 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs
Mar 12, 2025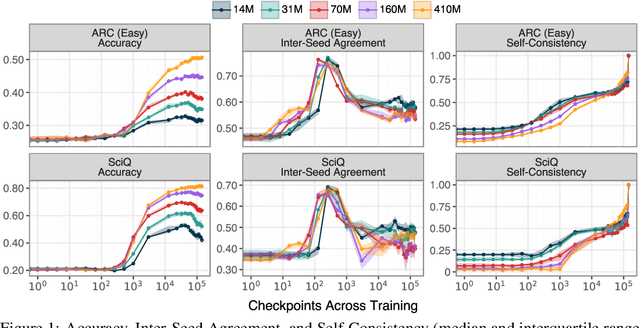

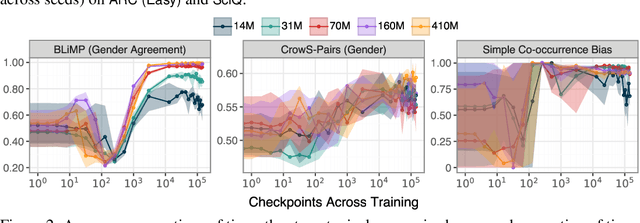
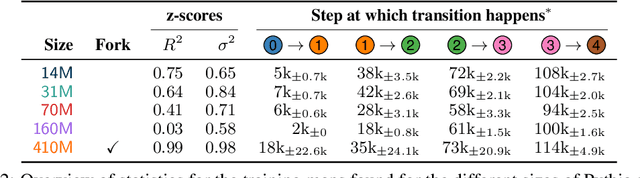
The stability of language model pre-training and its effects on downstream performance are still understudied. Prior work shows that the training process can yield significantly different results in response to slight variations in initial conditions, e.g., the random seed. Crucially, the research community still lacks sufficient resources and tools to systematically investigate pre-training stability, particularly for decoder-only language models. We introduce the PolyPythias, a set of 45 new training runs for the Pythia model suite: 9 new seeds across 5 model sizes, from 14M to 410M parameters, resulting in about 7k new checkpoints that we release. Using these new 45 training runs, in addition to the 5 already available, we study the effects of different initial conditions determined by the seed -- i.e., parameters' initialisation and data order -- on (i) downstream performance, (ii) learned linguistic representations, and (iii) emergence of training phases. In addition to common scaling behaviours, our analyses generally reveal highly consistent training dynamics across both model sizes and initial conditions. Further, the new seeds for each model allow us to identify outlier training runs and delineate their characteristics. Our findings show the potential of using these methods to predict training stability.
Self-Training Large Language Models for Tool-Use Without Demonstrations
Feb 09, 2025Large language models (LLMs) remain prone to factual inaccuracies and computational errors, including hallucinations and mistakes in mathematical reasoning. Recent work augmented LLMs with tools to mitigate these shortcomings, but often requires curated gold tool-use demonstrations. In this paper, we investigate whether LLMs can learn to use tools without demonstrations. First, we analyse zero-shot prompting strategies to guide LLMs in tool utilisation. Second, we propose a self-training method to synthesise tool-use traces using the LLM itself. We compare supervised fine-tuning and preference fine-tuning techniques for fine-tuning the model on datasets constructed using existing Question Answering (QA) datasets, i.e., TriviaQA and GSM8K. Experiments show that tool-use enhances performance on a long-tail knowledge task: 3.7% on PopQA, which is used solely for evaluation, but leads to mixed results on other datasets, i.e., TriviaQA, GSM8K, and NQ-Open. Our findings highlight the potential and challenges of integrating external tools into LLMs without demonstrations.
Tending Towards Stability: Convergence Challenges in Small Language Models
Oct 15, 2024Increasing the number of parameters in language models is a common strategy to enhance their performance. However, smaller language models remain valuable due to their lower operational costs. Despite their advantages, smaller models frequently underperform compared to their larger counterparts, even when provided with equivalent data and computational resources. Specifically, their performance tends to degrade in the late pretraining phase. This is anecdotally attributed to their reduced representational capacity. Yet, the exact causes of this performance degradation remain unclear. We use the Pythia model suite to analyse the training dynamics that underlie this phenomenon. Across different model sizes, we investigate the convergence of the Attention and MLP activations to their final state and examine how the effective rank of their parameters influences this process. We find that nearly all layers in larger models stabilise early in training - within the first 20% - whereas layers in smaller models exhibit slower and less stable convergence, especially when their parameters have lower effective rank. By linking the convergence of layers' activations to their parameters' effective rank, our analyses can guide future work to address inefficiencies in the learning dynamics of small models.
Causal Estimation of Memorisation Profiles
Jun 06, 2024



Understanding memorisation in language models has practical and societal implications, e.g., studying models' training dynamics or preventing copyright infringements. Prior work defines memorisation as the causal effect of training with an instance on the model's ability to predict that instance. This definition relies on a counterfactual: the ability to observe what would have happened had the model not seen that instance. Existing methods struggle to provide computationally efficient and accurate estimates of this counterfactual. Further, they often estimate memorisation for a model architecture rather than for a specific model instance. This paper fills an important gap in the literature, proposing a new, principled, and efficient method to estimate memorisation based on the difference-in-differences design from econometrics. Using this method, we characterise a model's memorisation profile--its memorisation trends across training--by only observing its behaviour on a small set of instances throughout training. In experiments with the Pythia model suite, we find that memorisation (i) is stronger and more persistent in larger models, (ii) is determined by data order and learning rate, and (iii) has stable trends across model sizes, thus making memorisation in larger models predictable from smaller ones.
AnchorAL: Computationally Efficient Active Learning for Large and Imbalanced Datasets
Apr 08, 2024Active learning for imbalanced classification tasks is challenging as the minority classes naturally occur rarely. Gathering a large pool of unlabelled data is thus essential to capture minority instances. Standard pool-based active learning is computationally expensive on large pools and often reaches low accuracy by overfitting the initial decision boundary, thus failing to explore the input space and find minority instances. To address these issues we propose AnchorAL. At each iteration, AnchorAL chooses class-specific instances from the labelled set, or anchors, and retrieves the most similar unlabelled instances from the pool. This resulting subpool is then used for active learning. Using a small, fixed-sized subpool AnchorAL allows scaling any active learning strategy to large pools. By dynamically selecting different anchors at each iteration it promotes class balance and prevents overfitting the initial decision boundary, thus promoting the discovery of new clusters of minority instances. Experiments across different classification tasks, active learning strategies, and model architectures AnchorAL is (i) faster, often reducing runtime from hours to minutes, (ii) trains more performant models, (iii) and returns more balanced datasets than competing methods.
Diable: Efficient Dialogue State Tracking as Operations on Tables
May 26, 2023Sequence-to-sequence state-of-the-art systems for dialogue state tracking (DST) use the full dialogue history as input, represent the current state as a list with all the slots, and generate the entire state from scratch at each dialogue turn. This approach is inefficient, especially when the number of slots is large and the conversation is long. In this paper, we propose Diable, a new task formalisation that simplifies the design and implementation of efficient DST systems and allows one to easily plug and play large language models. We represent the dialogue state as a table and formalise DST as a table manipulation task. At each turn, the system updates the previous state by generating table operations based on the dialogue context. Extensive experimentation on the MultiWoz datasets demonstrates that Diable (i) outperforms strong efficient DST baselines, (ii) is 2.4x more time efficient than current state-of-the-art methods while retaining competitive Joint Goal Accuracy, and (iii) is robust to noisy data annotations due to the table operations approach.