 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodness-of-pronunciation without phoneme time alignment
Mar 26, 2026In speech evaluation, an Automatic Speech Recognition (ASR) model often computes time boundaries and phoneme posteriors for input features. However, limited data for ASR training hinders expansion of speech evaluation to low-resource languages. Open-source weakly-supervised models are capable of ASR over many languages, but they are frame-asynchronous and not phonemic, hindering feature extraction for speech evaluation. This paper proposes to overcome incompatibilities for feature extraction with weakly-supervised models, easing expansion of speech evaluation to low-resource languages. Phoneme posteriors are computed by mapping ASR hypotheses to a phoneme confusion network. Word instead of phoneme-level speaking rate and duration are used. Phoneme and frame-level features are combined using a cross-attention architecture, obviating phoneme time alignment. This performs comparably with standard frame-synchronous features on English speechocean762 and low-resource Tamil datasets.
Incorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
Beyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Dec 20, 2024



This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Towards a Speech Foundation Model for Singapore and Beyond
Dec 16, 2024This technical report describes the MERaLiON Speech Encoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON Speech Encoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON Speech Encoder was pre-trained from scratch on 200K hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Semi-supervised Learning For Robust Speech Evaluation
Sep 23, 2024


Speech evaluation measures a learners oral proficiency using automatic models. Corpora for training such models often pose sparsity challenges given that there often is limited scored data from teachers, in addition to the score distribution across proficiency levels being often imbalanced among student cohorts. Automatic scoring is thus not robust when faced with under-represented samples or out-of-distribution samples, which inevitably exist in real-world deployment scenarios. This paper proposes to address such challenges by exploiting semi-supervised pre-training and objective regularization to approximate subjective evaluation criteria. In particular, normalized mutual information is used to quantify the speech characteristics from the learner and the reference. An anchor model is trained using pseudo labels to predict the correctness of pronunciation. An interpolated loss function is proposed to minimize not only the prediction error with respect to ground-truth scores but also the divergence between two probability distributions estimated by the speech evaluation model and the anchor model. Compared to other state-of-the-art methods on a public data-set, this approach not only achieves high performance while evaluating the entire test-set as a whole, but also brings the most evenly distributed prediction error across distinct proficiency levels. Furthermore, empirical results show the model accuracy on out-of-distribution data also compares favorably with competitive baselines.
Noise robust distillation of self-supervised speech models via correlation metrics
Dec 19, 2023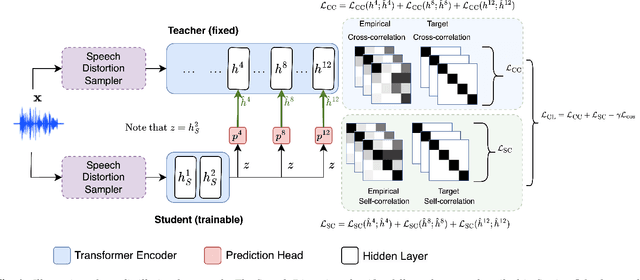
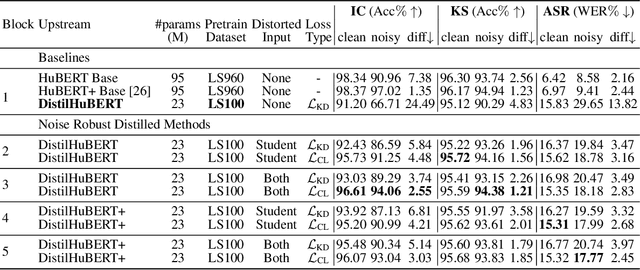

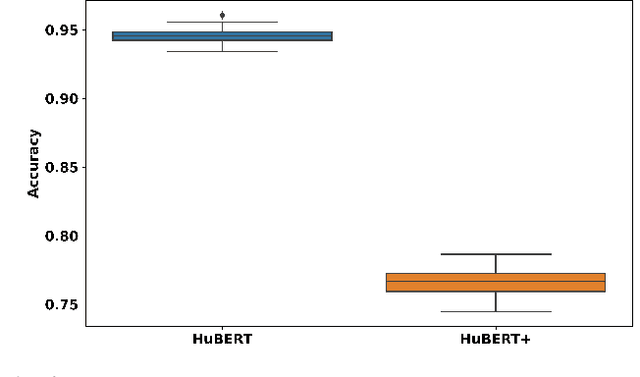
Compared to large speech foundation models, small distilled models exhibit degraded noise robustness. The student's robustness can be improved by introducing noise at the inputs during pre-training. Despite this, using the standard distillation loss still yields a student with degraded performance. Thus, this paper proposes improving student robustness via distillation with correlation metrics. Teacher behavior is learned by maximizing the teacher and student cross-correlation matrix between their representations towards identity. Noise robustness is encouraged via the student's self-correlation minimization. The proposed method is agnostic of the teacher model and consistently outperforms the previous approach. This work also proposes an heuristic to weigh the importance of the two correlation terms automatically. Experiments show consistently better clean and noise generalization on Intent Classification, Keyword Spotting, and Automatic Speech Recognition tasks on SUPERB Challenge.
Multiple output samples for each input in a single-output Gaussian process
Jun 05, 2023
The standard Gaussian Process (GP) only considers a single output sample per input in the training set. Datasets for subjective tasks, such as spoken language assessment, may be annotated with output labels from multiple human raters per input. This paper proposes to generalise the GP to allow for these multiple output samples in the training set, and thus make use of available output uncertainty information. This differs from a multi-output GP, as all output samples are from the same task here. The output density function is formulated to be the joint likelihood of observing all output samples, and latent variables are not repeated to reduce computation cost. The test set predictions are inferred similarly to a standard GP, with a difference being in the optimised hyper-parameters. This is evaluated on speechocean762, showing that it allows the GP to compute a test set output distribution that is more similar to the collection of reference outputs from the multiple human raters.
Diarisation using location tracking with agglomerative clustering
Sep 24, 2021


Previous works have shown that spatial location information can be complementary to speaker embeddings for a speaker diarisation task. However, the models used often assume that speakers are fairly stationary throughout a meeting. This paper proposes to relax this assumption, by explicitly modelling the movements of speakers within an Agglomerative Hierarchical Clustering (AHC) diarisation framework. Kalman filters, which track the locations of speakers, are used to compute log-likelihood ratios that contribute to the cluster affinity computations for the AHC merging and stopping decisions. Experiments show that the proposed approach is able to yield improvements on a Microsoft rich meeting transcription task, compared to methods that do not use location information or that make stationarity assumptions.
Joint speaker diarisation and tracking in switching state-space model
Sep 23, 2021

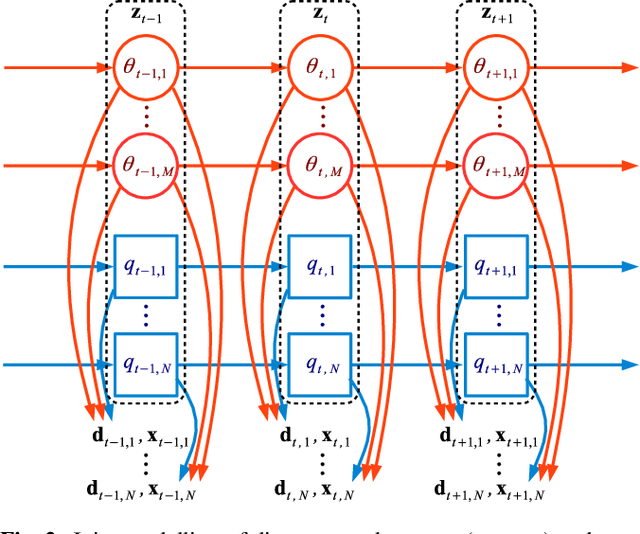
Speakers may move around while diarisation is being performed. When a microphone array is used, the instantaneous locations of where the sounds originated from can be estimated, and previous investigations have shown that such information can be complementary to speaker embeddings in the diarisation task. However, these approaches often assume that speakers are fairly stationary throughout a meeting. This paper relaxes this assumption, by proposing to explicitly track the movements of speakers while jointly performing diarisation within a unified model. A state-space model is proposed, where the hidden state expresses the identity of the current active speaker and the predicted locations of all speakers. The model is implemented as a particle filter. Experiments on a Microsoft rich meeting transcription task show that the proposed joint location tracking and diarisation approach is able to perform comparably with other methods that use location information.