 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Dec 20, 2024



This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Towards a Speech Foundation Model for Singapore and Beyond
Dec 16, 2024This technical report describes the MERaLiON Speech Encoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON Speech Encoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON Speech Encoder was pre-trained from scratch on 200K hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Analysis of Joint Speech-Text Embeddings for Semantic Matching
Apr 04, 2022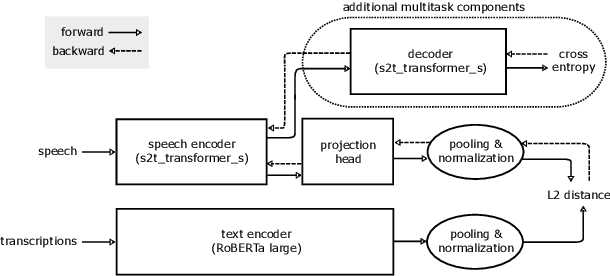
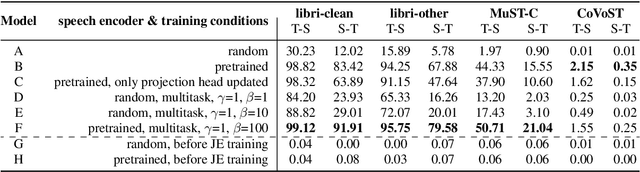

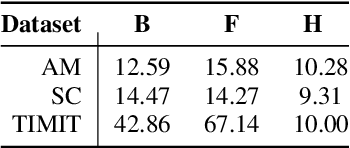
Embeddings play an important role in many recent end-to-end solutions for language processing problems involving more than one data modality. Although there has been some effort to understand the properties of single-modality embedding spaces, particularly that of text, their cross-modal counterparts are less understood. In this work, we study a joint speech-text embedding space trained for semantic matching by minimizing the distance between paired utterance and transcription inputs. This was done through dual encoders in a teacher-student model setup, with a pretrained language model acting as the teacher and a transformer-based speech encoder as the student. We extend our method to incorporate automatic speech recognition through both pretraining and multitask scenarios and found that both approaches improve semantic matching. Multiple techniques were utilized to analyze and evaluate cross-modal semantic alignment of the embeddings: a quantitative retrieval accuracy metric, zero-shot classification to investigate generalizability, and probing of the encoders to observe the extent of knowledge transfer from one modality to another.
Conditioning a Recurrent Neural Network to synthesize musical instrument transients
Mar 26, 2019
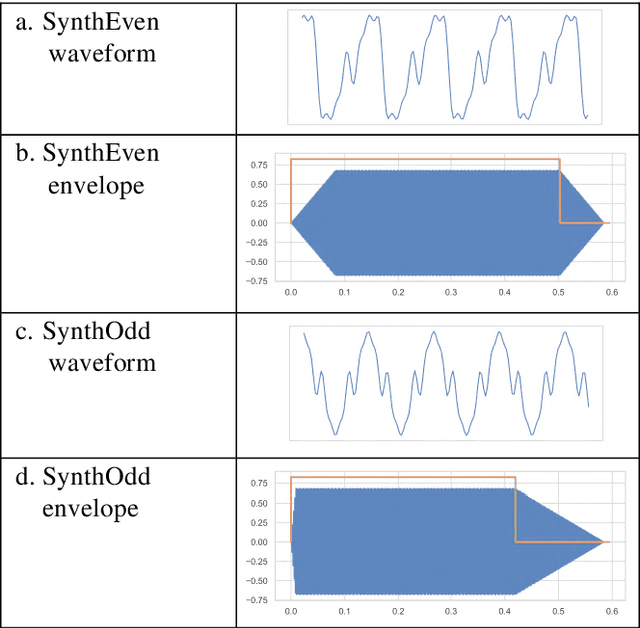
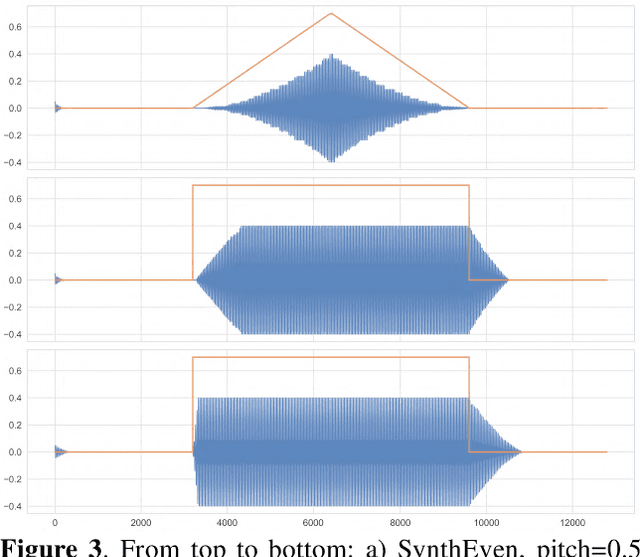
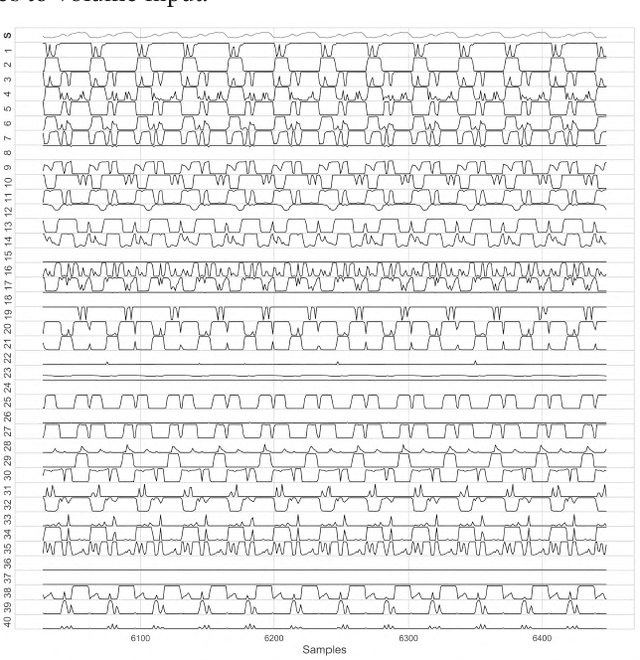
A recurrent Neural Network (RNN) is trained to predict sound samples based on audio input augmented by control parameter information for pitch, volume, and instrument identification. During the generative phase following training, audio input is taken from the output of the previous time step, and the parameters are externally controlled allowing the network to be played as a musical instrument. Building on an architecture developed in previous work, we focus on the learning and synthesis of transients - the temporal response of the network during the short time (tens of milliseconds) following the onset and offset of a control signal. We find that the network learns the particular transient characteristics of two different synthetic instruments, and furthermore shows some ability to interpolate between the characteristics of the instruments used in training in response to novel parameter settings. We also study the behaviour of the units in hidden layers of the RNN using various visualisation techniques and find a variety of volume-specific response characteristics.