 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLPineers@ NLU of Devanagari Script Languages 2025: Hate Speech Detection using Ensembling of BERT-based models
Dec 12, 2024



This paper explores hate speech detection in Devanagari-scripted languages, focusing on Hindi and Nepali, for Subtask B of the CHIPSAL@COLING 2025 Shared Task. Using a range of transformer-based models such as XLM-RoBERTa, MURIL, and IndicBERT, we examine their effectiveness in navigating the nuanced boundary between hate speech and free expression. Our best performing model, implemented as ensemble of multilingual BERT models achieve Recall of 0.7762 (Rank 3/31 in terms of recall) and F1 score of 0.6914 (Rank 17/31). To address class imbalance, we used backtranslation for data augmentation, and cosine similarity to preserve label consistency after augmentation. This work emphasizes the need for hate speech detection in Devanagari-scripted languages and presents a foundation for further research.
Real-Time Scream Detection and Position Estimation for Worker Safety in Construction Sites
Nov 05, 2024



The construction industry faces high risks due to frequent accidents, often leaving workers in perilous situations where rapid response is critical. Traditional safety monitoring methods, including wearable sensors and GPS, often fail under obstructive or indoor conditions. This research introduces a novel real-time scream detection and localization system tailored for construction sites, especially in low-resource environments. Integrating Wav2Vec2 and Enhanced ConvNet models for accurate scream detection, coupled with the GCC-PHAT algorithm for robust time delay estimation under reverberant conditions, followed by a gradient descent-based approach to achieve precise position estimation in noisy environments. Our approach combines these concepts to achieve high detection accuracy and rapid localization, thereby minimizing false alarms and optimizing emergency response. Preliminary results demonstrate that the system not only accurately detects distress calls amidst construction noise but also reliably identifies the caller's location. This solution represents a substantial improvement in worker safety, with the potential for widespread application across high-risk occupational environments. The scripts used for training, evaluation of scream detection, position estimation, and integrated framework will be released at: https://github.com/Anmol2059/construction_safety.
Speech Foundation Model Ensembles for the Controlled Singing Voice Deepfake Detection (CtrSVDD) Challenge 2024
Sep 03, 2024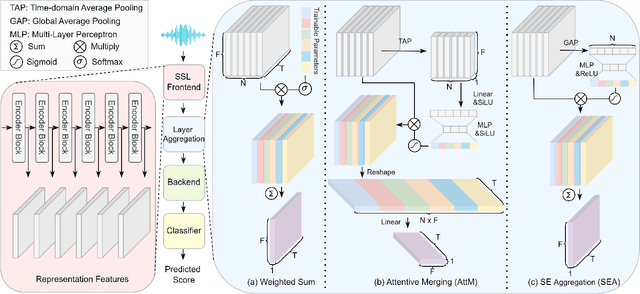
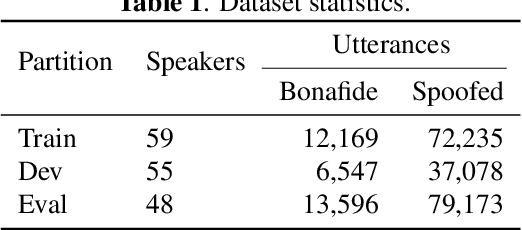
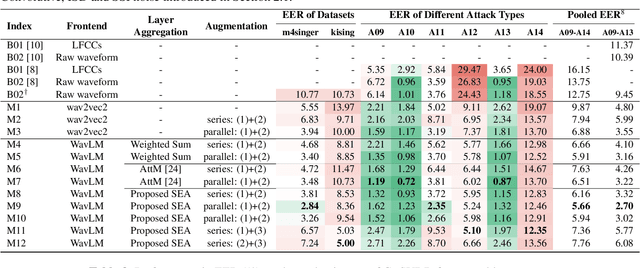
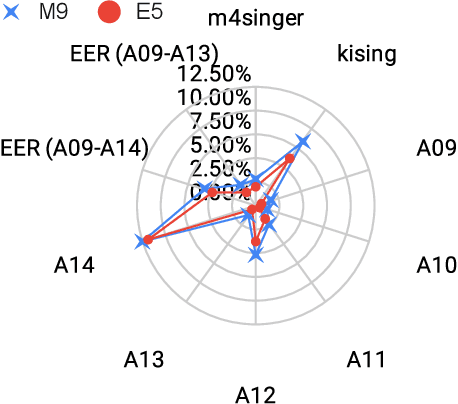
This work details our approach to achieving a leading system with a 1.79% pooled equal error rate (EER) on the evaluation set of the Controlled Singing Voice Deepfake Detection (CtrSVDD). The rapid advancement of generative AI models presents significant challenges for detecting AI-generated deepfake singing voices, attracting increased research attention. The Singing Voice Deepfake Detection (SVDD) Challenge 2024 aims to address this complex task. In this work, we explore the ensemble methods, utilizing speech foundation models to develop robust singing voice anti-spoofing systems. We also introduce a novel Squeeze-and-Excitation Aggregation (SEA) method, which efficiently and effectively integrates representation features from the speech foundation models, surpassing the performance of our other individual systems. Evaluation results confirm the efficacy of our approach in detecting deepfake singing voices. The codes can be accessed at https://github.com/Anmol2059/SVDD2024.