 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDGOCC: Semantic and Depth-Guided Bird's-Eye View Transformation for 3D Multimodal Occupancy Prediction
Jul 22, 2025Multimodal 3D occupancy prediction has garnered significant attention for its potential in autonomous driving. However, most existing approaches are single-modality: camera-based methods lack depth information, while LiDAR-based methods struggle with occlusions. Current lightweight methods primarily rely on the Lift-Splat-Shoot (LSS) pipeline, which suffers from inaccurate depth estimation and fails to fully exploit the geometric and semantic information of 3D LiDAR points. Therefore, we propose a novel multimodal occupancy prediction network called SDG-OCC, which incorporates a joint semantic and depth-guided view transformation coupled with a fusion-to-occupancy-driven active distillation. The enhanced view transformation constructs accurate depth distributions by integrating pixel semantics and co-point depth through diffusion and bilinear discretization. The fusion-to-occupancy-driven active distillation extracts rich semantic information from multimodal data and selectively transfers knowledge to image features based on LiDAR-identified regions. Finally, for optimal performance, we introduce SDG-Fusion, which uses fusion alone, and SDG-KL, which integrates both fusion and distillation for faster inference. Our method achieves state-of-the-art (SOTA) performance with real-time processing on the Occ3D-nuScenes dataset and shows comparable performance on the more challenging SurroundOcc-nuScenes dataset, demonstrating its effectiveness and robustness. The code will be released at https://github.com/DzpLab/SDGOCC.
Multimodal Point Cloud Semantic Segmentation With Virtual Point Enhancement
Apr 02, 2025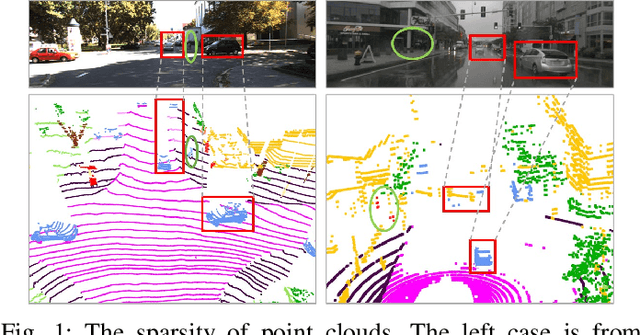
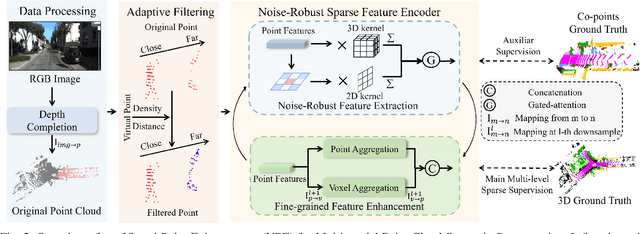

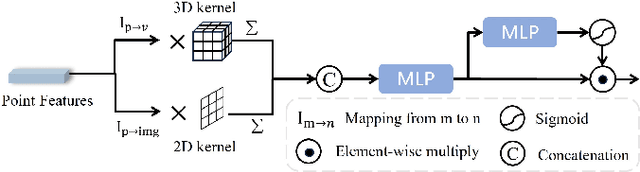
LiDAR-based 3D point cloud recognition has been proven beneficial in various applications. However, the sparsity and varying density pose a significant challenge in capturing intricate details of objects, particularly for medium-range and small targets. Therefore, we propose a multi-modal point cloud semantic segmentation method based on Virtual Point Enhancement (VPE), which integrates virtual points generated from images to address these issues. These virtual points are dense but noisy, and directly incorporating them can increase computational burden and degrade performance. Therefore, we introduce a spatial difference-driven adaptive filtering module that selectively extracts valuable pseudo points from these virtual points based on density and distance, enhancing the density of medium-range targets. Subsequently, we propose a noise-robust sparse feature encoder that incorporates noise-robust feature extraction and fine-grained feature enhancement. Noise-robust feature extraction exploits the 2D image space to reduce the impact of noisy points, while fine-grained feature enhancement boosts sparse geometric features through inner-voxel neighborhood point aggregation and downsampled voxel aggregation. The results on the SemanticKITTI and nuScenes, two large-scale benchmark data sets, have validated effectiveness, significantly improving 2.89\% mIoU with the introduction of 7.7\% virtual points on nuScenes.
Dual-Domain Homogeneous Fusion with Cross-Modal Mamba and Progressive Decoder for 3D Object Detection
Mar 12, 2025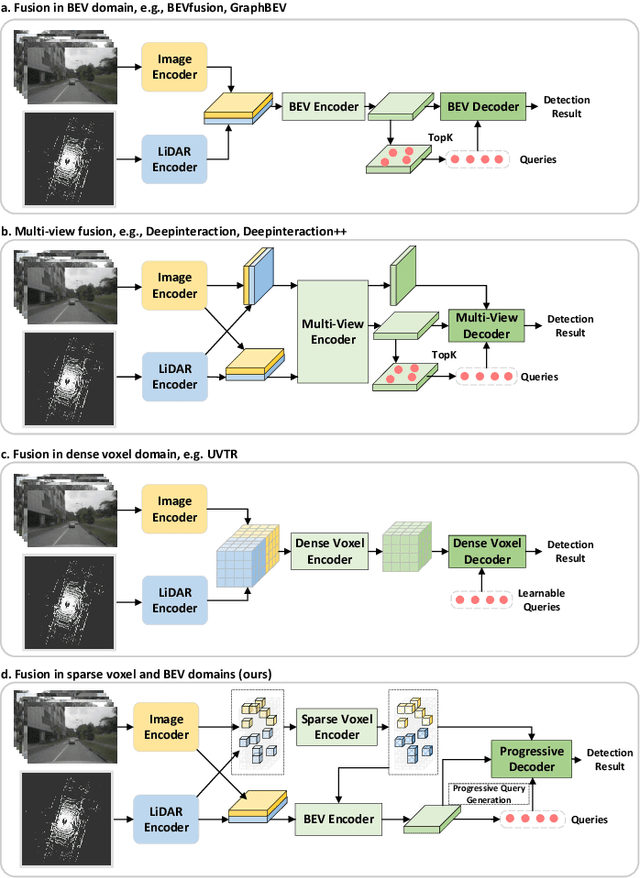
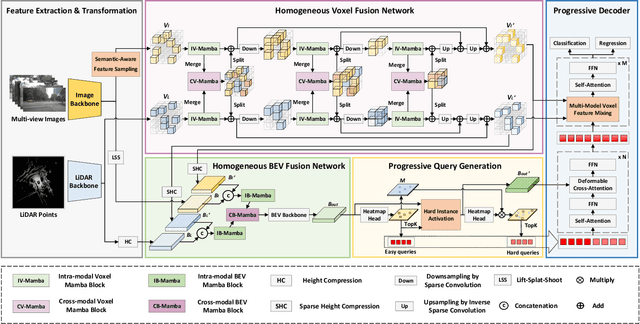
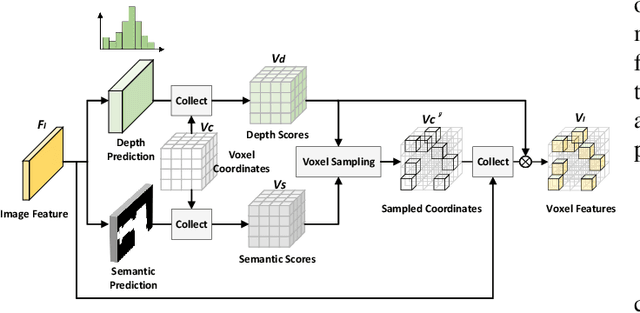
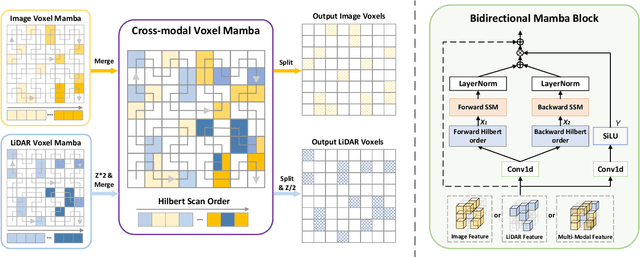
Fusing LiDAR point cloud features and image features in a homogeneous BEV space has been widely adopted for 3D object detection in autonomous driving. However, such methods are limited by the excessive compression of multi-modal features. While some works explore feature fusion in dense voxel spaces, they suffer from high computational costs and inefficiencies in query generation. To address these limitations, we propose a Dual-Domain Homogeneous Fusion network (DDHFusion), which leverages the complementary advantages of both BEV and voxel domains while mitigating their respective drawbacks. Specifically, we first transform image features into BEV and sparse voxel spaces using LSS and our proposed semantic-aware feature sampling module which can significantly reduces computational overhead by filtering unimportant voxels. For feature encoding, we design two networks for BEV and voxel feature fusion, incorporating novel cross-modal voxel and BEV Mamba blocks to resolve feature misalignment and enable efficient yet comprehensive scene perception. The output voxel features are injected into the BEV space to compensate for the loss of 3D details caused by height compression. For feature decoding, a progressive query generation module is implemented in the BEV domain to alleviate false negatives during query selection caused by feature compression and small object sizes. Finally, a progressive decoder can sequentially aggregate not only context-rich BEV features but also geometry-aware voxel features, ensuring more precise confidence prediction and bounding box regression. On the NuScenes dataset, DDHfusion achieves state-of-the-art performance, and further experiments demonstrate its superiority over other homogeneous fusion methods.
Context-Aware Data Augmentation for LIDAR 3D Object Detection
Nov 20, 2022



For 3D object detection, labeling lidar point cloud is difficult, so data augmentation is an important module to make full use of precious annotated data. As a widely used data augmentation method, GT-sample effectively improves detection performance by inserting groundtruths into the lidar frame during training. However, these samples are often placed in unreasonable areas, which misleads model to learn the wrong context information between targets and backgrounds. To address this problem, in this paper, we propose a context-aware data augmentation method (CA-aug) , which ensures the reasonable placement of inserted objects by calculating the "Validspace" of the lidar point cloud. CA-aug is lightweight and compatible with other augmentation methods. Compared with the GT-sample and the similar method in Lidar-aug(SOTA), it brings higher accuracy to the existing detectors. We also present an in-depth study of augmentation methods for the range-view-based(RV-based) models and find that CA-aug can fully exploit the potential of RV-based networks. The experiment on KITTI val split shows that CA-aug can improve the mAP of the test model by 8%.