 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Quantifying and Reducing Language Mismatch Effects in Cross-Lingual Speech Anti-Spoofing
Paper and Code
Sep 12, 2024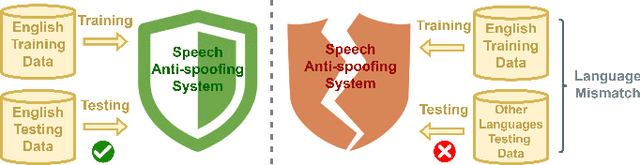
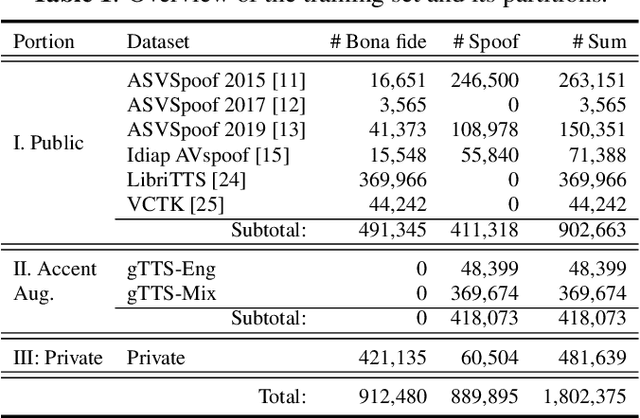
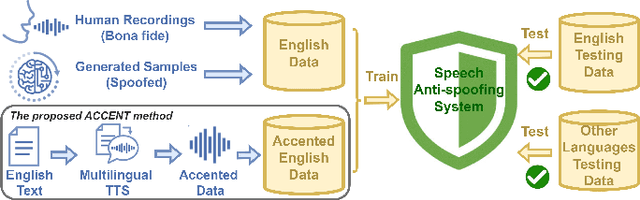
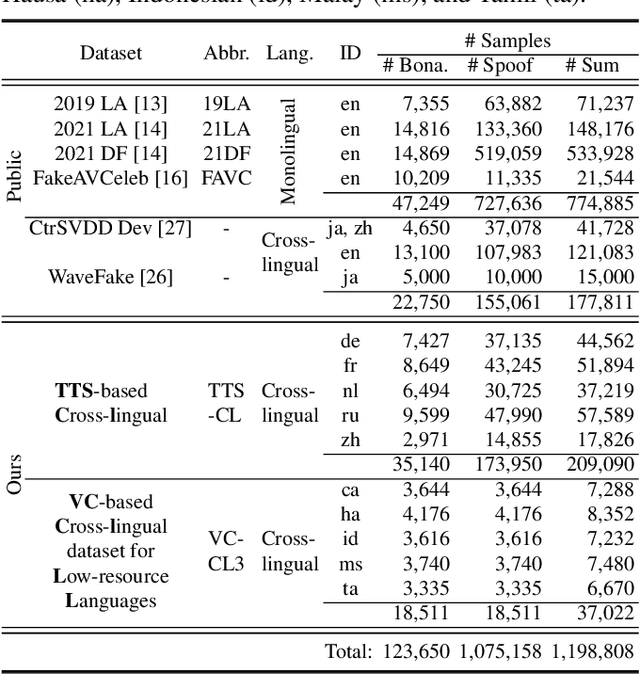
The effects of language mismatch impact speech anti-spoofing systems, while investigations and quantification of these effects remain limited. Existing anti-spoofing datasets are mainly in English, and the high cost of acquiring multilingual datasets hinders training language-independent models. We initiate this work by evaluating top-performing speech anti-spoofing systems that are trained on English data but tested on other languages, observing notable performance declines. We propose an innovative approach - Accent-based data expansion via TTS (ACCENT), which introduces diverse linguistic knowledge to monolingual-trained models, improving their cross-lingual capabilities. We conduct experiments on a large-scale dataset consisting of over 3 million samples, including 1.8 million training samples and nearly 1.2 million testing samples across 12 languages. The language mismatch effects are preliminarily quantified and remarkably reduced over 15% by applying the proposed ACCENT. This easily implementable method shows promise for multilingual and low-resource language scenarios.