 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-PGA: Robust Physical Adversarial Camouflage Generation via Relightable 3D Gaussian Splatting
Mar 27, 2026Physical adversarial camouflage poses a severe security threat to autonomous driving systems by mapping adversarial textures onto 3D objects. Nevertheless, current methods remain brittle in complex dynamic scenarios, failing to generalize across diverse geometric (e.g., viewing configurations) and radiometric (e.g., dynamic illumination, atmospheric scattering) variations. We attribute this deficiency to two fundamental limitations in simulation and optimization. First, the reliance on coarse, oversimplified simulations (e.g., via CARLA) induces a significant domain gap, confining optimization to a biased feature space. Second, standard strategies targeting average performance result in a rugged loss landscape, leaving the camouflage vulnerable to configuration shifts.To bridge these gaps, we propose the Relightable Physical 3D Gaussian Splatting (3DGS) based Attack framework (R-PGA). Technically, to address the simulation fidelity issue, we leverage 3DGS to ensure photo-realistic reconstruction and augment it with physically disentangled attributes to decouple intrinsic material from lighting. Furthermore, we design a hybrid rendering pipeline that leverages precise Relightable 3DGS for foreground rendering, while employing a pre-trained image translation model to synthesize plausible relighted backgrounds that align with the relighted foreground.To address the optimization robustness issue, we propose the Hard Physical Configuration Mining (HPCM) module, designed to actively mine worst-case physical configurations and suppress their corresponding loss peaks. This strategy not only diminishes the overall loss magnitude but also effectively flattens the rugged loss landscape, ensuring consistent adversarial effectiveness and robustness across varying physical configurations.
Multi-Domain Features Guided Supervised Contrastive Learning for Radar Target Detection
Dec 17, 2024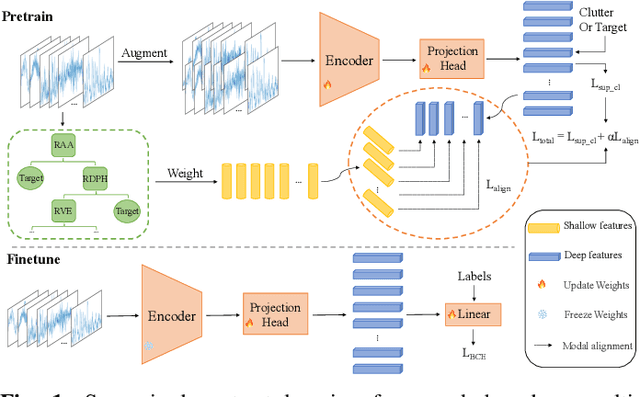
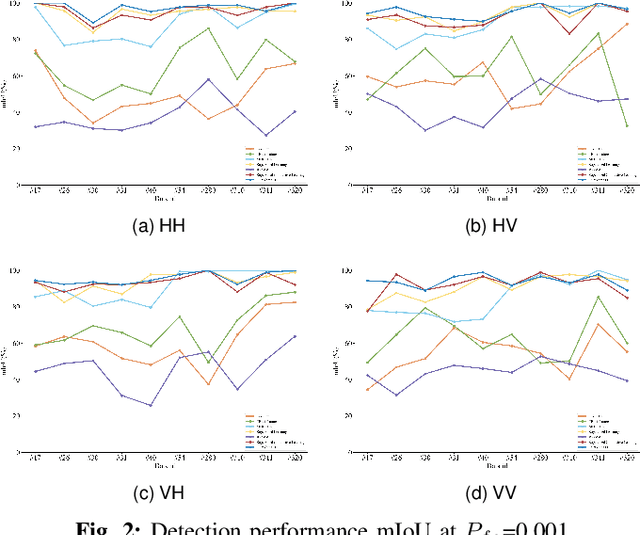
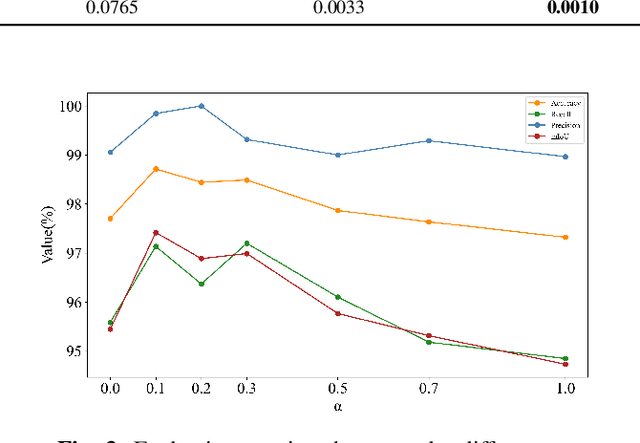
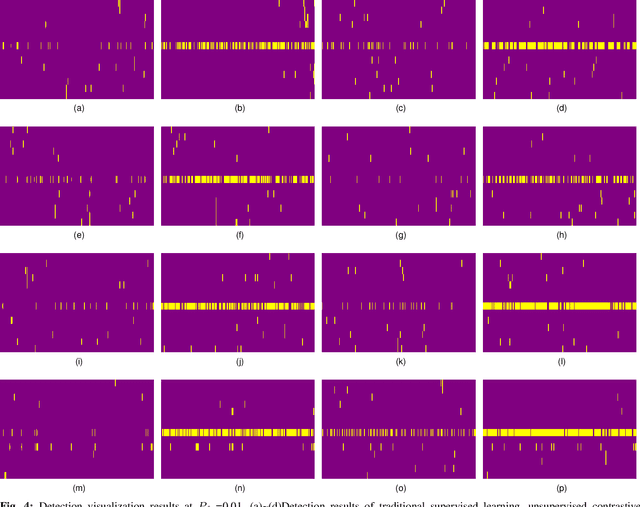
Detecting small targets in sea clutter is challenging due to dynamic maritime conditions. Existing solutions either model sea clutter for detection or extract target features based on clutter-target echo differences, including statistical and deep features. While more common, the latter often excels in controlled scenarios but struggles with robust detection and generalization in diverse environments, limiting practical use. In this letter, we propose a multi-domain features guided supervised contrastive learning (MDFG_SCL) method, which integrates statistical features derived from multi-domain differences with deep features obtained through supervised contrastive learning, thereby capturing both low-level domain-specific variations and high-level semantic information. This comprehensive feature integration enables the model to effectively distinguish between small targets and sea clutter, even under challenging conditions. Experiments conducted on real-world datasets demonstrate that the proposed shallow-to-deep detector not only achieves effective identification of small maritime targets but also maintains superior detection performance across varying sea conditions, outperforming the mainstream unsupervised contrastive learning and supervised contrastive learning methods.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024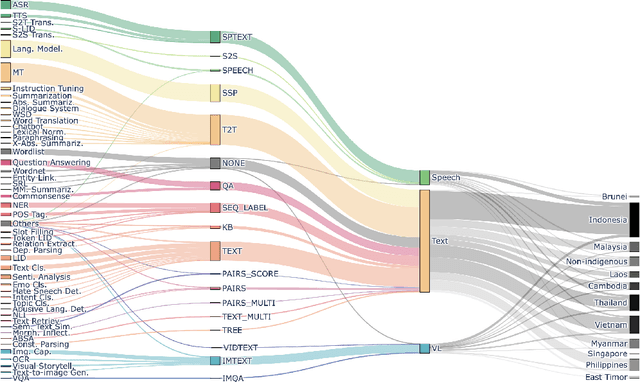
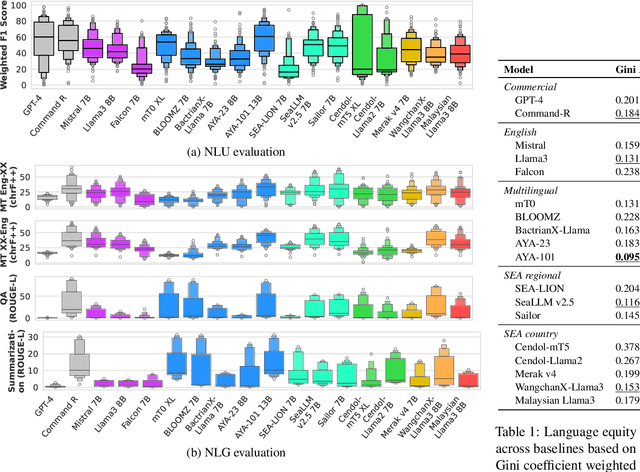
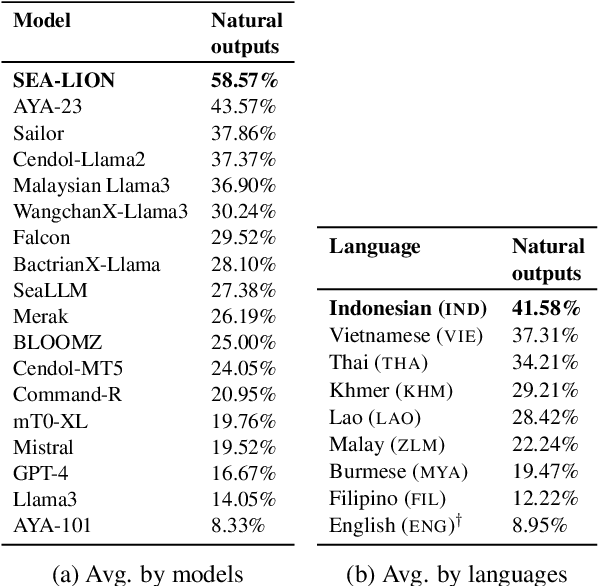
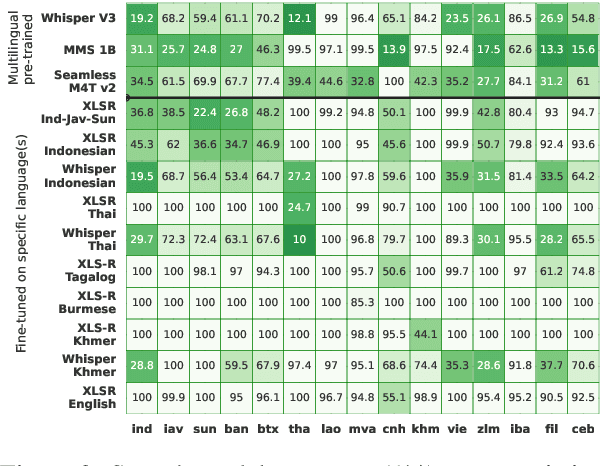
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
CastDet: Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Nov 20, 2023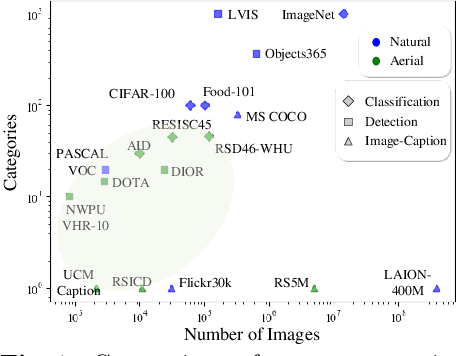
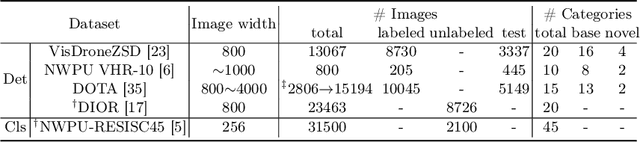

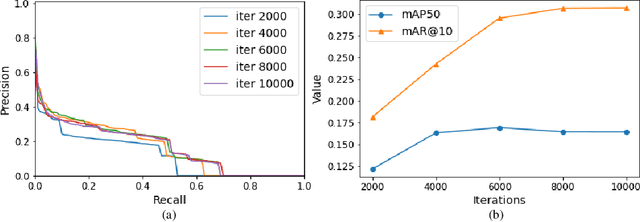
Object detection in aerial images is a pivotal task for various earth observation applications, whereas current algorithms learn to detect only a pre-defined set of object categories demanding sufficient bounding-box annotated training samples and fail to detect novel object categories. In this paper, we consider open-vocabulary object detection (OVD) in aerial images that enables the characterization of new objects beyond training categories on the earth surface without annotating training images for these new categories. The performance of OVD depends on the quality of class-agnostic region proposals and pseudo-labels that can generalize well to novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework within the student-teacher mechanism employs the CLIP model as an extra omniscient teacher of rich knowledge into the student-teacher self-learning process. By doing so, our approach boosts novel object proposals and classification. Furthermore, we design a dynamic label queue technique to maintain high-quality pseudo labels during batch training and mitigate label imbalance. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 40.0 HM (Harmonic Mean), which outperforms previous methods Detic/ViLD by 26.9/21.1 on the VisDroneZSD dataset.
Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT -- A Text-to-SQL Parsing Comparison
Oct 16, 2023



The success of ChatGPT has ignited an AI race, with researchers striving to develop new large language models (LLMs) that can match or surpass the language understanding and generation abilities of commercial ones. In recent times, a number of models have emerged, claiming performance near that of GPT-3.5 or GPT-4 through various instruction-tuning methods. As practitioners of Text-to-SQL parsing, we are grateful for their valuable contributions to open-source research. However, it is important to approach these claims with a sense of scrutiny and ascertain the actual effectiveness of these models. Therefore, we pit six popular large language models against each other, systematically evaluating their Text-to-SQL parsing capability on nine benchmark datasets with five different prompting strategies, covering both zero-shot and few-shot scenarios. Regrettably, the open-sourced models fell significantly short of the performance achieved by closed-source models like GPT-3.5, highlighting the need for further work to bridge the performance gap between these models.
Feature-Less End-to-End Nested Term Extraction
Aug 15, 2019
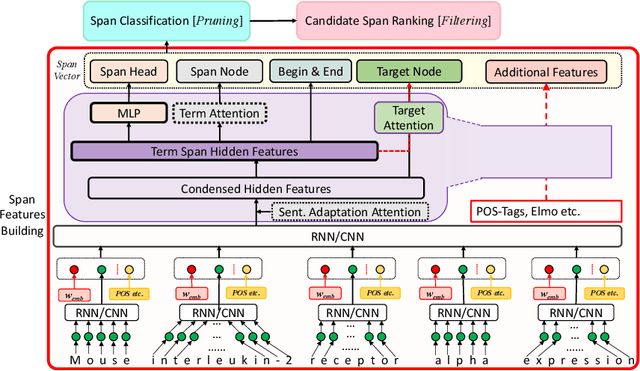

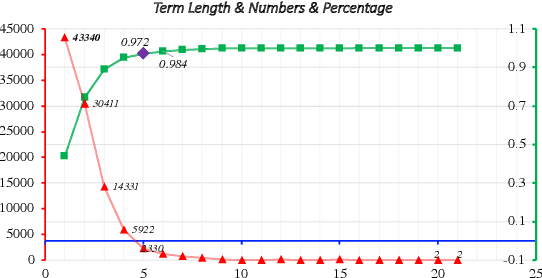
In this paper, we proposed a deep learning-based end-to-end method on the domain specified automatic term extraction (ATE), it considers possible term spans within a fixed length in the sentence and predicts them whether they can be conceptual terms. In comparison with current ATE methods, the model supports nested term extraction and does not crucially need extra (extracted) features. Results show that it can achieve high recall and a comparable precision on term extraction task with inputting segmented raw text.