 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunAudio-ASR Technical Report
Sep 15, 2025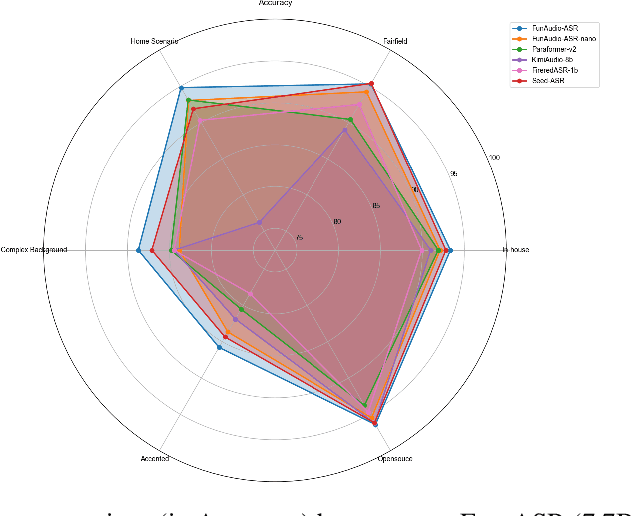
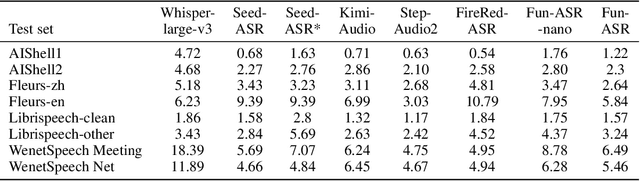
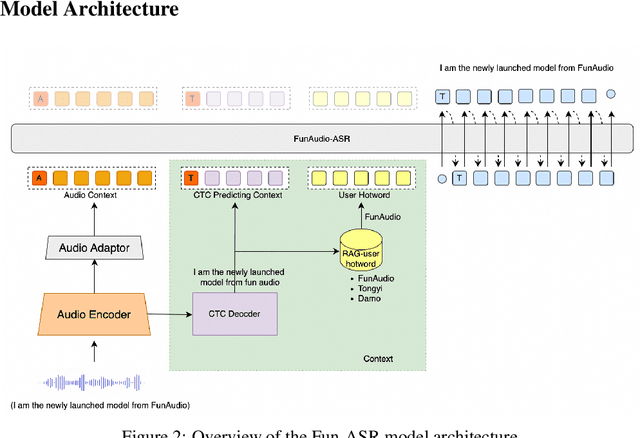
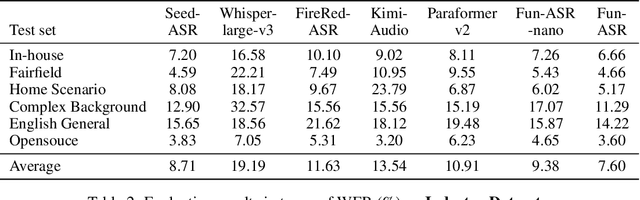
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
Emotional Dimension Control in Language Model-Based Text-to-Speech: Spanning a Broad Spectrum of Human Emotions
Sep 25, 2024Current emotional text-to-speech (TTS) systems face challenges in mimicking a broad spectrum of human emotions due to the inherent complexity of emotions and limitations in emotional speech datasets and models. This paper proposes a TTS framework that facilitates control over pleasure, arousal, and dominance, and can synthesize a diversity of emotional styles without requiring any emotional speech data during TTS training. We train an emotional attribute predictor using only categorical labels from speech data, aligning with psychological research and incorporating anchored dimensionality reduction on self-supervised learning (SSL) features. The TTS framework converts text inputs into phonetic tokens via an autoregressive language model and uses pseudo-emotional dimensions to guide the parallel prediction of fine-grained acoustic details. Experiments conducted on the LibriTTS dataset demonstrate that our framework can synthesize speech with enhanced naturalness and a variety of emotional styles by effectively controlling emotional dimensions, even without the inclusion of any emotional speech during TTS training.
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Jun 04, 2024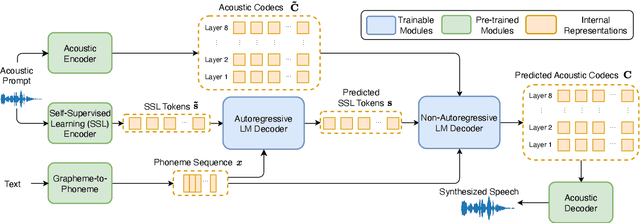
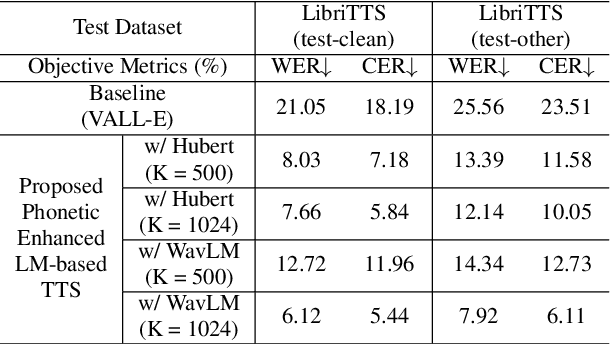
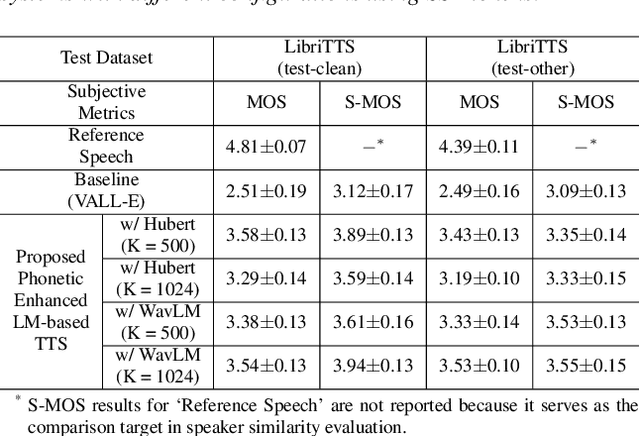
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation
Dec 19, 2023



Our previously proposed MossFormer has achieved promising performance in monaural speech separation. However, it predominantly adopts a self-attention-based MossFormer module, which tends to emphasize longer-range, coarser-scale dependencies, with a deficiency in effectively modelling finer-scale recurrent patterns. In this paper, we introduce a novel hybrid model that provides the capabilities to model both long-range, coarse-scale dependencies and fine-scale recurrent patterns by integrating a recurrent module into the MossFormer framework. Instead of applying the recurrent neural networks (RNNs) that use traditional recurrent connections, we present a recurrent module based on a feedforward sequential memory network (FSMN), which is considered "RNN-free" recurrent network due to the ability to capture recurrent patterns without using recurrent connections. Our recurrent module mainly comprises an enhanced dilated FSMN block by using gated convolutional units (GCU) and dense connections. In addition, a bottleneck layer and an output layer are also added for controlling information flow. The recurrent module relies on linear projections and convolutions for seamless, parallel processing of the entire sequence. The integrated MossFormer2 hybrid model demonstrates remarkable enhancements over MossFormer and surpasses other state-of-the-art methods in WSJ0-2/3mix, Libri2Mix, and WHAM!/WHAMR! benchmarks.
SPGM: Prioritizing Local Features for enhanced speech separation performance
Sep 22, 2023



Dual-path is a popular architecture for speech separation models (e.g. Sepformer) which splits long sequences into overlapping chunks for its intra- and inter-blocks that separately model intra-chunk local features and inter-chunk global relationships. However, it has been found that inter-blocks, which comprise half a dual-path model's parameters, contribute minimally to performance. Thus, we propose the Single-Path Global Modulation (SPGM) block to replace inter-blocks. SPGM is named after its structure consisting of a parameter-free global pooling module followed by a modulation module comprising only 2% of the model's total parameters. The SPGM block allows all transformer layers in the model to be dedicated to local feature modelling, making the overall model single-path. SPGM achieves 22.1 dB SI-SDRi on WSJ0-2Mix and 20.4 dB SI-SDRi on Libri2Mix, exceeding the performance of Sepformer by 0.5 dB and 0.3 dB respectively and matches the performance of recent SOTA models with up to 8 times fewer parameters.
Are Soft Prompts Good Zero-shot Learners for Speech Recognition?
Sep 18, 2023



Large self-supervised pre-trained speech models require computationally expensive fine-tuning for downstream tasks. Soft prompt tuning offers a simple parameter-efficient alternative by utilizing minimal soft prompt guidance, enhancing portability while also maintaining competitive performance. However, not many people understand how and why this is so. In this study, we aim to deepen our understanding of this emerging method by investigating the role of soft prompts in automatic speech recognition (ASR). Our findings highlight their role as zero-shot learners in improving ASR performance but also make them vulnerable to malicious modifications. Soft prompts aid generalization but are not obligatory for inference. We also identify two primary roles of soft prompts: content refinement and noise information enhancement, which enhances robustness against background noise. Additionally, we propose an effective modification on noise prompts to show that they are capable of zero-shot learning on adapting to out-of-distribution noise environments.
ACA-Net: Towards Lightweight Speaker Verification using Asymmetric Cross Attention
May 20, 2023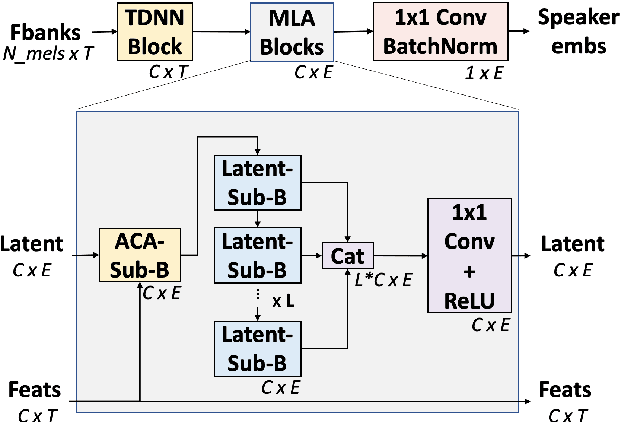
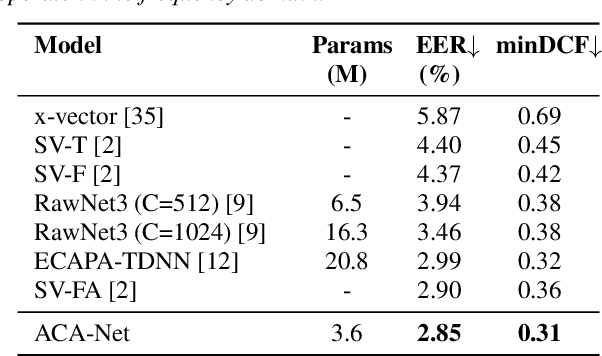
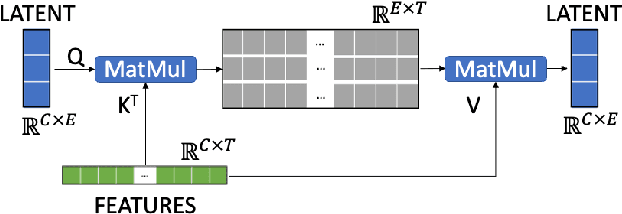
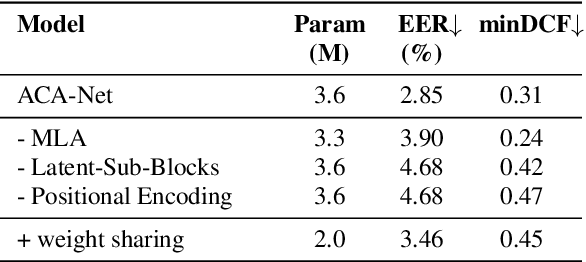
In this paper, we propose ACA-Net, a lightweight, global context-aware speaker embedding extractor for Speaker Verification (SV) that improves upon existing work by using Asymmetric Cross Attention (ACA) to replace temporal pooling. ACA is able to distill large, variable-length sequences into small, fixed-sized latents by attending a small query to large key and value matrices. In ACA-Net, we build a Multi-Layer Aggregation (MLA) block using ACA to generate fixed-sized identity vectors from variable-length inputs. Through global attention, ACA-Net acts as an efficient global feature extractor that adapts to temporal variability unlike existing SV models that apply a fixed function for pooling over the temporal dimension which may obscure information about the signal's non-stationary temporal variability. Our experiments on the WSJ0-1talker show ACA-Net outperforms a strong baseline by 5\% relative improvement in EER using only 1/5 of the parameters.
Contrastive Speech Mixup for Low-resource Keyword Spotting
May 02, 2023Most of the existing neural-based models for keyword spotting (KWS) in smart devices require thousands of training samples to learn a decent audio representation. However, with the rising demand for smart devices to become more personalized, KWS models need to adapt quickly to smaller user samples. To tackle this challenge, we propose a contrastive speech mixup (CosMix) learning algorithm for low-resource KWS. CosMix introduces an auxiliary contrastive loss to the existing mixup augmentation technique to maximize the relative similarity between the original pre-mixed samples and the augmented samples. The goal is to inject enhancing constraints to guide the model towards simpler but richer content-based speech representations from two augmented views (i.e. noisy mixed and clean pre-mixed utterances). We conduct our experiments on the Google Speech Command dataset, where we trim the size of the training set to as small as 2.5 mins per keyword to simulate a low-resource condition. Our experimental results show a consistent improvement in the performance of multiple models, which exhibits the effectiveness of our method.
deHuBERT: Disentangling Noise in a Self-supervised Model for Robust Speech Recognition
Feb 28, 2023Existing self-supervised pre-trained speech models have offered an effective way to leverage massive unannotated corpora to build good automatic speech recognition (ASR). However, many current models are trained on a clean corpus from a single source, which tends to do poorly when noise is present during testing. Nonetheless, it is crucial to overcome the adverse influence of noise for real-world applications. In this work, we propose a novel training framework, called deHuBERT, for noise reduction encoding inspired by H. Barlow's redundancy-reduction principle. The new framework improves the HuBERT training algorithm by introducing auxiliary losses that drive the self- and cross-correlation matrix between pairwise noise-distorted embeddings towards identity matrix. This encourages the model to produce noise-agnostic speech representations. With this method, we report improved robustness in noisy environments, including unseen noises, without impairing the performance on the clean set.