 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling and Mitigating Safety Alignment Degradation of Vision-Language Models
Oct 11, 2024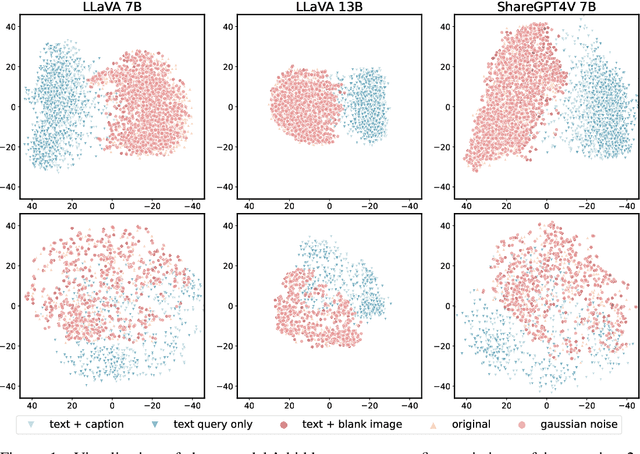
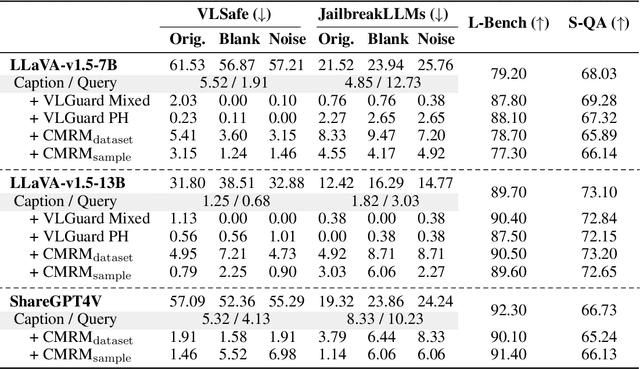
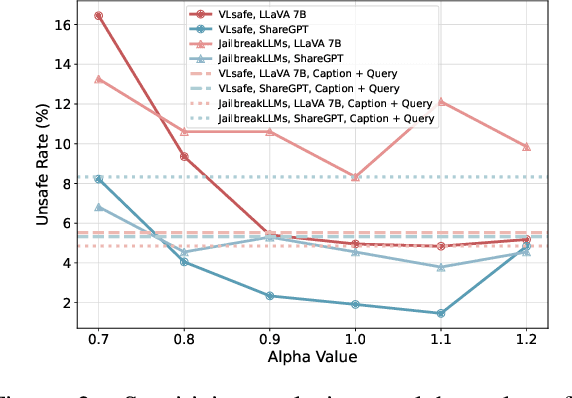

The safety alignment ability of Vision-Language Models (VLMs) is prone to be degraded by the integration of the vision module compared to its LLM backbone. We investigate this phenomenon, dubbed as ''safety alignment degradation'' in this paper, and show that the challenge arises from the representation gap that emerges when introducing vision modality to VLMs. In particular, we show that the representations of multi-modal inputs shift away from that of text-only inputs which represent the distribution that the LLM backbone is optimized for. At the same time, the safety alignment capabilities, initially developed within the textual embedding space, do not successfully transfer to this new multi-modal representation space. To reduce safety alignment degradation, we introduce Cross-Modality Representation Manipulation (CMRM), an inference time representation intervention method for recovering the safety alignment ability that is inherent in the LLM backbone of VLMs, while simultaneously preserving the functional capabilities of VLMs. The empirical results show that our framework significantly recovers the alignment ability that is inherited from the LLM backbone with minimal impact on the fluency and linguistic capabilities of pre-trained VLMs even without additional training. Specifically, the unsafe rate of LLaVA-7B on multi-modal input can be reduced from 61.53% to as low as 3.15% with only inference-time intervention. WARNING: This paper contains examples of toxic or harmful language.
Diable: Efficient Dialogue State Tracking as Operations on Tables
May 26, 2023Sequence-to-sequence state-of-the-art systems for dialogue state tracking (DST) use the full dialogue history as input, represent the current state as a list with all the slots, and generate the entire state from scratch at each dialogue turn. This approach is inefficient, especially when the number of slots is large and the conversation is long. In this paper, we propose Diable, a new task formalisation that simplifies the design and implementation of efficient DST systems and allows one to easily plug and play large language models. We represent the dialogue state as a table and formalise DST as a table manipulation task. At each turn, the system updates the previous state by generating table operations based on the dialogue context. Extensive experimentation on the MultiWoz datasets demonstrates that Diable (i) outperforms strong efficient DST baselines, (ii) is 2.4x more time efficient than current state-of-the-art methods while retaining competitive Joint Goal Accuracy, and (iii) is robust to noisy data annotations due to the table operations approach.
Pairwise Neural Machine Translation Evaluation
Dec 05, 2019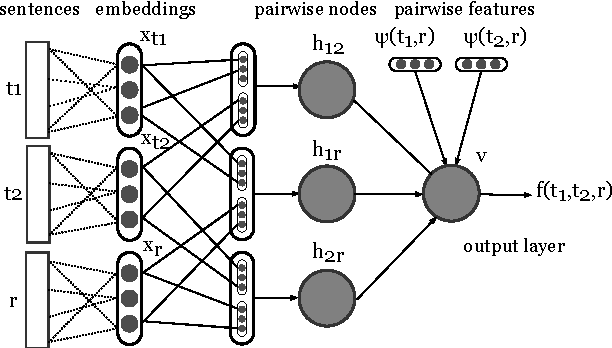
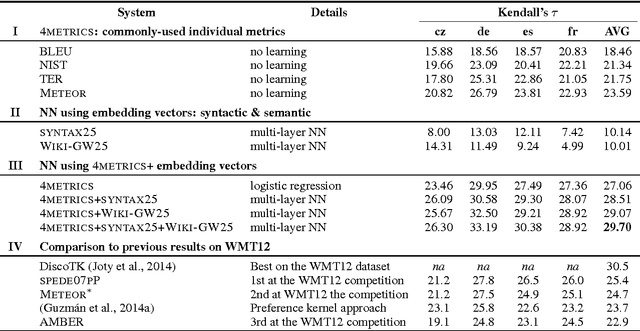
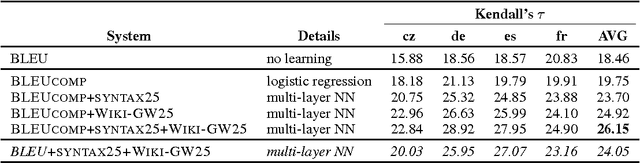
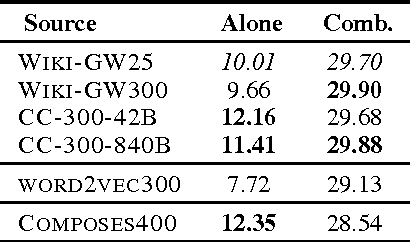
We present a novel framework for machine translation evaluation using neural networks in a pairwise setting, where the goal is to select the better translation from a pair of hypotheses, given the reference translation. In this framework, lexical, syntactic and semantic information from the reference and the two hypotheses is compacted into relatively small distributed vector representations, and fed into a multi-layer neural network that models the interaction between each of the hypotheses and the reference, as well as between the two hypotheses. These compact representations are in turn based on word and sentence embeddings, which are learned using neural networks. The framework is flexible, allows for efficient learning and classification, and yields correlation with humans that rivals the state of the art.
* machine translation evaluation, machine translation, pairwise ranking, learning to rank. arXiv admin note: substantial text overlap with arXiv:1710.02095
DiscoTK: Using Discourse Structure for Machine Translation Evaluation
Nov 28, 2019
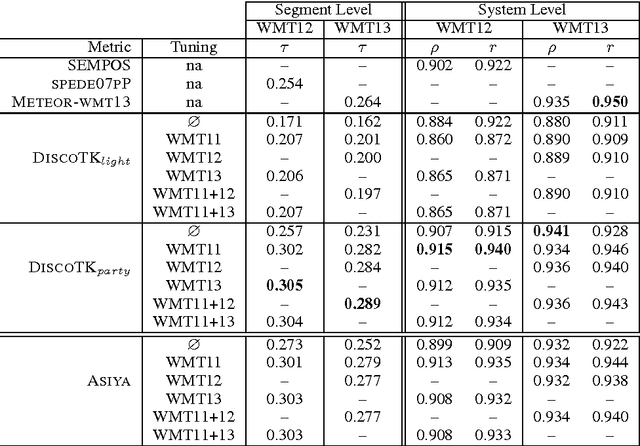
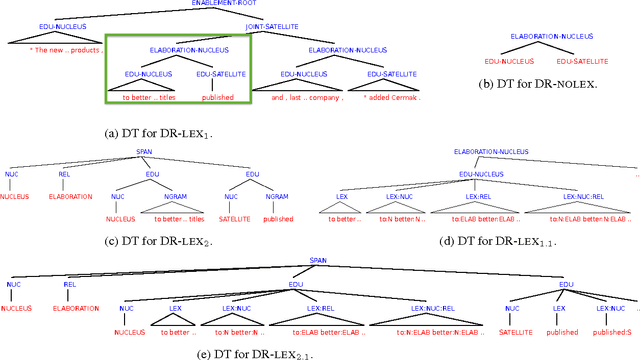
We present novel automatic metrics for machine translation evaluation that use discourse structure and convolution kernels to compare the discourse tree of an automatic translation with that of the human reference. We experiment with five transformations and augmentations of a base discourse tree representation based on the rhetorical structure theory, and we combine the kernel scores for each of them into a single score. Finally, we add other metrics from the ASIYA MT evaluation toolkit, and we tune the weights of the combination on actual human judgments. Experiments on the WMT12 and WMT13 metrics shared task datasets show correlation with human judgments that outperforms what the best systems that participated in these years achieved, both at the segment and at the system level.
* machine translation evaluation, machine translation, tree kernels, discourse, convolutional kernels, discourse tree, RST, rhetorical structure theory, ASIYA
Joint Multitask Learning for Community Question Answering Using Task-Specific Embeddings
Sep 24, 2018
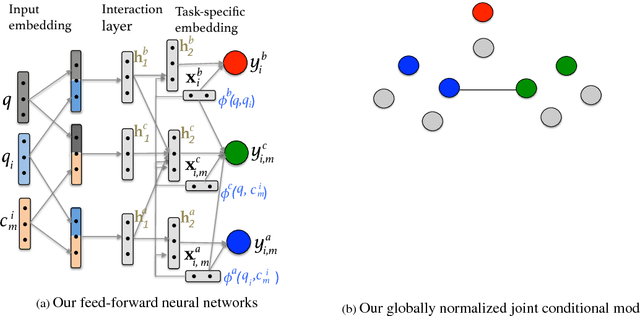
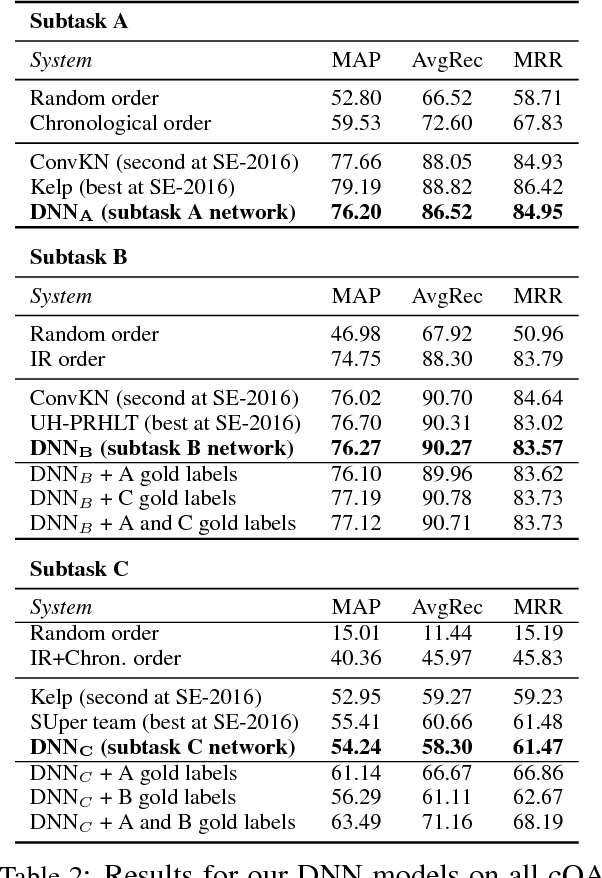
We address jointly two important tasks for Question Answering in community forums: given a new question, (i) find related existing questions, and (ii) find relevant answers to this new question. We further use an auxiliary task to complement the previous two, i.e., (iii) find good answers with respect to the thread question in a question-comment thread. We use deep neural networks (DNNs) to learn meaningful task-specific embeddings, which we then incorporate into a conditional random field (CRF) model for the multitask setting, performing joint learning over a complex graph structure. While DNNs alone achieve competitive results when trained to produce the embeddings, the CRF, which makes use of the embeddings and the dependencies between the tasks, improves the results significantly and consistently across a variety of evaluation metrics, thus showing the complementarity of DNNs and structured learning.
Integrating Stance Detection and Fact Checking in a Unified Corpus
Apr 21, 2018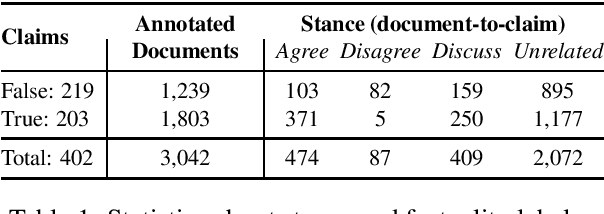
A reasonable approach for fact checking a claim involves retrieving potentially relevant documents from different sources (e.g., news websites, social media, etc.), determining the stance of each document with respect to the claim, and finally making a prediction about the claim's factuality by aggregating the strength of the stances, while taking the reliability of the source into account. Moreover, a fact checking system should be able to explain its decision by providing relevant extracts (rationales) from the documents. Yet, this setup is not directly supported by existing datasets, which treat fact checking, document retrieval, source credibility, stance detection and rationale extraction as independent tasks. In this paper, we support the interdependencies between these tasks as annotations in the same corpus. We implement this setup on an Arabic fact checking corpus, the first of its kind.
ClaimRank: Detecting Check-Worthy Claims in Arabic and English
Apr 20, 2018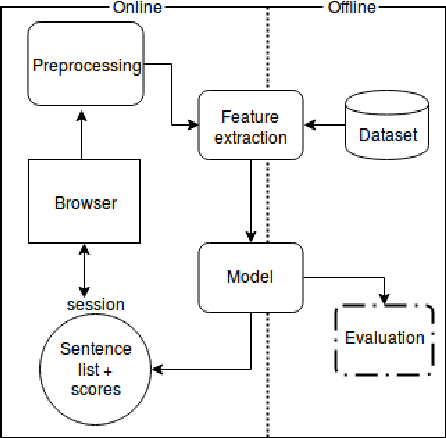

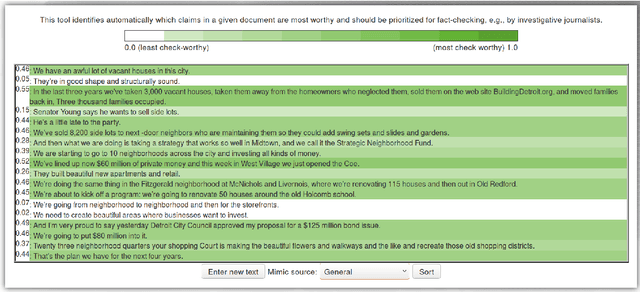
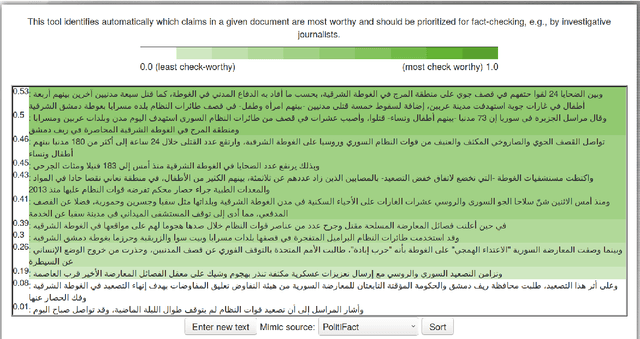
We present ClaimRank, an online system for detecting check-worthy claims. While originally trained on political debates, the system can work for any kind of text, e.g., interviews or regular news articles. Its aim is to facilitate manual fact-checking efforts by prioritizing the claims that fact-checkers should consider first. ClaimRank supports both Arabic and English, it is trained on actual annotations from nine reputable fact-checking organizations (PolitiFact, FactCheck, ABC, CNN, NPR, NYT, Chicago Tribune, The Guardian, and Washington Post), and thus it can mimic the claim selection strategies for each and any of them, as well as for the union of them all.
* Check-worthiness; Fact-Checking; Veracity; Community-Question Answering; Neural Networks; Arabic; English
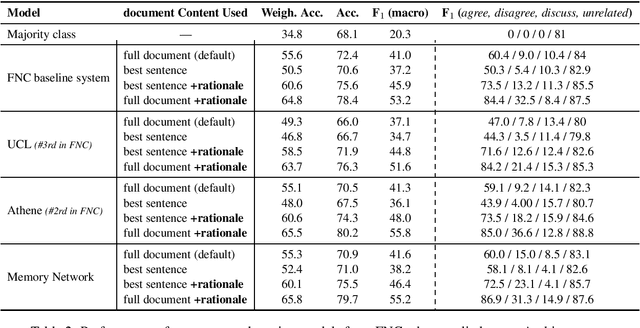
Automatic Stance Detection Using End-to-End Memory Networks
Apr 20, 2018

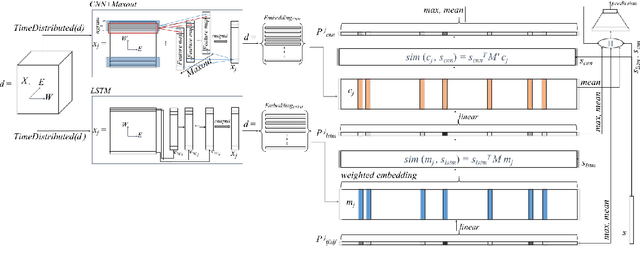
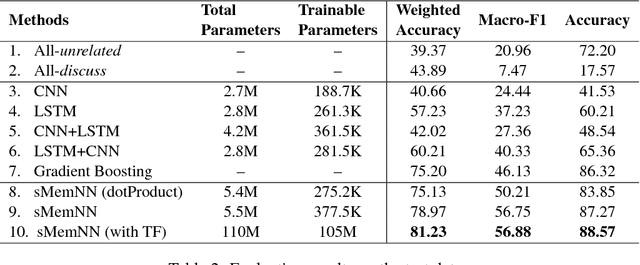
We present a novel end-to-end memory network for stance detection, which jointly (i) predicts whether a document agrees, disagrees, discusses or is unrelated with respect to a given target claim, and also (ii) extracts snippets of evidence for that prediction. The network operates at the paragraph level and integrates convolutional and recurrent neural networks, as well as a similarity matrix as part of the overall architecture. The experimental evaluation on the Fake News Challenge dataset shows state-of-the-art performance.
Fact Checking in Community Forums
Mar 08, 2018
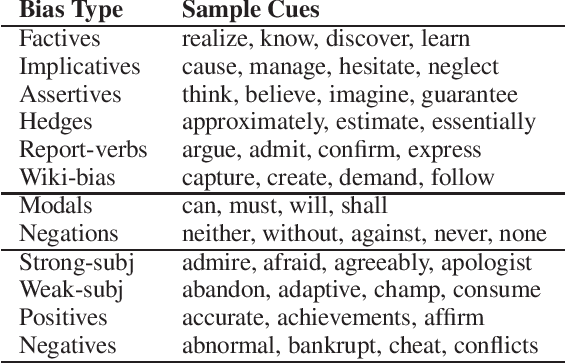
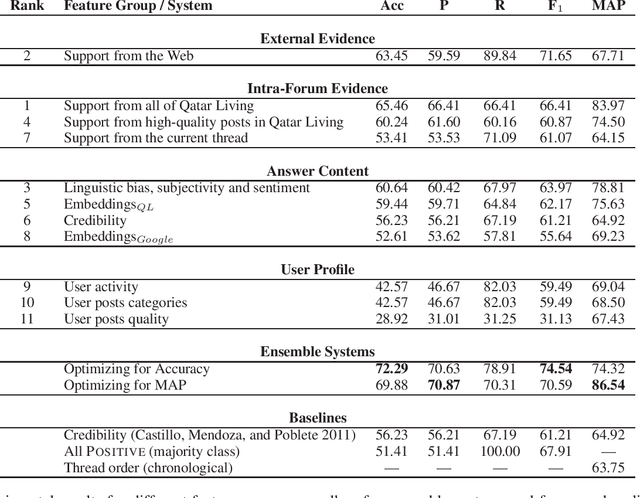

Community Question Answering (cQA) forums are very popular nowadays, as they represent effective means for communities around particular topics to share information. Unfortunately, this information is not always factual. Thus, here we explore a new dimension in the context of cQA, which has been ignored so far: checking the veracity of answers to particular questions in cQA forums. As this is a new problem, we create a specialized dataset for it. We further propose a novel multi-faceted model, which captures information from the answer content (what is said and how), from the author profile (who says it), from the rest of the community forum (where it is said), and from external authoritative sources of information (external support). Evaluation results show a MAP value of 86.54, which is 21 points absolute above the baseline.
Cross-Language Question Re-Ranking
Oct 04, 2017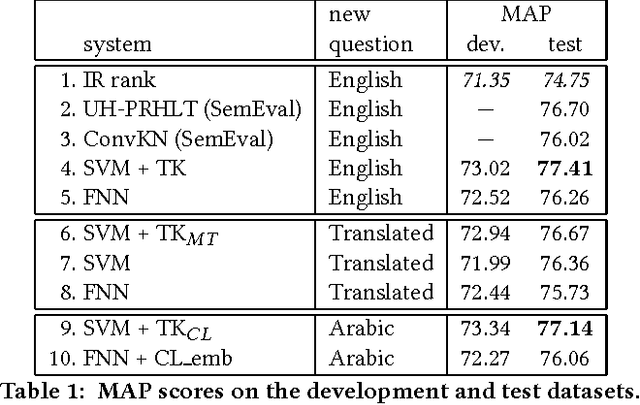
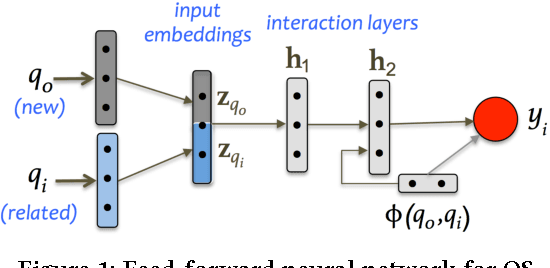
We study how to find relevant questions in community forums when the language of the new questions is different from that of the existing questions in the forum. In particular, we explore the Arabic-English language pair. We compare a kernel-based system with a feed-forward neural network in a scenario where a large parallel corpus is available for training a machine translation system, bilingual dictionaries, and cross-language word embeddings. We observe that both approaches degrade the performance of the system when working on the translated text, especially the kernel-based system, which depends heavily on a syntactic kernel. We address this issue using a cross-language tree kernel, which compares the original Arabic tree to the English trees of the related questions. We show that this kernel almost closes the performance gap with respect to the monolingual system. On the neural network side, we use the parallel corpus to train cross-language embeddings, which we then use to represent the Arabic input and the English related questions in the same space. The results also improve to close to those of the monolingual neural network. Overall, the kernel system shows a better performance compared to the neural network in all cases.
* SIGIR-2017; Community Question Answering; Cross-language Approaches; Question Retrieval; Kernel-based Methods; Neural Networks; Distributed Representations