 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR-Merge: Subspace Signal Routing for Training-Free LoRA Merging in Diffusion Models
Jun 09, 2026Low-Rank Adaptation (LoRA) merging can efficiently combine diverse generative capabilities from multiple trained LoRAs for a diffusion model. However, existing LoRA merging techniques often suffer from severe parameter interference, causing destructive collisions in the shared parameter space. To address this, we propose Subspace Signal Routing (SSR), which resolves interference by routing internal signals instead of performing parameter-space merge. Specifically, SSR first constructs a unified subspace by concatenating candidate LoRAs along the rank dimension. Next, SSR employs an inverse correlation matrix to decorrelate mixed signals within this space. Finally, a directional guide matrix steers these purified signals into their respective task-specific subspaces. We provide a rigorous theoretical analysis proving that SSR aligns with the Ordinary Least Squares (OLS) solution, thereby ensuring mathematical optimality. We utilize the additivity of sufficient statistics to design a streaming algorithm. This enables on-the-fly updates that significantly reduce memory overhead and computation time. Extensive experiments validate that SSR significantly outperforms state-of-the-art methods while maintaining comparable efficiency. Code is available at https://github.com/nagara214/SSR-Merge.
HDRFace: Rethinking Face Restoration with High-Dimensional Representation
May 14, 2026Face restoration under complex degradations still remains an ill-posed inverse problem due to severe information loss. Although diffusion models benefit from strong generative priors, most methods still condition only on low-quality inputs, making it difficult to recover identity-critical details under heavy degradations. In this work, we propose HDRFace, a High-Dimensional Representation conditioned Face restoration framework that injects semantically rich priors into the conditional flow without modifying the generative backbone. Our pipeline first obtains a structurally reliable intermediate restoration with an off-the-shelf restorer, then uses a pretrained high-dimensional feature encoder to extract fine-grained facial representations from both the low-quality input and the intermediate result, and injects them as additional conditions for generation. We further introduce SDFM, a Structure-Detail aware adaptive Fusion Mechanism that emphasizes global constraints during structure modeling and strengthens representation guidance during detail synthesis, balancing structural consistency and detail fidelity. To validate the generalization ability of our method, we implement the proposed framework on two generative models, SD V2.1-base and Qwen-Image, and consistently observe stable and coherent performance gains across different architectures.
Data Fusion with Distributional Equivalence Test-then-pool
Mar 12, 2026Randomized controlled trials (RCTs) are the gold standard for causal inference, yet practical constraints often limit the size of the concurrent control arm. Borrowing control data from previous trials offers a potential efficiency gain, but naive borrowing can induce bias when historical and current populations differ. Existing test-then-pool (TTP) procedures address this concern by testing for equality of control outcomes between historical and concurrent trials before borrowing; however, standard implementations may suffer from reduced power or inadequate control of the Type-I error rate. We develop a new TTP framework that fuses control arms while rigorously controlling the Type-I error rate of the final treatment effect test. Our method employs kernel two-sample testing via maximum mean discrepancy (MMD) to capture distributional differences, and equivalence testing to avoid introducing uncontrolled bias, providing a more flexible and informative criterion for pooling. To ensure valid inference, we introduce partial bootstrap and partial permutation procedures for approximating null distributions in the presence of heterogeneous controls. We further establish the overall validity and consistency. We provide empirical studies demonstrating that the proposed approach achieves higher power than standard TTP methods while maintaining nominal error control, highlighting its value as a principled tool for leveraging historical controls in modern clinical trials.
Kernel Tests of Equivalence
Mar 11, 2026We propose novel kernel-based tests for assessing the equivalence between distributions. Traditional goodness-of-fit testing is inappropriate for concluding the absence of distributional differences, because failure to reject the null hypothesis may simply be a result of lack of test power, also known as the Type-II error. This motivates \emph{equivalence testing}, which aims to assess the \emph{absence} of a statistically meaningful effect under controlled error rates. However, existing equivalence tests are either limited to parametric distributions or focus only on specific moments rather than the full distribution. We address these limitations using two kernel-based statistical discrepancies: the \emph{kernel Stein discrepancy} and the \emph{Maximum Mean Discrepancy}. The null hypothesis of our proposed tests assumes the candidate distribution differs from the nominal distribution by at least a pre-defined margin, which is measured by these discrepancies. We propose two approaches for computing the critical values of the tests, one using an asymptotic normality approximation, and another based on bootstrapping. Numerical experiments are conducted to assess the performance of these tests.
GarmentPainter: Efficient 3D Garment Texture Synthesis with Character-Guided Diffusion Model
Mar 09, 2026Generating high-fidelity, 3D-consistent garment textures remains a challenging problem due to the inherent complexities of garment structures and the stringent requirement for detailed, globally consistent texture synthesis. Existing approaches either rely on 2D-based diffusion models, which inherently struggle with 3D consistency, require expensive multi-step optimization or depend on strict spatial alignment between 2D reference images and 3D meshes, which limits their flexibility and scalability. In this work, we introduce GarmentPainter, a simple yet efficient framework for synthesizing high-quality, 3D-aware garment textures in UV space. Our method leverages a UV position map as the 3D structural guidance, ensuring texture consistency across the garment surface during texture generation. To enhance control and adaptability, we introduce a type selection module, enabling fine-grained texture generation for specific garment components based on a character reference image, without requiring alignment between the reference image and the 3D mesh. GarmentPainter efficiently integrates all guidance signals into the input of a diffusion model in a spatially aligned manner, without modifying the underlying UNet architecture. Extensive experiments demonstrate that GarmentPainter achieves state-of-the-art performance in terms of visual fidelity, 3D consistency, and computational efficiency, outperforming existing methods in both qualitative and quantitative evaluations.
BeautyGRPO: Aesthetic Alignment for Face Retouching via Dynamic Path Guidance and Fine-Grained Preference Modeling
Mar 01, 2026Face retouching requires removing subtle imperfections while preserving unique facial identity features, in order to enhance overall aesthetic appeal. However, existing methods suffer from a fundamental trade-off. Supervised learning on labeled data is constrained to pixel-level label mimicry, failing to capture complex subjective human aesthetic preferences. Conversely, while online reinforcement learning (RL) excels at preference alignment, its stochastic exploration paradigm conflicts with the high-fidelity demands of face retouching and often introduces noticeable noise artifacts due to accumulated stochastic drift. To address these limitations, we propose BeautyGRPO, a reinforcement learning framework that aligns face retouching with human aesthetic preferences. We construct FRPref-10K, a fine-grained preference dataset covering five key retouching dimensions, and train a specialized reward model capable of evaluating subtle perceptual differences. To reconcile exploration and fidelity, we introduce Dynamic Path Guidance (DPG). DPG stabilizes the stochastic sampling trajectory by dynamically computing an anchor-based ODE path and replanning a guided trajectory at each sampling timestep, effectively correcting stochastic drift while maintaining controlled exploration. Extensive experiments show that BeautyGRPO outperforms both specialized face retouching methods and general image editing models, achieving superior texture quality, more accurate blemish removal, and overall results that better align with human aesthetic preferences.
Bending the Scaling Law Curve in Large-Scale Recommendation Systems
Feb 19, 2026Learning from user interaction history through sequential models has become a cornerstone of large-scale recommender systems. Recent advances in large language models have revealed promising scaling laws, sparking a surge of research into long-sequence modeling and deeper architectures for recommendation tasks. However, many recent approaches rely heavily on cross-attention mechanisms to address the quadratic computational bottleneck in sequential modeling, which can limit the representational power gained from self-attention. We present ULTRA-HSTU, a novel sequential recommendation model developed through end-to-end model and system co-design. By innovating in the design of input sequences, sparse attention mechanisms, and model topology, ULTRA-HSTU achieves substantial improvements in both model quality and efficiency. Comprehensive benchmarking demonstrates that ULTRA-HSTU achieves remarkable scaling efficiency gains -- over 5x faster training scaling and 21x faster inference scaling compared to conventional models -- while delivering superior recommendation quality. Our solution is fully deployed at scale, serving billions of users daily and driving significant 4% to 8% consumption and engagement improvements in real-world production environments.
LEO Constellations as a Decentralized GNSS Network: Optimizing PNT Corrections in Space
Dec 24, 2025
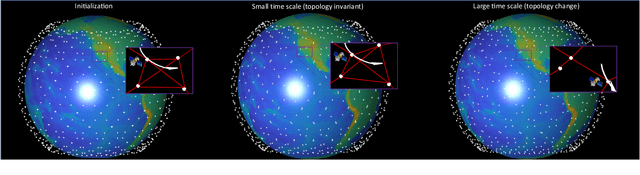
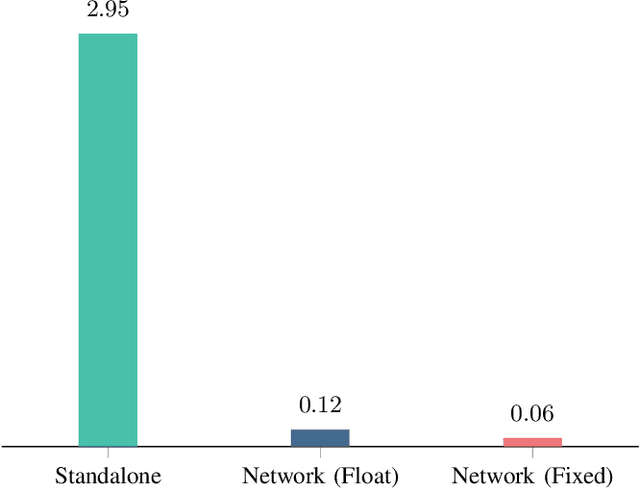
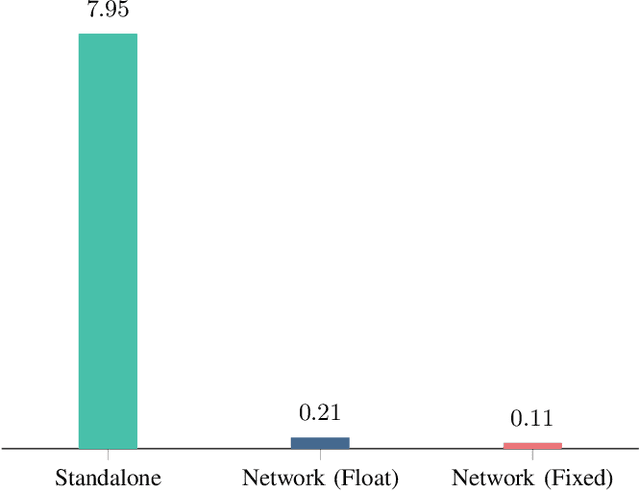
With the rapid expansion of low Earth orbit (LEO) constellations, thousands of satellites are now in operation, many equipped with onboard GNSS receivers capable of continuous orbit determination and time synchronization. This development is creating an unprecedented spaceborne GNSS network, offering new opportunities for network-driven precise LEO orbit and clock estimation. Yet, current onboard GNSS processing is largely standalone and often insufficient for high-precision applications, while centralized fusion is challenging due to computational bottlenecks and the lack of in-orbit infrastructure. In this work, we report a decentralized GNSS network over large-scale LEO constellations, where each satellite processes its own measurements while exchanging compact information with neighboring nodes to enable precise orbit and time determination. We model the moving constellation as a dynamic graph and tailor a momentum-accelerated gradient tracking (GT) method to ensure steady convergence despite topology changes. Numerical simulations with constellations containing hundreds of satellites show that the proposed method matches the accuracy of an ideal centralized benchmark, while substantially reducing communication burdens. Ultimately, this framework supports the development of autonomous and self-organizing space systems, enabling high-precision navigation with reduced dependence on continuous ground contact.
Decentralized GNSS at Global Scale via Graph-Aware Diffusion Adaptation
Dec 23, 2025



Network-based Global Navigation Satellite Systems (GNSS) underpin critical infrastructure and autonomous systems, yet typically rely on centralized processing hubs that limit scalability, resilience, and latency. Here we report a global-scale, decentralized GNSS architecture spanning hundreds of ground stations. By modeling the receiver network as a time-varying graph, we employ a deep linear neural network approach to learn topology-aware mixing schedules that optimize information exchange. This enables a gradient tracking diffusion strategy wherein stations execute local inference and exchange succinct messages to achieve two concurrent objectives: centimeter-level self-localization and network-wide consensus on satellite correction products. The consensus products are broadcast to user receivers as corrections, supporting precise point positioning (PPP) and precise point positioning-real-time kinematic (PPP-RTK). Numerical results demonstrate that our method matches the accuracy of centralized baselines while significantly outperforming existing decentralized methods in convergence speed and communication overhead. By reframing decentralized GNSS as a networked signal processing problem, our results pave the way for integrating decentralized optimization, consensus-based inference, and graph-aware learning as effective tools in operational satellite navigation.
3One2: One-step Regression Plus One-step Diffusion for One-hot Modulation in Dual-path Video Snapshot Compressive Imaging
Dec 19, 2025Video snapshot compressive imaging (SCI) captures dynamic scene sequences through a two-dimensional (2D) snapshot, fundamentally relying on optical modulation for hardware compression and the corresponding software reconstruction. While mainstream video SCI using random binary modulation has demonstrated success, it inevitably results in temporal aliasing during compression. One-hot modulation, activating only one sub-frame per pixel, provides a promising solution for achieving perfect temporal decoupling, thereby alleviating issues associated with aliasing. However, no algorithms currently exist to fully exploit this potential. To bridge this gap, we propose an algorithm specifically designed for one-hot masks. First, leveraging the decoupling properties of one-hot modulation, we transform the reconstruction task into a generative video inpainting problem and introduce a stochastic differential equation (SDE) of the forward process that aligns with the hardware compression process. Next, we identify limitations of the pure diffusion method for video SCI and propose a novel framework that combines one-step regression initialization with one-step diffusion refinement. Furthermore, to mitigate the spatial degradation caused by one-hot modulation, we implement a dual optical path at the hardware level, utilizing complementary information from another path to enhance the inpainted video. To our knowledge, this is the first work integrating diffusion into video SCI reconstruction. Experiments conducted on synthetic datasets and real scenes demonstrate the effectiveness of our method.