 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs
Mar 12, 2025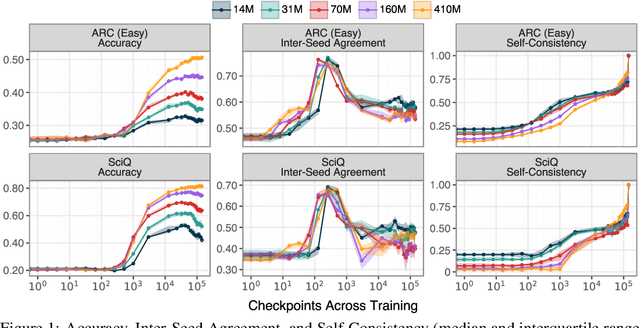

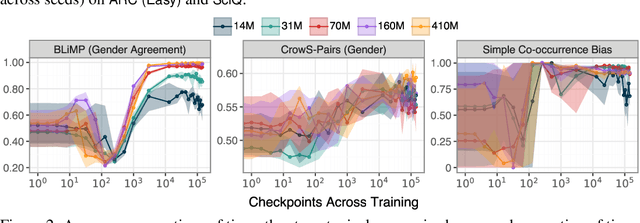
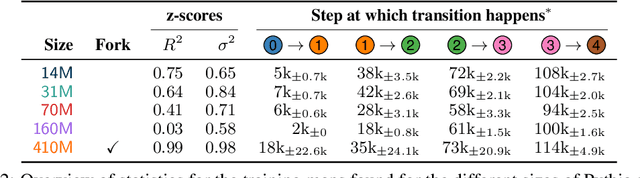
The stability of language model pre-training and its effects on downstream performance are still understudied. Prior work shows that the training process can yield significantly different results in response to slight variations in initial conditions, e.g., the random seed. Crucially, the research community still lacks sufficient resources and tools to systematically investigate pre-training stability, particularly for decoder-only language models. We introduce the PolyPythias, a set of 45 new training runs for the Pythia model suite: 9 new seeds across 5 model sizes, from 14M to 410M parameters, resulting in about 7k new checkpoints that we release. Using these new 45 training runs, in addition to the 5 already available, we study the effects of different initial conditions determined by the seed -- i.e., parameters' initialisation and data order -- on (i) downstream performance, (ii) learned linguistic representations, and (iii) emergence of training phases. In addition to common scaling behaviours, our analyses generally reveal highly consistent training dynamics across both model sizes and initial conditions. Further, the new seeds for each model allow us to identify outlier training runs and delineate their characteristics. Our findings show the potential of using these methods to predict training stability.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Self-Directed Synthetic Dialogues and Revisions Technical Report
Jul 25, 2024Synthetic data has become an important tool in the fine-tuning of language models to follow instructions and solve complex problems. Nevertheless, the majority of open data to date is often lacking multi-turn data and collected on closed models, limiting progress on advancing open fine-tuning methods. We introduce Self Directed Synthetic Dialogues (SDSD), an experimental dataset consisting of guided conversations of language models talking to themselves. The dataset consists of multi-turn conversations generated with DBRX, Llama 2 70B, and Mistral Large, all instructed to follow a conversation plan generated prior to the conversation. We also explore including principles from Constitutional AI and other related works to create synthetic preference data via revisions to the final conversation turn. We hope this work encourages further exploration in multi-turn data and the use of open models for expanding the impact of synthetic data.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


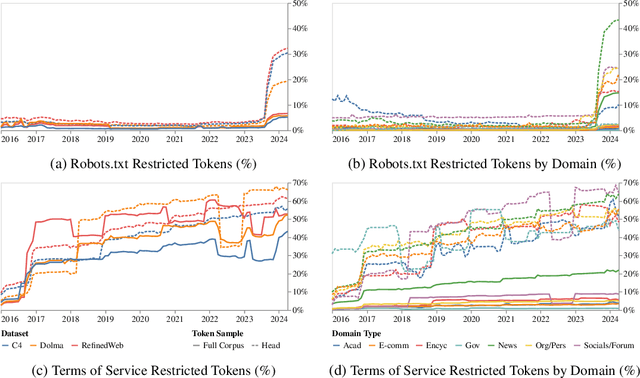
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models
Jun 24, 2024One of the most striking findings in modern research on large language models (LLMs) is that scaling up compute during training leads to better results. However, less attention has been given to the benefits of scaling compute during inference. This survey focuses on these inference-time approaches. We explore three areas under a unified mathematical formalism: token-level generation algorithms, meta-generation algorithms, and efficient generation. Token-level generation algorithms, often called decoding algorithms, operate by sampling a single token at a time or constructing a token-level search space and then selecting an output. These methods typically assume access to a language model's logits, next-token distributions, or probability scores. Meta-generation algorithms work on partial or full sequences, incorporating domain knowledge, enabling backtracking, and integrating external information. Efficient generation methods aim to reduce token costs and improve the speed of generation. Our survey unifies perspectives from three research communities: traditional natural language processing, modern LLMs, and machine learning systems.
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
Jun 06, 2024



Predictable behavior from scaling advanced AI systems is an extremely desirable property. Although a well-established literature exists on how pretraining performance scales, the literature on how particular downstream capabilities scale is significantly muddier. In this work, we take a step back and ask: why has predicting specific downstream capabilities with scale remained elusive? While many factors are certainly responsible, we identify a new factor that makes modeling scaling behavior on widely used multiple-choice question-answering benchmarks challenging. Using five model families and twelve well-established multiple-choice benchmarks, we show that downstream performance is computed from negative log likelihoods via a sequence of transformations that progressively degrade the statistical relationship between performance and scale. We then reveal the mechanism causing this degradation: downstream metrics require comparing the correct choice against a small number of specific incorrect choices, meaning accurately predicting downstream capabilities requires predicting not just how probability mass concentrates on the correct choice with scale, but also how probability mass fluctuates on specific incorrect choices with scale. We empirically study how probability mass on the correct choice co-varies with probability mass on incorrect choices with increasing compute, suggesting that scaling laws for incorrect choices might be achievable. Our work also explains why pretraining scaling laws are commonly regarded as more predictable than downstream capabilities and contributes towards establishing scaling-predictable evaluations of frontier AI models.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024
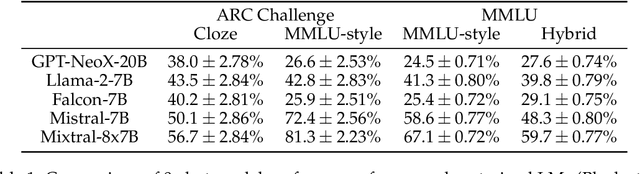
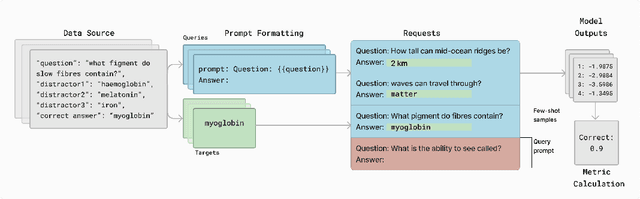

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Apr 16, 2024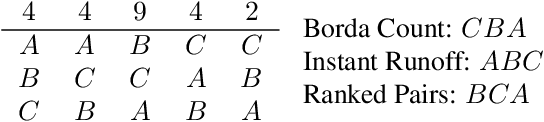
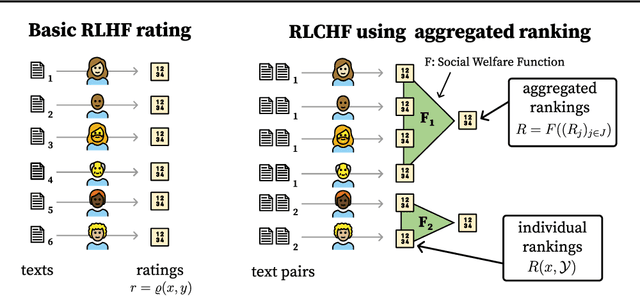
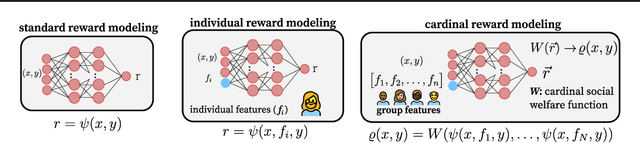
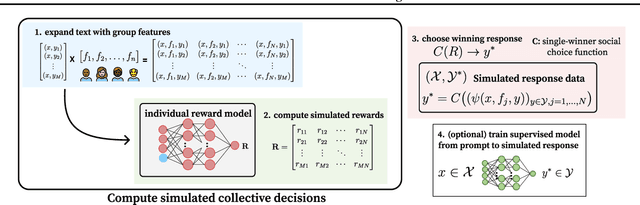
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Suppressing Pink Elephants with Direct Principle Feedback
Feb 13, 2024Existing methods for controlling language models, such as RLHF and Constitutional AI, involve determining which LLM behaviors are desirable and training them into a language model. However, in many cases, it is desirable for LLMs to be controllable at inference time, so that they can be used in multiple contexts with diverse needs. We illustrate this with the Pink Elephant Problem: instructing an LLM to avoid discussing a certain entity (a ``Pink Elephant''), and instead discuss a preferred entity (``Grey Elephant''). We apply a novel simplification of Constitutional AI, Direct Principle Feedback, which skips the ranking of responses and uses DPO directly on critiques and revisions. Our results show that after DPF fine-tuning on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model significantly outperforms Llama-2-13B-Chat and a prompted baseline, and performs as well as GPT-4 in on our curated test set assessing the Pink Elephant Problem.