 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineFT: Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading
Dec 29, 2025Futures are contracts obligating the exchange of an asset at a predetermined date and price, notable for their high leverage and liquidity and, therefore, thrive in the Crypto market. RL has been widely applied in various quantitative tasks. However, most methods focus on the spot and could not be directly applied to the futures market with high leverage because of 2 challenges. First, high leverage amplifies reward fluctuations, making training stochastic and difficult to converge. Second, prior works lacked self-awareness of capability boundaries, exposing them to the risk of significant loss when encountering new market state (e.g.,a black swan event like COVID-19). To tackle these challenges, we propose the Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading (FineFT), a novel three-stage ensemble RL framework with stable training and proper risk management. In stage I, ensemble Q learners are selectively updated by ensemble TD errors to improve convergence. In stage II, we filter the Q-learners based on their profitabilities and train VAEs on market states to identify the capability boundaries of the learners. In stage III, we choose from the filtered ensemble and a conservative policy, guided by trained VAEs, to maintain profitability and mitigate risk with new market states. Through extensive experiments on crypto futures in a high-frequency trading environment with high fidelity and 5x leverage, we demonstrate that FineFT outperforms 12 SOTA baselines in 6 financial metrics, reducing risk by more than 40% while achieving superior profitability compared to the runner-up. Visualization of the selective update mechanism shows that different agents specialize in distinct market dynamics, and ablation studies certify routing with VAEs reduces maximum drawdown effectively, and selective update improves convergence and performance.
Generalization of RLVR Using Causal Reasoning as a Testbed
Dec 23, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for post-training large language models (LLMs) on complex reasoning tasks. Yet, the conditions under which RLVR yields robust generalization remain poorly understood. This paper provides an empirical study of RLVR generalization in the setting of probabilistic inference over causal graphical models. This setting offers two natural axes along which to examine generalization: (i) the level of the probabilistic query -- associational, interventional, or counterfactual -- and (ii) the structural complexity of the query, measured by the size of its relevant subgraph. We construct datasets of causal graphs and queries spanning these difficulty axes and fine-tune Qwen-2.5-Instruct models using RLVR or supervised fine-tuning (SFT). We vary both the model scale (3B-32B) and the query level included in training. We find that RLVR yields stronger within-level and across-level generalization than SFT, but only for specific combinations of model size and training query level. Further analysis shows that RLVR's effectiveness depends on the model's initial reasoning competence. With sufficient initial competence, RLVR improves an LLM's marginalization strategy and reduces errors in intermediate probability calculations, producing substantial accuracy gains, particularly on more complex queries. These findings show that RLVR can improve specific causal reasoning subskills, with its benefits emerging only when the model has sufficient initial competence.
Group-Theoretic Reinforcement Learning of Dynamical Decoupling Sequences
Dec 15, 2025Dynamical decoupling seeks to mitigate phase decoherence in qubits by applying a carefully designed sequence of effectively instantaneous electromagnetic pulses. Although analytic solutions exist for pulse timings that are optimal under specific noise regimes, identifying the optimal timings for a realistic noise spectrum remains challenging. We propose a reinforcement learning (RL)-based method for designing pulse sequences on qubits. Our novel action set enables the RL agent to efficiently navigate this inherently non-convex optimization landscape. The action set, derived from Thompson's group $F$, is applicable to a broad class of sequential decision problems whose states can be represented as bounded sequences. We demonstrate that our RL agent can learn pulse sequences that minimize dephasing without requiring explicit knowledge of the underlying noise spectrum. This work opens the possibility for real-time learning of optimal dynamical decoupling sequences on qubits which are dephasing-limited. The model-free nature of our algorithm suggests that the agent may ultimately learn optimal pulse sequences even in the presence of unmodeled physical effects, such as pulse errors or non-Gaussian noise.
Incorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
Beyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
IFEval-Audio: Benchmarking Instruction-Following Capability in Audio-based Large Language Models
May 22, 2025Large language models (LLMs) have demonstrated strong instruction-following capabilities in text-based tasks. However, this ability often deteriorates in multimodal models after alignment with non-text modalities such as images or audio. While several recent efforts have investigated instruction-following performance in text and vision-language models, instruction-following in audio-based large language models remains largely unexplored. To bridge this gap, we introduce IFEval-Audio, a novel evaluation dataset designed to assess the ability to follow instructions in an audio LLM. IFEval-Audio contains 280 audio-instruction-answer triples across six diverse dimensions: Content, Capitalization, Symbol, List Structure, Length, and Format. Each example pairs an audio input with a text instruction, requiring the model to generate an output that follows a specified structure. We benchmark state-of-the-art audio LLMs on their ability to follow audio-involved instructions. The dataset is released publicly to support future research in this emerging area.
AGI-Elo: How Far Are We From Mastering A Task?
May 19, 2025As the field progresses toward Artificial General Intelligence (AGI), there is a pressing need for more comprehensive and insightful evaluation frameworks that go beyond aggregate performance metrics. This paper introduces a unified rating system that jointly models the difficulty of individual test cases and the competency of AI models (or humans) across vision, language, and action domains. Unlike existing metrics that focus solely on models, our approach allows for fine-grained, difficulty-aware evaluations through competitive interactions between models and tasks, capturing both the long-tail distribution of real-world challenges and the competency gap between current models and full task mastery. We validate the generalizability and robustness of our system through extensive experiments on multiple established datasets and models across distinct AGI domains. The resulting rating distributions offer novel perspectives and interpretable insights into task difficulty, model progression, and the outstanding challenges that remain on the path to achieving full AGI task mastery.
The First WARA Robotics Mobile Manipulation Challenge -- Lessons Learned
May 11, 2025The first WARA Robotics Mobile Manipulation Challenge, held in December 2024 at ABB Corporate Research in V\"aster{\aa}s, Sweden, addressed the automation of task-intensive and repetitive manual labor in laboratory environments - specifically the transport and cleaning of glassware. Designed in collaboration with AstraZeneca, the challenge invited academic teams to develop autonomous robotic systems capable of navigating human-populated lab spaces and performing complex manipulation tasks, such as loading items into industrial dishwashers. This paper presents an overview of the challenge setup, its industrial motivation, and the four distinct approaches proposed by the participating teams. We summarize lessons learned from this edition and propose improvements in design to enable a more effective second iteration to take place in 2025. The initiative bridges an important gap in effective academia-industry collaboration within the domain of autonomous mobile manipulation systems by promoting the development and deployment of applied robotic solutions in real-world laboratory contexts.
Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning
May 07, 2025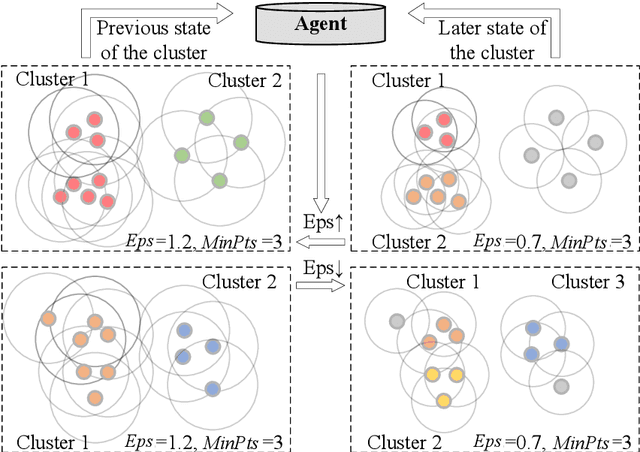

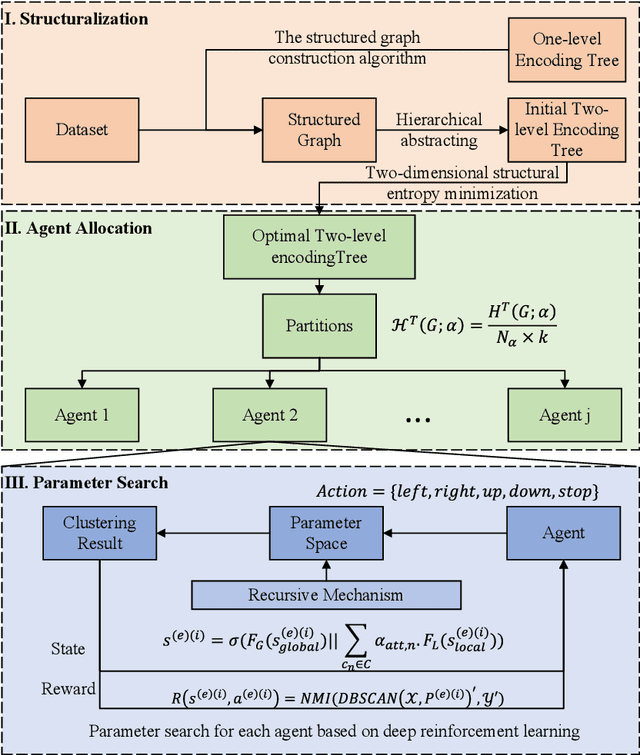

DBSCAN, a well-known density-based clustering algorithm, has gained widespread popularity and usage due to its effectiveness in identifying clusters of arbitrary shapes and handling noisy data. However, it encounters challenges in producing satisfactory cluster results when confronted with datasets of varying density scales, a common scenario in real-world applications. In this paper, we propose a novel Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning cluster framework, namely AR-DBSCAN. First, we model the initial dataset as a two-level encoding tree and categorize the data vertices into distinct density partitions according to the information uncertainty determined in the encoding tree. Each partition is then assigned to an agent to find the best clustering parameters without manual assistance. The allocation is density-adaptive, enabling AR-DBSCAN to effectively handle diverse density distributions within the dataset by utilizing distinct agents for different partitions. Second, a multi-agent deep reinforcement learning guided automatic parameter searching process is designed. The process of adjusting the parameter search direction by perceiving the clustering environment is modeled as a Markov decision process. Using a weakly-supervised reward training policy network, each agent adaptively learns the optimal clustering parameters by interacting with the clusters. Third, a recursive search mechanism adaptable to the data's scale is presented, enabling efficient and controlled exploration of large parameter spaces. Extensive experiments are conducted on nine artificial datasets and a real-world dataset. The results of offline and online tasks show that AR-DBSCAN not only improves clustering accuracy by up to 144.1% and 175.3% in the NMI and ARI metrics, respectively, but also is capable of robustly finding dominant parameters.
Large-scale visual SLAM for in-the-wild videos
Apr 29, 2025Accurate and robust 3D scene reconstruction from casual, in-the-wild videos can significantly simplify robot deployment to new environments. However, reliable camera pose estimation and scene reconstruction from such unconstrained videos remains an open challenge. Existing visual-only SLAM methods perform well on benchmark datasets but struggle with real-world footage which often exhibits uncontrolled motion including rapid rotations and pure forward movements, textureless regions, and dynamic objects. We analyze the limitations of current methods and introduce a robust pipeline designed to improve 3D reconstruction from casual videos. We build upon recent deep visual odometry methods but increase robustness in several ways. Camera intrinsics are automatically recovered from the first few frames using structure-from-motion. Dynamic objects and less-constrained areas are masked with a predictive model. Additionally, we leverage monocular depth estimates to regularize bundle adjustment, mitigating errors in low-parallax situations. Finally, we integrate place recognition and loop closure to reduce long-term drift and refine both intrinsics and pose estimates through global bundle adjustment. We demonstrate large-scale contiguous 3D models from several online videos in various environments. In contrast, baseline methods typically produce locally inconsistent results at several points, producing separate segments or distorted maps. In lieu of ground-truth pose data, we evaluate map consistency, execution time and visual accuracy of re-rendered NeRF models. Our proposed system establishes a new baseline for visual reconstruction from casual uncontrolled videos found online, demonstrating more consistent reconstructions over longer sequences of in-the-wild videos than previously achieved.