 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Foundation Model Ensembles for the Controlled Singing Voice Deepfake Detection (CtrSVDD) Challenge 2024
Paper and Code
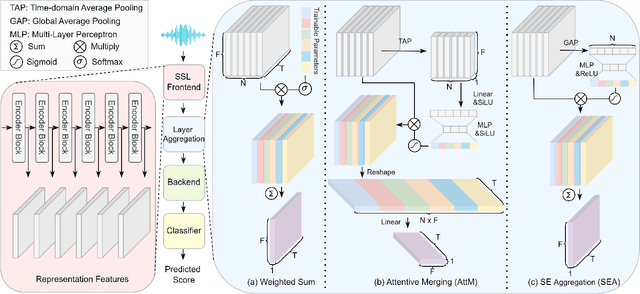
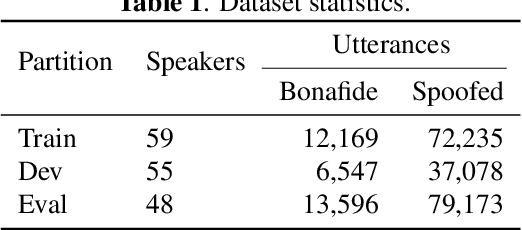
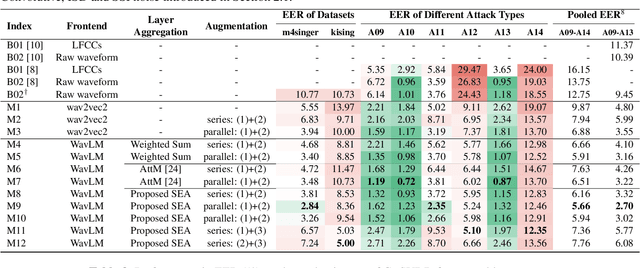
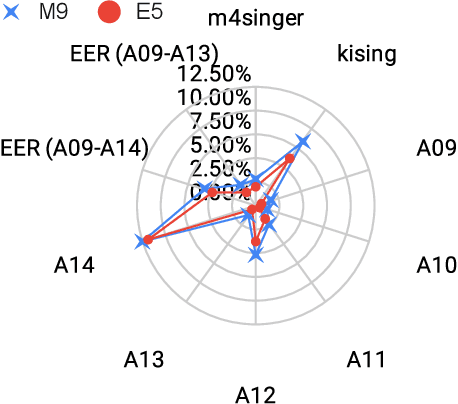
This work details our approach to achieving a leading system with a 1.79% pooled equal error rate (EER) on the evaluation set of the Controlled Singing Voice Deepfake Detection (CtrSVDD). The rapid advancement of generative AI models presents significant challenges for detecting AI-generated deepfake singing voices, attracting increased research attention. The Singing Voice Deepfake Detection (SVDD) Challenge 2024 aims to address this complex task. In this work, we explore the ensemble methods, utilizing speech foundation models to develop robust singing voice anti-spoofing systems. We also introduce a novel Squeeze-and-Excitation Aggregation (SEA) method, which efficiently and effectively integrates representation features from the speech foundation models, surpassing the performance of our other individual systems. Evaluation results confirm the efficacy of our approach in detecting deepfake singing voices. The codes can be accessed at https://github.com/Anmol2059/SVDD2024.