 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolating Speaker Identities in Embedding Space for Data Expansion
Aug 26, 2025
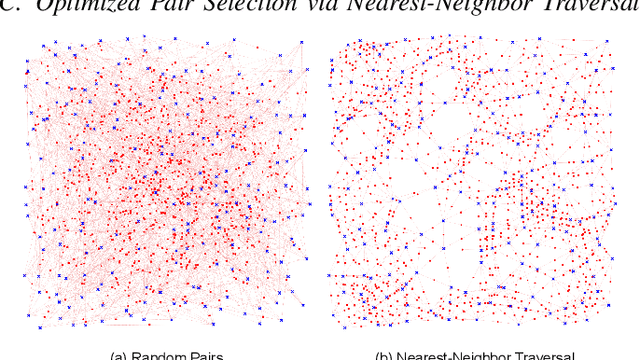
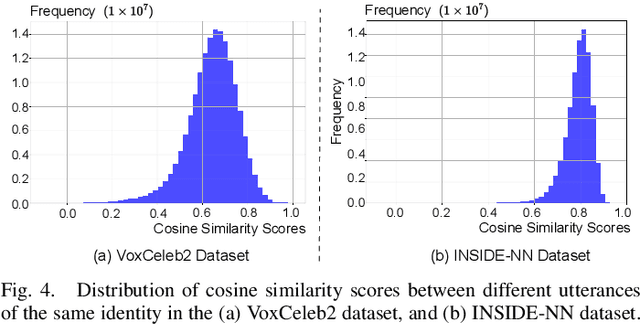
The success of deep learning-based speaker verification systems is largely attributed to access to large-scale and diverse speaker identity data. However, collecting data from more identities is expensive, challenging, and often limited by privacy concerns. To address this limitation, we propose INSIDE (Interpolating Speaker Identities in Embedding Space), a novel data expansion method that synthesizes new speaker identities by interpolating between existing speaker embeddings. Specifically, we select pairs of nearby speaker embeddings from a pretrained speaker embedding space and compute intermediate embeddings using spherical linear interpolation. These interpolated embeddings are then fed to a text-to-speech system to generate corresponding speech waveforms. The resulting data is combined with the original dataset to train downstream models. Experiments show that models trained with INSIDE-expanded data outperform those trained only on real data, achieving 3.06\% to 5.24\% relative improvements. While INSIDE is primarily designed for speaker verification, we also validate its effectiveness on gender classification, where it yields a 13.44\% relative improvement. Moreover, INSIDE is compatible with other augmentation techniques and can serve as a flexible, scalable addition to existing training pipelines.
Incorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
Beyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
Contextual Paralinguistic Data Creation for Multi-Modal Speech-LLM: Data Condensation and Spoken QA Generation
May 19, 2025Current speech-LLMs exhibit limited capability in contextual reasoning alongside paralinguistic understanding, primarily due to the lack of Question-Answer (QA) datasets that cover both aspects. We propose a novel framework for dataset generation from in-the-wild speech data, that integrates contextual reasoning with paralinguistic information. It consists of a pseudo paralinguistic label-based data condensation of in-the-wild speech and LLM-based Contextual Paralinguistic QA (CPQA) generation. The effectiveness is validated by a strong correlation in evaluations of the Qwen2-Audio-7B-Instruct model on a dataset created by our framework and human-generated CPQA dataset. The results also reveal the speech-LLM's limitations in handling empathetic reasoning tasks, highlighting the need for such datasets and more robust models. The proposed framework is first of its kind and has potential in training more robust speech-LLMs with paralinguistic reasoning capabilities.
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Dec 20, 2024



This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Towards a Speech Foundation Model for Singapore and Beyond
Dec 16, 2024This technical report describes the MERaLiON Speech Encoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON Speech Encoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON Speech Encoder was pre-trained from scratch on 200K hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Towards Quantifying and Reducing Language Mismatch Effects in Cross-Lingual Speech Anti-Spoofing
Sep 12, 2024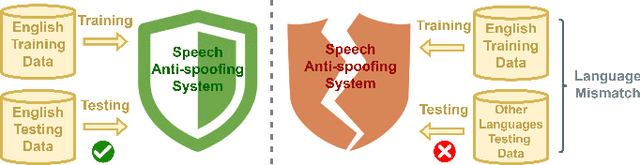
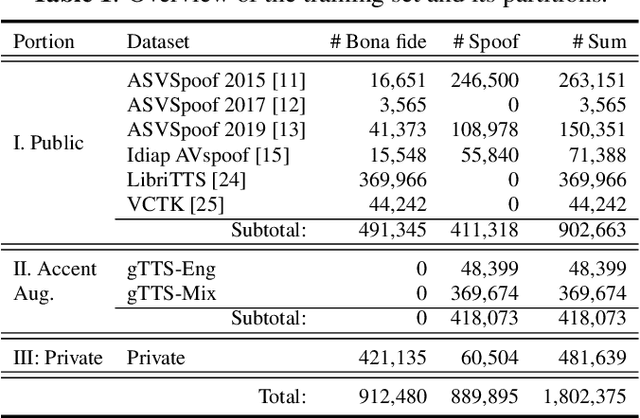
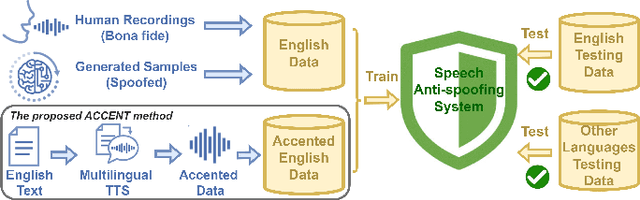
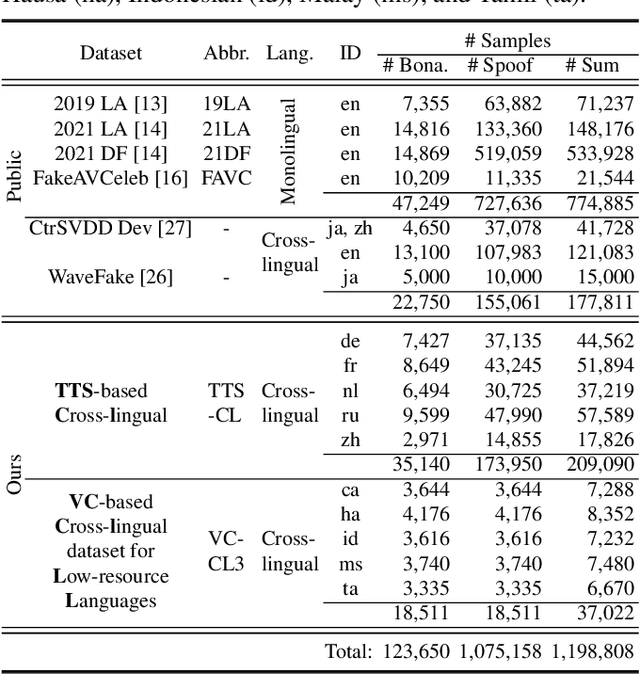
The effects of language mismatch impact speech anti-spoofing systems, while investigations and quantification of these effects remain limited. Existing anti-spoofing datasets are mainly in English, and the high cost of acquiring multilingual datasets hinders training language-independent models. We initiate this work by evaluating top-performing speech anti-spoofing systems that are trained on English data but tested on other languages, observing notable performance declines. We propose an innovative approach - Accent-based data expansion via TTS (ACCENT), which introduces diverse linguistic knowledge to monolingual-trained models, improving their cross-lingual capabilities. We conduct experiments on a large-scale dataset consisting of over 3 million samples, including 1.8 million training samples and nearly 1.2 million testing samples across 12 languages. The language mismatch effects are preliminarily quantified and remarkably reduced over 15% by applying the proposed ACCENT. This easily implementable method shows promise for multilingual and low-resource language scenarios.
Speech Foundation Model Ensembles for the Controlled Singing Voice Deepfake Detection (CtrSVDD) Challenge 2024
Sep 03, 2024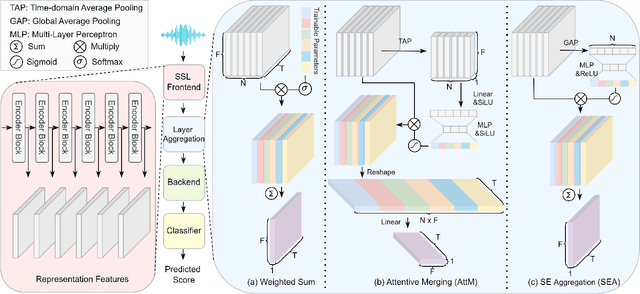
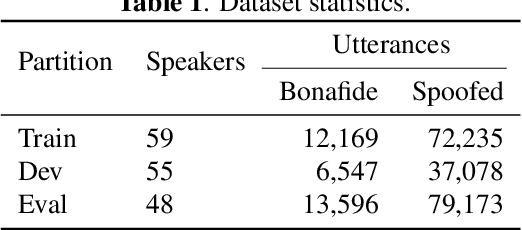
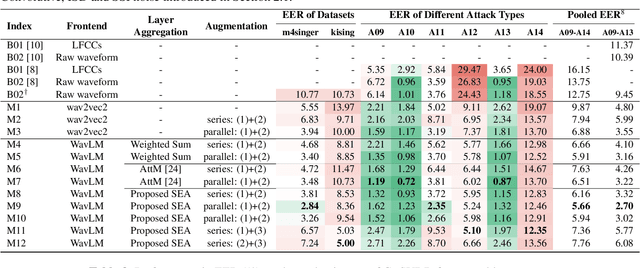
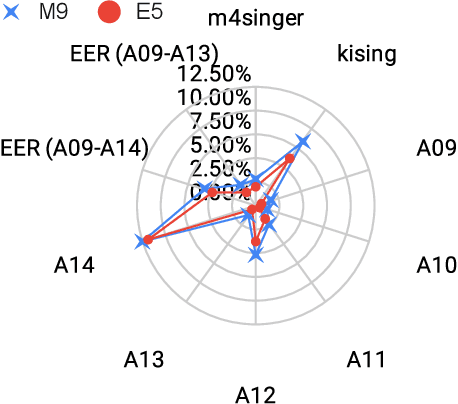
This work details our approach to achieving a leading system with a 1.79% pooled equal error rate (EER) on the evaluation set of the Controlled Singing Voice Deepfake Detection (CtrSVDD). The rapid advancement of generative AI models presents significant challenges for detecting AI-generated deepfake singing voices, attracting increased research attention. The Singing Voice Deepfake Detection (SVDD) Challenge 2024 aims to address this complex task. In this work, we explore the ensemble methods, utilizing speech foundation models to develop robust singing voice anti-spoofing systems. We also introduce a novel Squeeze-and-Excitation Aggregation (SEA) method, which efficiently and effectively integrates representation features from the speech foundation models, surpassing the performance of our other individual systems. Evaluation results confirm the efficacy of our approach in detecting deepfake singing voices. The codes can be accessed at https://github.com/Anmol2059/SVDD2024.
Attentive Merging of Hidden Embeddings from Pre-trained Speech Model for Anti-spoofing Detection
Jun 12, 2024



Self-supervised learning (SSL) speech representation models, trained on large speech corpora, have demonstrated effectiveness in extracting hierarchical speech embeddings through multiple transformer layers. However, the behavior of these embeddings in specific tasks remains uncertain. This paper investigates the multi-layer behavior of the WavLM model in anti-spoofing and proposes an attentive merging method to leverage the hierarchical hidden embeddings. Results demonstrate the feasibility of fine-tuning WavLM to achieve the best equal error rate (EER) of 0.65%, 3.50%, and 3.19% on the ASVspoof 2019LA, 2021LA, and 2021DF evaluation sets, respectively. Notably, We find that the early hidden transformer layers of the WavLM large model contribute significantly to anti-spoofing task, enabling computational efficiency by utilizing a partial pre-trained model.
Cosine Scoring with Uncertainty for Neural Speaker Embedding
Mar 11, 2024Uncertainty modeling in speaker representation aims to learn the variability present in speech utterances. While the conventional cosine-scoring is computationally efficient and prevalent in speaker recognition, it lacks the capability to handle uncertainty. To address this challenge, this paper proposes an approach for estimating uncertainty at the speaker embedding front-end and propagating it to the cosine scoring back-end. Experiments conducted on the VoxCeleb and SITW datasets confirmed the efficacy of the proposed method in handling uncertainty arising from embedding estimation. It achieved improvement with 8.5% and 9.8% average reductions in EER and minDCF compared to the conventional cosine similarity. It is also computationally efficient in practice.
* 5 pages, 4 figures