 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
CastDet: Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Nov 20, 2023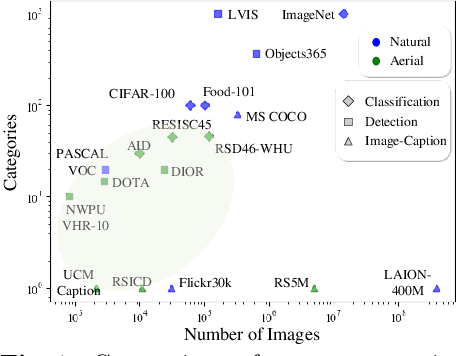
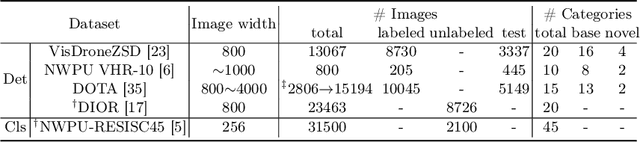

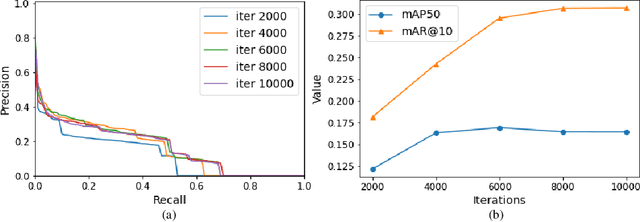
Object detection in aerial images is a pivotal task for various earth observation applications, whereas current algorithms learn to detect only a pre-defined set of object categories demanding sufficient bounding-box annotated training samples and fail to detect novel object categories. In this paper, we consider open-vocabulary object detection (OVD) in aerial images that enables the characterization of new objects beyond training categories on the earth surface without annotating training images for these new categories. The performance of OVD depends on the quality of class-agnostic region proposals and pseudo-labels that can generalize well to novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework within the student-teacher mechanism employs the CLIP model as an extra omniscient teacher of rich knowledge into the student-teacher self-learning process. By doing so, our approach boosts novel object proposals and classification. Furthermore, we design a dynamic label queue technique to maintain high-quality pseudo labels during batch training and mitigate label imbalance. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 40.0 HM (Harmonic Mean), which outperforms previous methods Detic/ViLD by 26.9/21.1 on the VisDroneZSD dataset.