 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowW2N: Whispered-to-Normal Speech Conversion via Flow-Matching
Mar 04, 2026Whispered-to-normal (W2N) speech conversion aims to reconstruct missing phonation from whispered input while preserving content and speaker identity. This task is challenging due to temporal misalignment between whisper and voiced recordings and lack of paired data. We propose FlowW2N, a conditional flow matching approach that trains exclusively on synthetic, time-aligned whisper-normal pairs and conditions on domain-invariant features. We exploit high-level ASR embeddings that exhibits strong invariance between synthetic and real whispered speech, enabling generalization to real whispers despite never observing it during training. We verify this invariance across ASR layers and propose a selection criterion optimizing content informativeness and cross-domain invariance. Our method achieves SOTA intelligibility on the CHAINS and wTIMIT datasets, reducing Word Error Rate by 26-46% relative to prior work while using only 10 steps at inference and requiring no real paired data.
A correlation-permutation approach for speech-music encoders model merging
Jun 13, 2025Creating a unified speech and music model requires expensive pre-training. Model merging can instead create an unified audio model with minimal computational expense. However, direct merging is challenging when the models are not aligned in the weight space. Motivated by Git Re-Basin, we introduce a correlation-permutation approach that aligns a music encoder's internal layers with a speech encoder. We extend previous work to the case of merging transformer layers. The method computes a permutation matrix that maximizes the model's features-wise cross-correlations layer by layer, enabling effective fusion of these otherwise disjoint models. The merged model retains speech capabilities through this method while significantly enhancing music performance, achieving an improvement of 14.83 points in average score compared to linear interpolation model merging. This work allows the creation of unified audio models from independently trained encoders.
Multi-Distillation from Speech and Music Representation Models
Jun 08, 2025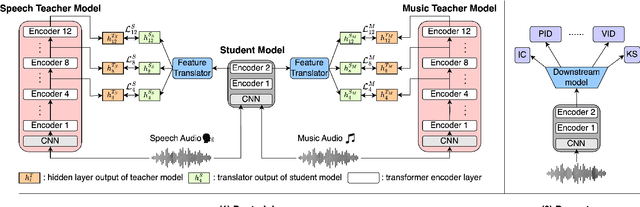

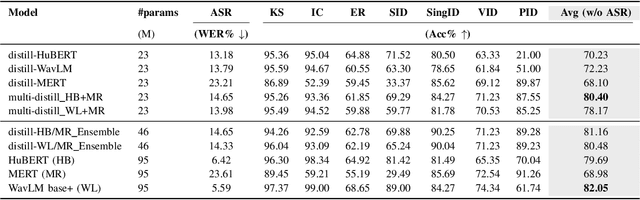
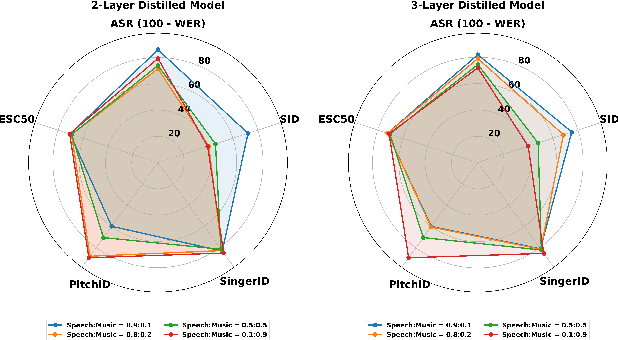
Real-world audio often mixes speech and music, yet models typically handle only one domain. This paper introduces a multi-teacher distillation framework that unifies speech and music models into a single one while significantly reducing model size. Our approach leverages the strengths of domain-specific teacher models, such as HuBERT for speech and MERT for music, and explores various strategies to balance both domains. Experiments across diverse tasks demonstrate that our model matches the performance of domain-specific models, showing the effectiveness of cross-domain distillation. Additionally, we conduct few-shot learning experiments, highlighting the need for general models in real-world scenarios where labeled data is limited. Our results show that our model not only performs on par with specialized models but also outperforms them in few-shot scenarios, proving that a cross-domain approach is essential and effective for diverse tasks with limited data.
Distilling a speech and music encoder with task arithmetic
May 19, 2025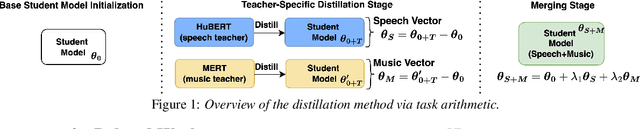
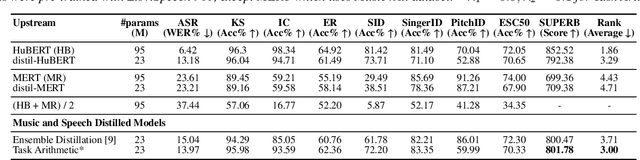
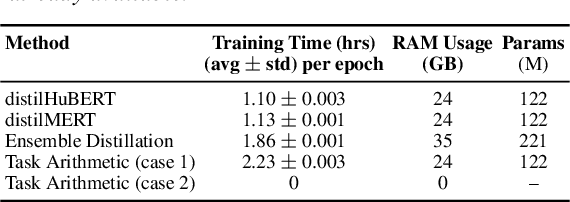
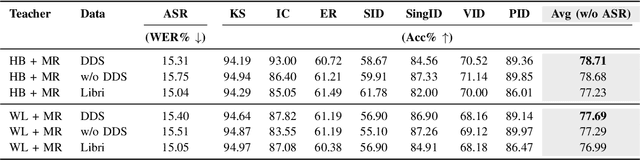
Despite the progress in self-supervised learning (SSL) for speech and music, existing models treat these domains separately, limiting their capacity for unified audio understanding. A unified model is desirable for applications that require general representations, e.g. audio large language models. Nonetheless, directly training a general model for speech and music is computationally expensive. Knowledge Distillation of teacher ensembles may be a natural solution, but we posit that decoupling the distillation of the speech and music SSL models allows for more flexibility. Thus, we propose to learn distilled task vectors and then linearly interpolate them to form a unified speech+music model. This strategy enables flexible domain emphasis through adjustable weights and is also simpler to train. Experiments on speech and music benchmarks demonstrate that our method yields superior overall performance compared to ensemble distillation.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Dataset-Distillation Generative Model for Speech Emotion Recognition
Jun 05, 2024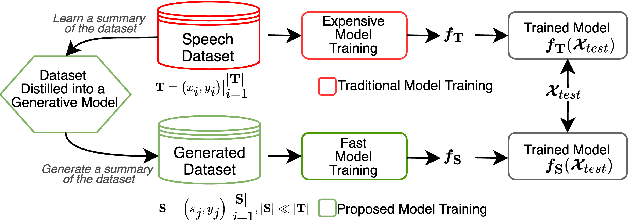

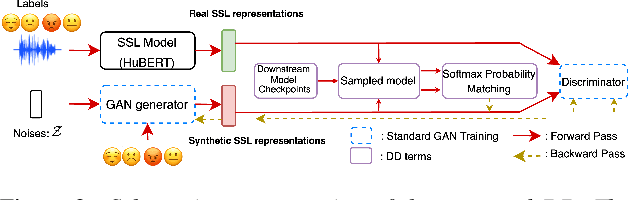
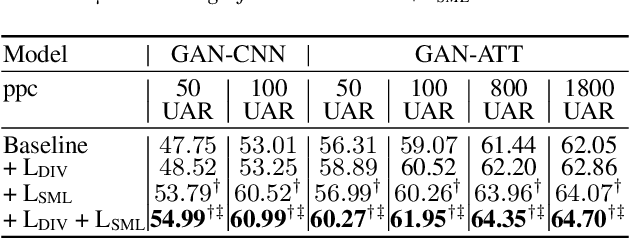
Deep learning models for speech rely on large datasets, presenting computational challenges. Yet, performance hinges on training data size. Dataset Distillation (DD) aims to learn a smaller dataset without much performance degradation when training with it. DD has been investigated in computer vision but not yet in speech. This paper presents the first approach for DD to speech targeting Speech Emotion Recognition on IEMOCAP. We employ Generative Adversarial Networks (GANs) not to mimic real data but to distil key discriminative information of IEMOCAP that is useful for downstream training. The GAN then replaces the original dataset and can sample custom synthetic dataset sizes. It performs comparably when following the original class imbalance but improves performance by 0.3% absolute UAR with balanced classes. It also reduces dataset storage and accelerates downstream training by 95% in both cases and reduces speaker information which could help for a privacy application.
Noise robust distillation of self-supervised speech models via correlation metrics
Dec 19, 2023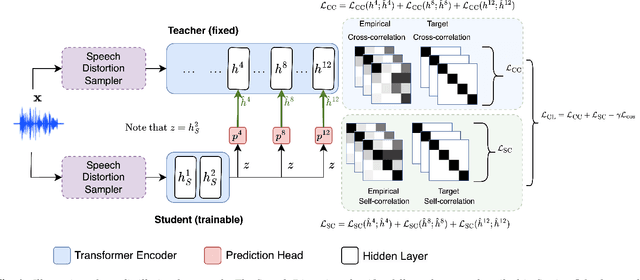
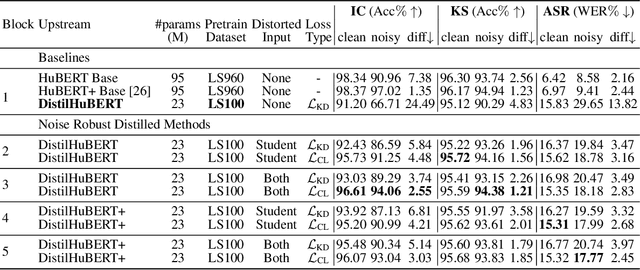

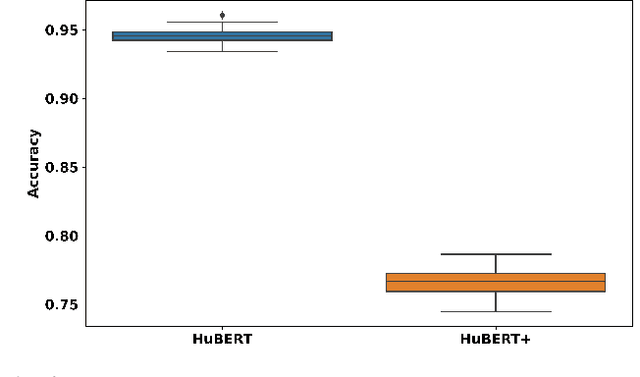
Compared to large speech foundation models, small distilled models exhibit degraded noise robustness. The student's robustness can be improved by introducing noise at the inputs during pre-training. Despite this, using the standard distillation loss still yields a student with degraded performance. Thus, this paper proposes improving student robustness via distillation with correlation metrics. Teacher behavior is learned by maximizing the teacher and student cross-correlation matrix between their representations towards identity. Noise robustness is encouraged via the student's self-correlation minimization. The proposed method is agnostic of the teacher model and consistently outperforms the previous approach. This work also proposes an heuristic to weigh the importance of the two correlation terms automatically. Experiments show consistently better clean and noise generalization on Intent Classification, Keyword Spotting, and Automatic Speech Recognition tasks on SUPERB Challenge.
Are Soft Prompts Good Zero-shot Learners for Speech Recognition?
Sep 18, 2023



Large self-supervised pre-trained speech models require computationally expensive fine-tuning for downstream tasks. Soft prompt tuning offers a simple parameter-efficient alternative by utilizing minimal soft prompt guidance, enhancing portability while also maintaining competitive performance. However, not many people understand how and why this is so. In this study, we aim to deepen our understanding of this emerging method by investigating the role of soft prompts in automatic speech recognition (ASR). Our findings highlight their role as zero-shot learners in improving ASR performance but also make them vulnerable to malicious modifications. Soft prompts aid generalization but are not obligatory for inference. We also identify two primary roles of soft prompts: content refinement and noise information enhancement, which enhances robustness against background noise. Additionally, we propose an effective modification on noise prompts to show that they are capable of zero-shot learning on adapting to out-of-distribution noise environments.