 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise robust distillation of self-supervised speech models via correlation metrics
Paper and Code
Dec 19, 2023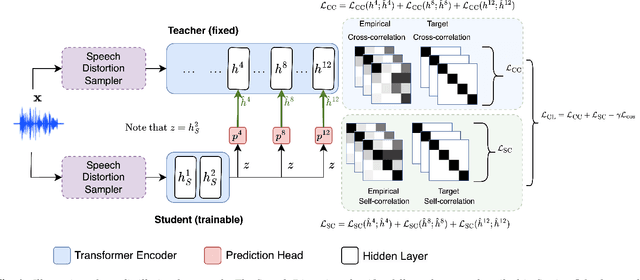
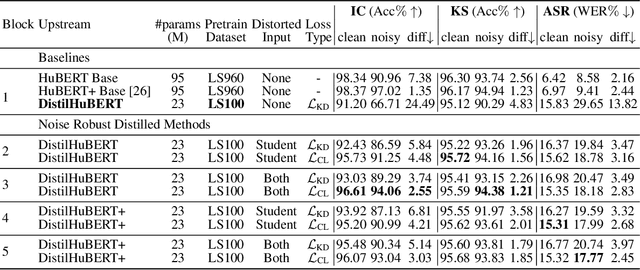

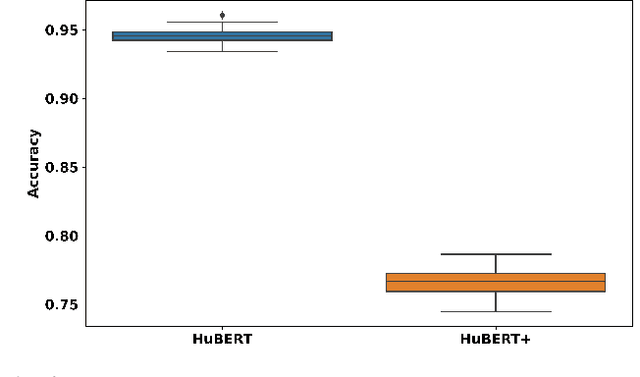
Compared to large speech foundation models, small distilled models exhibit degraded noise robustness. The student's robustness can be improved by introducing noise at the inputs during pre-training. Despite this, using the standard distillation loss still yields a student with degraded performance. Thus, this paper proposes improving student robustness via distillation with correlation metrics. Teacher behavior is learned by maximizing the teacher and student cross-correlation matrix between their representations towards identity. Noise robustness is encouraged via the student's self-correlation minimization. The proposed method is agnostic of the teacher model and consistently outperforms the previous approach. This work also proposes an heuristic to weigh the importance of the two correlation terms automatically. Experiments show consistently better clean and noise generalization on Intent Classification, Keyword Spotting, and Automatic Speech Recognition tasks on SUPERB Challenge.