 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHg-I2P: Bridging Modalities for Generalizable Image-to-Point-Cloud Registration via Heterogeneous Graphs
Mar 30, 2026Image-to-point-cloud (I2P) registration aims to align 2D images with 3D point clouds by establishing reliable 2D-3D correspondences. The drastic modality gap between images and point clouds makes it challenging to learn features that are both discriminative and generalizable, leading to severe performance drops in unseen scenarios. We address this challenge by introducing a heterogeneous graph that enables refining both cross-modal features and correspondences within a unified architecture. The proposed graph represents a mapping between segmented 2D and 3D regions, which enhances cross-modal feature interaction and thus improves feature discriminability. In addition, modeling the consistency among vertices and edges within the graph enables pruning of unreliable correspondences. Building on these insights, we propose a heterogeneous graph embedded I2P registration method, termed Hg-I2P. It learns a heterogeneous graph by mining multi-path feature relationships, adapts features under the guidance of heterogeneous edges, and prunes correspondences using graph-based projection consistency. Experiments on six indoor and outdoor benchmarks under cross-domain setups demonstrate that Hg-I2P significantly outperforms existing methods in both generalization and accuracy. Code is released on https://github.com/anpei96/hg-i2p-demo.
DriveFine: Refining-Augmented Masked Diffusion VLA for Precise and Robust Driving
Feb 16, 2026Vision-Language-Action (VLA) models for autonomous driving increasingly adopt generative planners trained with imitation learning followed by reinforcement learning. Diffusion-based planners suffer from modality alignment difficulties, low training efficiency, and limited generalization. Token-based planners are plagued by cumulative causal errors and irreversible decoding. In summary, the two dominant paradigms exhibit complementary strengths and weaknesses. In this paper, we propose DriveFine, a masked diffusion VLA model that combines flexible decoding with self-correction capabilities. In particular, we design a novel plug-and-play block-MoE, which seamlessly injects a refinement expert on top of the generation expert. By enabling explicit expert selection during inference and gradient blocking during training, the two experts are fully decoupled, preserving the foundational capabilities and generic patterns of the pretrained weights, which highlights the flexibility and extensibility of the block-MoE design. Furthermore, we design a hybrid reinforcement learning strategy that encourages effective exploration of refinement expert while maintaining training stability. Extensive experiments on NAVSIM v1, v2, and Navhard benchmarks demonstrate that DriveFine exhibits strong efficacy and robustness. The code will be released at https://github.com/MSunDYY/DriveFine.
AERO: Autonomous Evolutionary Reasoning Optimization via Endogenous Dual-Loop Feedback
Feb 03, 2026Large Language Models (LLMs) have achieved significant success in complex reasoning but remain bottlenecked by reliance on expert-annotated data and external verifiers. While existing self-evolution paradigms aim to bypass these constraints, they often fail to identify the optimal learning zone and risk reinforcing collective hallucinations and incorrect priors through flawed internal feedback. To address these challenges, we propose \underline{A}utonomous \underline{E}volutionary \underline{R}easoning \underline{O}ptimization (AERO), an unsupervised framework that achieves autonomous reasoning evolution by internalizing self-questioning, answering, and criticism within a synergistic dual-loop system. Inspired by the \textit{Zone of Proximal Development (ZPD)} theory, AERO utilizes entropy-based positioning to target the ``solvability gap'' and employs Independent Counterfactual Correction for robust verification. Furthermore, we introduce a Staggered Training Strategy to synchronize capability growth across functional roles and prevent curriculum collapse. Extensive evaluations across nine benchmarks spanning three domains demonstrate that AERO achieves average performance improvements of 4.57\% on Qwen3-4B-Base and 5.10\% on Qwen3-8B-Base, outperforming competitive baselines. Code is available at https://github.com/mira-ai-lab/AERO.
Reducing False Positives in Static Bug Detection with LLMs: An Empirical Study in Industry
Jan 26, 2026Static analysis tools (SATs) are widely adopted in both academia and industry for improving software quality, yet their practical use is often hindered by high false positive rates, especially in large-scale enterprise systems. These false alarms demand substantial manual inspection, creating severe inefficiencies in industrial code review. While recent work has demonstrated the potential of large language models (LLMs) for false alarm reduction on open-source benchmarks, their effectiveness in real-world enterprise settings remains unclear. To bridge this gap, we conduct the first comprehensive empirical study of diverse LLM-based false alarm reduction techniques in an industrial context at Tencent, one of the largest IT companies in China. Using data from Tencent's enterprise-customized SAT on its large-scale Advertising and Marketing Services software, we construct a dataset of 433 alarms (328 false positives, 105 true positives) covering three common bug types. Through interviewing developers and analyzing the data, our results highlight the prevalence of false positives, which wastes substantial manual effort (e.g., 10-20 minutes of manual inspection per alarm). Meanwhile, our results show the huge potential of LLMs for reducing false alarms in industrial settings (e.g., hybrid techniques of LLM and static analysis eliminate 94-98% of false positives with high recall). Furthermore, LLM-based techniques are cost-effective, with per-alarm costs as low as 2.1-109.5 seconds and $0.0011-$0.12, representing orders-of-magnitude savings compared to manual review. Finally, our case analysis further identifies key limitations of LLM-based false alarm reduction in industrial settings.
MoCha:End-to-End Video Character Replacement without Structural Guidance
Jan 14, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
End-to-End Video Character Replacement without Structural Guidance
Jan 13, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
SparseOccVLA: Bridging Occupancy and Vision-Language Models via Sparse Queries for Unified 4D Scene Understanding and Planning
Jan 10, 2026In autonomous driving, Vision Language Models (VLMs) excel at high-level reasoning , whereas semantic occupancy provides fine-grained details. Despite significant progress in individual fields, there is still no method that can effectively integrate both paradigms. Conventional VLMs struggle with token explosion and limited spatiotemporal reasoning, while semantic occupancy provides a unified, explicit spatial representation but is too dense to integrate efficiently with VLMs. To address these challenges and bridge the gap between VLMs and occupancy, we propose SparseOccVLA, a novel vision-language-action model that unifies scene understanding, occupancy forecasting, and trajectory planning powered by sparse occupancy queries. Starting with a lightweight Sparse Occupancy Encoder, SparseOccVLA generates compact yet highly informative sparse occupancy queries that serve as the single bridge between vision and language. These queries are aligned into the language space and reasoned by the LLM for unified scene understanding and future occupancy forecasting. Furthermore, we introduce an LLM-guided Anchor-Diffusion Planner featuring decoupled anchor scoring and denoising, as well as cross-model trajectory-condition fusion. SparseOccVLA achieves a 7% relative improvement in CIDEr over the state-of-the-art on OmniDrive-nuScenes, a 0.5 increase in mIoU score on Occ3D-nuScenes, and sets state-of-the-art open-loop planning metric on nuScenes benchmark, demonstrating its strong holistic capability.
Positioning Using LEO Satellite Communication Signals Under Orbital Errors
Nov 08, 2025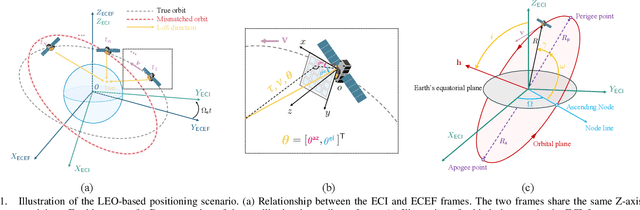
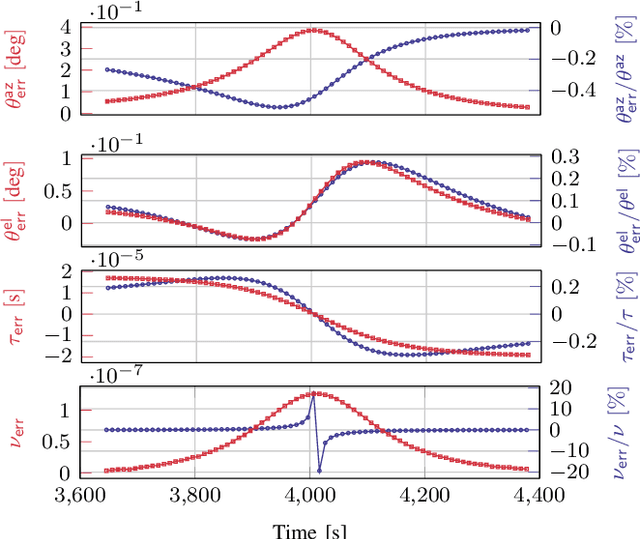
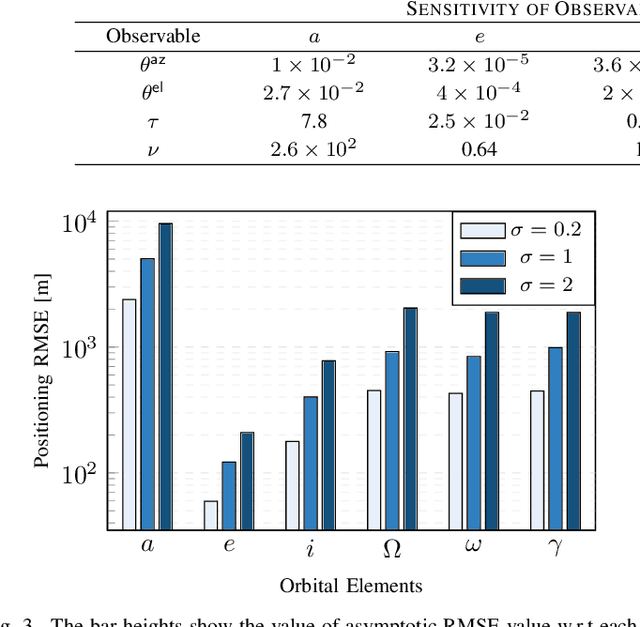
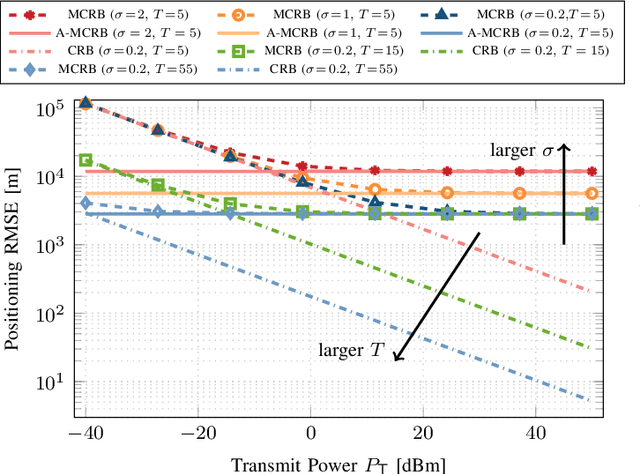
Low Earth orbit (LEO) satellites offer a promising alternative to global navigation satellite systems for precise positioning; however, their relatively low altitudes make them more susceptible to orbital perturbations, which in turn degrade positioning accuracy. In this work, we study LEO-based positioning under orbital errors within a signal-of-opportunity framework. First, we introduce a LEO orbit model that accounts for Earth's non-sphericity and derive a wideband communication model that captures fast- and slow-time Doppler effects and multipath propagation. Subsequently, we perform a misspecified Cramér-Rao bound (MCRB) analysis to evaluate the impact of orbital errors on positioning performance. Then, we propose a two-stage positioning method starting with a (i) MCRB-based weighted orbit calibration, followed by (ii) least-squares user positioning using the corrected orbit. The MCRB analysis indicates that orbital errors can induce kilometer-level position biases. Extensive simulations show that the proposed estimator can considerably enhance the positioning accuracy relative to the orbit-mismatched baseline, yielding errors on the order of a few meters.
SDGOCC: Semantic and Depth-Guided Bird's-Eye View Transformation for 3D Multimodal Occupancy Prediction
Jul 22, 2025Multimodal 3D occupancy prediction has garnered significant attention for its potential in autonomous driving. However, most existing approaches are single-modality: camera-based methods lack depth information, while LiDAR-based methods struggle with occlusions. Current lightweight methods primarily rely on the Lift-Splat-Shoot (LSS) pipeline, which suffers from inaccurate depth estimation and fails to fully exploit the geometric and semantic information of 3D LiDAR points. Therefore, we propose a novel multimodal occupancy prediction network called SDG-OCC, which incorporates a joint semantic and depth-guided view transformation coupled with a fusion-to-occupancy-driven active distillation. The enhanced view transformation constructs accurate depth distributions by integrating pixel semantics and co-point depth through diffusion and bilinear discretization. The fusion-to-occupancy-driven active distillation extracts rich semantic information from multimodal data and selectively transfers knowledge to image features based on LiDAR-identified regions. Finally, for optimal performance, we introduce SDG-Fusion, which uses fusion alone, and SDG-KL, which integrates both fusion and distillation for faster inference. Our method achieves state-of-the-art (SOTA) performance with real-time processing on the Occ3D-nuScenes dataset and shows comparable performance on the more challenging SurroundOcc-nuScenes dataset, demonstrating its effectiveness and robustness. The code will be released at https://github.com/DzpLab/SDGOCC.
ChartSketcher: Reasoning with Multimodal Feedback and Reflection for Chart Understanding
May 25, 2025Charts are high-density visualization carriers for complex data, serving as a crucial medium for information extraction and analysis. Automated chart understanding poses significant challenges to existing multimodal large language models (MLLMs) due to the need for precise and complex visual reasoning. Current step-by-step reasoning models primarily focus on text-based logical reasoning for chart understanding. However, they struggle to refine or correct their reasoning when errors stem from flawed visual understanding, as they lack the ability to leverage multimodal interaction for deeper comprehension. Inspired by human cognitive behavior, we propose ChartSketcher, a multimodal feedback-driven step-by-step reasoning method designed to address these limitations. ChartSketcher is a chart understanding model that employs Sketch-CoT, enabling MLLMs to annotate intermediate reasoning steps directly onto charts using a programmatic sketching library, iteratively feeding these visual annotations back into the reasoning process. This mechanism enables the model to visually ground its reasoning and refine its understanding over multiple steps. We employ a two-stage training strategy: a cold start phase to learn sketch-based reasoning patterns, followed by off-policy reinforcement learning to enhance reflection and generalization. Experiments demonstrate that ChartSketcher achieves promising performance on chart understanding benchmarks and general vision tasks, providing an interactive and interpretable approach to chart comprehension.