrasing, as well as the relationship between the model size and the performance after pre-training. By exploring data with different perceived quality levels, we show that gains decrease with higher quality. Furthermore, we find the difference in performance between model families to be bigger than between different model sizes. This highlights the necessity for detailed tests before choosing an LLM to rephrase large amounts of data. Moreover, we investigate the effect of pre-training with synthetic data on supervised fine-tuning. Here, we find increasing but inconclusive results that highly depend on the used benchmark. These results (again) highlight the need for better benchmarking setups. In summary, we show that rephrasing multilingual and low-quality data is a very promising direction to extend LLM pre-training data.
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
Feb 20, 2024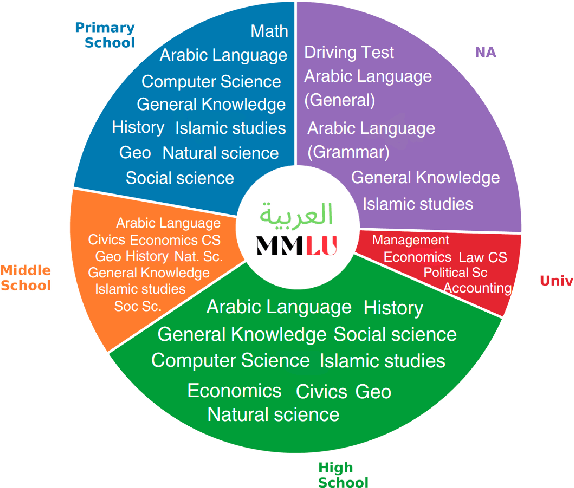



The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024
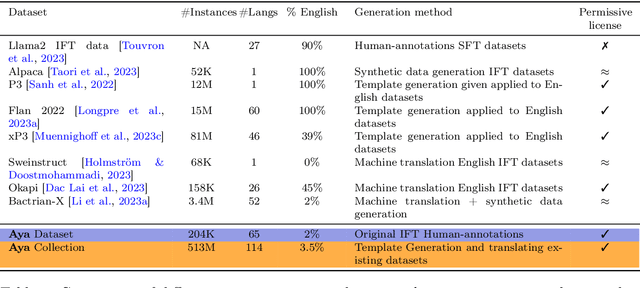
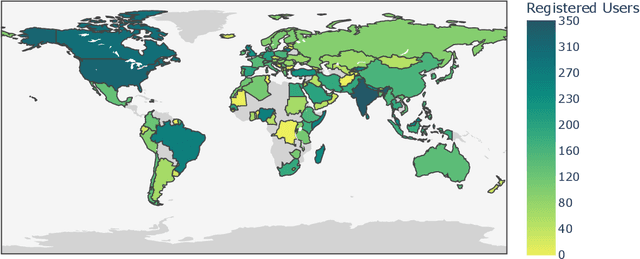
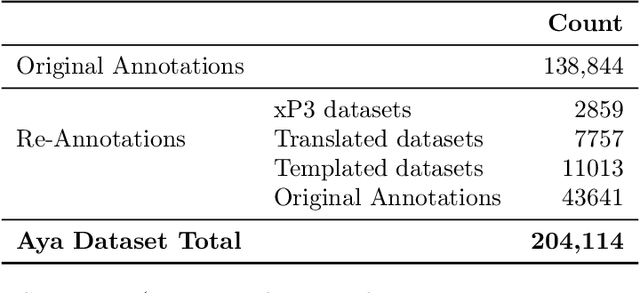
Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
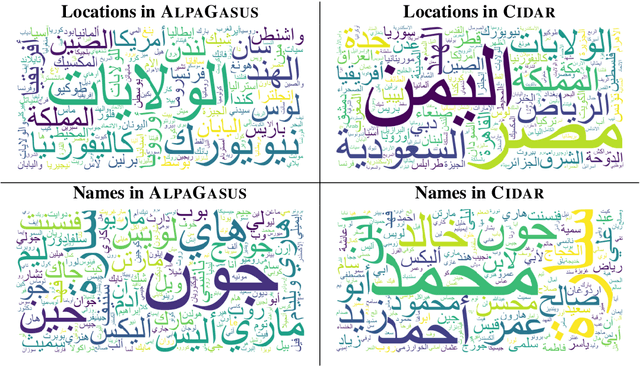
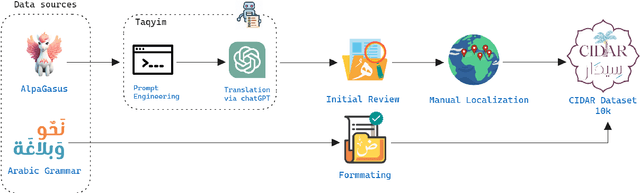

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.
Ashaar: Automatic Analysis and Generation of Arabic Poetry Using Deep Learning Approaches
Jul 12, 2023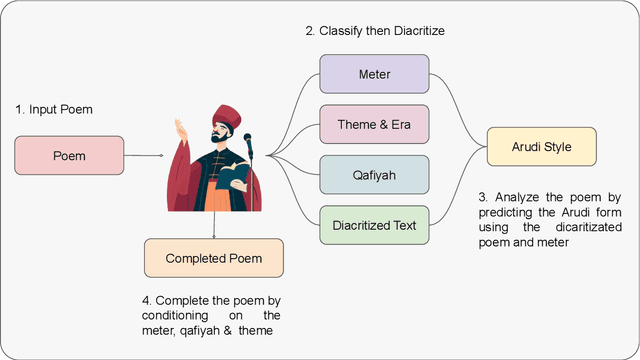
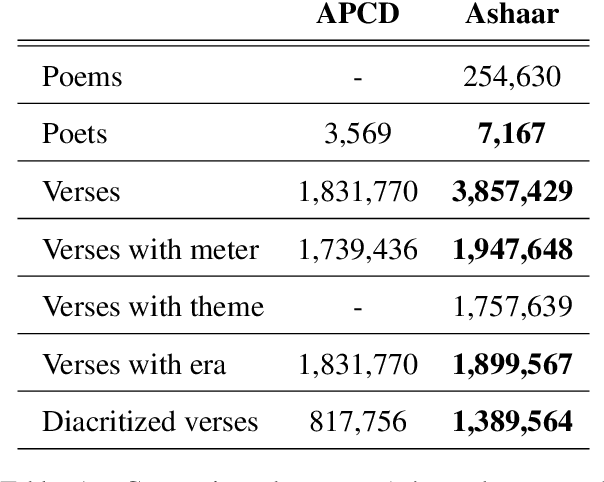
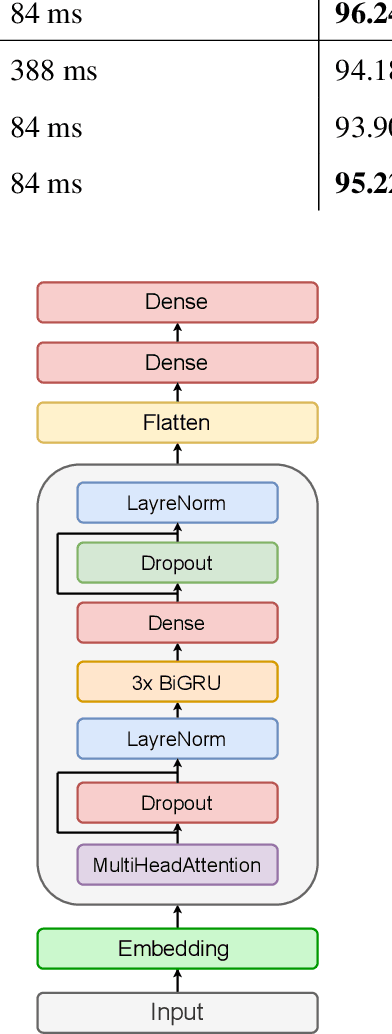
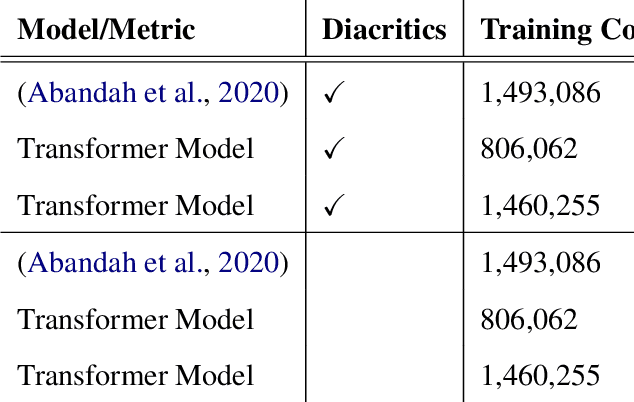
Poetry holds immense significance within the cultural and traditional fabric of any nation. It serves as a vehicle for poets to articulate their emotions, preserve customs, and convey the essence of their culture. Arabic poetry is no exception, having played a cherished role in the heritage of the Arabic community throughout history and maintaining its relevance in the present era. Typically, comprehending Arabic poetry necessitates the expertise of a linguist who can analyze its content and assess its quality. This paper presents the introduction of a framework called \textit{Ashaar} https://github.com/ARBML/Ashaar, which encompasses a collection of datasets and pre-trained models designed specifically for the analysis and generation of Arabic poetry. The pipeline established within our proposed approach encompasses various aspects of poetry, such as meter, theme, and era classification. It also incorporates automatic poetry diacritization, enabling more intricate analyses like automated extraction of the \textit{Arudi} style. Additionally, we explore the feasibility of generating conditional poetry through the pre-training of a character-based GPT model. Furthermore, as part of this endeavor, we provide four datasets: one for poetry generation, another for diacritization, and two for Arudi-style prediction. These datasets aim to facilitate research and development in the field of Arabic poetry by enabling researchers and enthusiasts to delve into the nuances of this rich literary tradition.