 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb
May 20, 2026Deploying natural language search systems presents a critical cold-start challenge: no real user queries to learn linguistic patterns, and no relevance labels to train ranking models. We present a framework for generating synthetic queries and labels using large language models (LLMs), powering model training and evaluation for Airbnb's natural language search. For query generation, we combine contrastive listing pairs from booking sessions with seed queries from user research to balance realism and diversity, enabling a cold-to-warm start transition as real user data becomes available. For label generation, we introduce contrastive generation that produces topicality labels by construction, and Virtual Judge (VJ) labeling for broader coverage. We compare our approach against a no-seed contrastive baseline and an InPars-style baseline. For query length, the InPars baseline produces verbose queries with KL divergence of 12.03 vs. real users; our seed-guided approach achieves 0.66, a 7.5x improvement. For attribute type distributions, our approach achieves the lowest KL divergence (0.04), outperforming even seed queries (0.09). Experiments show our approach produces harder evaluation examples than the no-seed baseline (79% vs. 97% pairwise accuracy), providing discriminative signal for model improvement. We deploy production pipelines generating synthetic examples daily for embedding-based retrieval and ranking evaluation.
MM-WebAgent: A Hierarchical Multimodal Web Agent for Webpage Generation
Apr 16, 2026The rapid progress of Artificial Intelligence Generated Content (AIGC) tools enables images, videos, and visualizations to be created on demand for webpage design, offering a flexible and increasingly adopted paradigm for modern UI/UX. However, directly integrating such tools into automated webpage generation often leads to style inconsistency and poor global coherence, as elements are generated in isolation. We propose MM-WebAgent, a hierarchical agentic framework for multimodal webpage generation that coordinates AIGC-based element generation through hierarchical planning and iterative self-reflection. MM-WebAgent jointly optimizes global layout, local multimodal content, and their integration, producing coherent and visually consistent webpages. We further introduce a benchmark for multimodal webpage generation and a multi-level evaluation protocol for systematic assessment. Experiments demonstrate that MM-WebAgent outperforms code-generation and agent-based baselines, especially on multimodal element generation and integration. Code & Data: https://aka.ms/mm-webagent.
Collaborative Learning for Unsupervised Multimodal Remote Sensing Image Registration: Integrating Self-Supervision and MIM-Guided Diffusion-Based Image Translation
May 28, 2025The substantial modality-induced variations in radiometric, texture, and structural characteristics pose significant challenges for the accurate registration of multimodal images. While supervised deep learning methods have demonstrated strong performance, they often rely on large-scale annotated datasets, limiting their practical application. Traditional unsupervised methods usually optimize registration by minimizing differences in feature representations, yet often fail to robustly capture geometric discrepancies, particularly under substantial spatial and radiometric variations, thus hindering convergence stability. To address these challenges, we propose a Collaborative Learning framework for Unsupervised Multimodal Image Registration, named CoLReg, which reformulates unsupervised registration learning into a collaborative training paradigm comprising three components: (1) a cross-modal image translation network, MIMGCD, which employs a learnable Maximum Index Map (MIM) guided conditional diffusion model to synthesize modality-consistent image pairs; (2) a self-supervised intermediate registration network which learns to estimate geometric transformations using accurate displacement labels derived from MIMGCD outputs; (3) a distilled cross-modal registration network trained with pseudo-label predicted by the intermediate network. The three networks are jointly optimized through an alternating training strategy wherein each network enhances the performance of the others. This mutual collaboration progressively reduces modality discrepancies, enhances the quality of pseudo-labels, and improves registration accuracy. Extensive experimental results on multiple datasets demonstrate that our ColReg achieves competitive or superior performance compared to state-of-the-art unsupervised approaches and even surpasses several supervised baselines.
Learning Adaptive and Temporally Causal Video Tokenization in a 1D Latent Space
May 22, 2025We propose AdapTok, an adaptive temporal causal video tokenizer that can flexibly allocate tokens for different frames based on video content. AdapTok is equipped with a block-wise masking strategy that randomly drops tail tokens of each block during training, and a block causal scorer to predict the reconstruction quality of video frames using different numbers of tokens. During inference, an adaptive token allocation strategy based on integer linear programming is further proposed to adjust token usage given predicted scores. Such design allows for sample-wise, content-aware, and temporally dynamic token allocation under a controllable overall budget. Extensive experiments for video reconstruction and generation on UCF-101 and Kinetics-600 demonstrate the effectiveness of our approach. Without additional image data, AdapTok consistently improves reconstruction quality and generation performance under different token budgets, allowing for more scalable and token-efficient generative video modeling.
OSDM-MReg: Multimodal Image Registration based One Step Diffusion Model
Apr 08, 2025Multimodal remote sensing image registration aligns images from different sensors for data fusion and analysis. However, current methods often fail to extract modality-invariant features when aligning image pairs with large nonlinear radiometric differences. To address this issues, we propose OSDM-MReg, a novel multimodal image registration framework based image-to-image translation to eliminate the gap of multimodal images. Firstly, we propose a novel one-step unaligned target-guided conditional denoising diffusion probabilistic models(UTGOS-CDDPM)to translate multimodal images into a unified domain. In the inference stage, traditional conditional DDPM generate translated source image by a large number of iterations, which severely slows down the image registration task. To address this issues, we use the unaligned traget image as a condition to promote the generation of low-frequency features of the translated source image. Furthermore, during the training stage, we add the inverse process of directly predicting the translated image to ensure that the translated source image can be generated in one step during the testing stage. Additionally, to supervised the detail features of translated source image, we propose a new perceptual loss that focuses on the high-frequency feature differences between the translated and ground-truth images. Finally, a multimodal multiscale image registration network (MM-Reg) fuse the multimodal feature of the unimodal images and multimodal images by proposed multimodal feature fusion strategy. Experiments demonstrate superior accuracy and efficiency across various multimodal registration tasks, particularly for SAR-optical image pairs.
Video Domain Incremental Learning for Human Action Recognition in Home Environments
Dec 22, 2024It is significantly challenging to recognize daily human actions in homes due to the diversity and dynamic changes in unconstrained home environments. It spurs the need to continually adapt to various users and scenes. Fine-tuning current video understanding models on newly encountered domains often leads to catastrophic forgetting, where the models lose their ability to perform well on previously learned scenarios. To address this issue, we formalize the problem of Video Domain Incremental Learning (VDIL), which enables models to learn continually from different domains while maintaining a fixed set of action classes. Existing continual learning research primarily focuses on class-incremental learning, while the domain incremental learning has been largely overlooked in video understanding. In this work, we introduce a novel benchmark of domain incremental human action recognition for unconstrained home environments. We design three domain split types (user, scene, hybrid) to systematically assess the challenges posed by domain shifts in real-world home settings. Furthermore, we propose a baseline learning strategy based on replay and reservoir sampling techniques without domain labels to handle scenarios with limited memory and task agnosticism. Extensive experimental results demonstrate that our simple sampling and replay strategy outperforms most existing continual learning methods across the three proposed benchmarks.
Exploiting Unlabeled Data with Multiple Expert Teachers for Open Vocabulary Aerial Object Detection and Its Orientation Adaptation
Nov 04, 2024



In recent years, aerial object detection has been increasingly pivotal in various earth observation applications. However, current algorithms are limited to detecting a set of pre-defined object categories, demanding sufficient annotated training samples, and fail to detect novel object categories. In this paper, we put forth a novel formulation of the aerial object detection problem, namely open-vocabulary aerial object detection (OVAD), which can detect objects beyond training categories without costly collecting new labeled data. We propose CastDet, a CLIP-activated student-teacher detection framework that serves as the first OVAD detector specifically designed for the challenging aerial scenario, where objects often exhibit weak appearance features and arbitrary orientations. Our framework integrates a robust localization teacher along with several box selection strategies to generate high-quality proposals for novel objects. Additionally, the RemoteCLIP model is adopted as an omniscient teacher, which provides rich knowledge to enhance classification capabilities for novel categories. A dynamic label queue is devised to maintain high-quality pseudo-labels during training. By doing so, the proposed CastDet boosts not only novel object proposals but also classification. Furthermore, we extend our approach from horizontal OVAD to oriented OVAD with tailored algorithm designs to effectively manage bounding box representation and pseudo-label generation. Extensive experiments for both tasks on multiple existing aerial object detection datasets demonstrate the effectiveness of our approach. The code is available at https://github.com/lizzy8587/CastDet.
Transforming Location Retrieval at Airbnb: A Journey from Heuristics to Reinforcement Learning
Aug 23, 2024



The Airbnb search system grapples with many unique challenges as it continues to evolve. We oversee a marketplace that is nuanced by geography, diversity of homes, and guests with a variety of preferences. Crafting an efficient search system that can accommodate diverse guest needs, while showcasing relevant homes lies at the heart of Airbnb's success. Airbnb search has many challenges that parallel other recommendation and search systems but it has a unique information retrieval problem, upstream of ranking, called location retrieval. It requires defining a topological map area that is relevant to the searched query for homes listing retrieval. The purpose of this paper is to demonstrate the methodology, challenges, and impact of building a machine learning based location retrieval product from the ground up. Despite the lack of suitable, prevalent machine learning based approaches, we tackle cold start, generalization, differentiation and algorithmic bias. We detail the efficacy of heuristics, statistics, machine learning, and reinforcement learning approaches to solve these challenges, particularly for systems that are often unexplored by current literature.
CastDet: Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Nov 20, 2023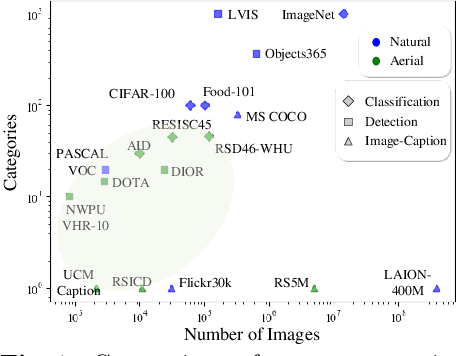
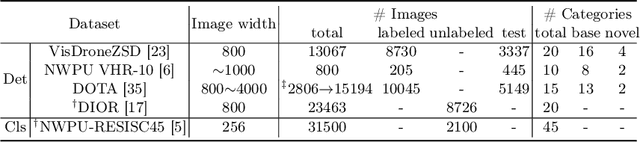

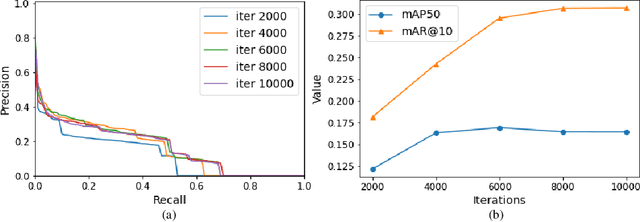
Object detection in aerial images is a pivotal task for various earth observation applications, whereas current algorithms learn to detect only a pre-defined set of object categories demanding sufficient bounding-box annotated training samples and fail to detect novel object categories. In this paper, we consider open-vocabulary object detection (OVD) in aerial images that enables the characterization of new objects beyond training categories on the earth surface without annotating training images for these new categories. The performance of OVD depends on the quality of class-agnostic region proposals and pseudo-labels that can generalize well to novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework within the student-teacher mechanism employs the CLIP model as an extra omniscient teacher of rich knowledge into the student-teacher self-learning process. By doing so, our approach boosts novel object proposals and classification. Furthermore, we design a dynamic label queue technique to maintain high-quality pseudo labels during batch training and mitigate label imbalance. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 40.0 HM (Harmonic Mean), which outperforms previous methods Detic/ViLD by 26.9/21.1 on the VisDroneZSD dataset.
Explainable Analysis of Deep Learning Methods for SAR Image Classification
Apr 14, 2022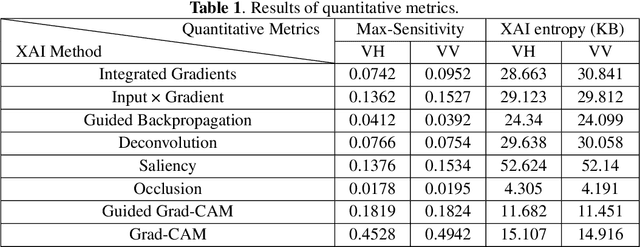
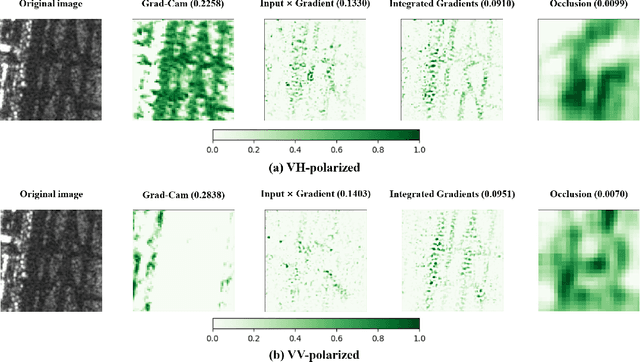
Deep learning methods exhibit outstanding performance in synthetic aperture radar (SAR) image interpretation tasks. However, these are black box models that limit the comprehension of their predictions. Therefore, to meet this challenge, we have utilized explainable artificial intelligence (XAI) methods for the SAR image classification task. Specifically, we trained state-of-the-art convolutional neural networks for each polarization format on OpenSARUrban dataset and then investigate eight explanation methods to analyze the predictions of the CNN classifiers of SAR images. These XAI methods are also evaluated qualitatively and quantitatively which shows that Occlusion achieves the most reliable interpretation performance in terms of Max-Sensitivity but with a low-resolution explanation heatmap. The explanation results provide some insights into the internal mechanism of black-box decisions for SAR image classification.