 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Perspective on Adversarial Membership Manipulation in Vision Models
Apr 03, 2026Membership inference attacks (MIAs) aim to determine whether a specific data point was part of a model's training set, serving as effective tools for evaluating privacy leakage of vision models. However, existing MIAs implicitly assume honest query inputs, and their adversarial robustness remains unexplored. We show that MIAs for vision models expose a previously overlooked adversarial surface: adversarial membership manipulation, where imperceptible perturbations can reliably push non-member images into the "member" region of state-of-the-art MIAs. In this paper, we provide the first unified perspective on this phenomenon by analyzing its mechanism and implications. We begin by demonstrating that adversarial membership fabrication is consistently effective across diverse architectures and datasets. We then reveal a distinctive geometric signature - a characteristic gradient-norm collapse trajectory - that reliably separates fabricated from true members despite their nearly identical semantic representations. Building on this insight, we introduce a principled detection strategy grounded in gradient-geometry signals and develop a robust inference framework that substantially mitigates adversarial manipulation. Extensive experiments show that fabrication is broadly effective, while our detection and robust inference strategies significantly enhance resilience. This work establishes the first comprehensive framework for adversarial membership manipulation in vision models.
HATS: Hardness-Aware Trajectory Synthesis for GUI Agents
Mar 12, 2026Graphical user interface (GUI) agents powered by large vision-language models (VLMs) have shown remarkable potential in automating digital tasks, highlighting the need for high-quality trajectory data to support effective agent training. Yet existing trajectory synthesis pipelines often yield agents that fail to generalize beyond simple interactions. We identify this limitation as stemming from the neglect of semantically ambiguous actions, whose meanings are context-dependent, sequentially dependent, or visually ambiguous. Such actions are crucial for real-world robustness but are under-represented and poorly processed in current datasets, leading to semantic misalignment between task instructions and execution. To address these issues, we propose HATS, a Hardness-Aware Trajectory Synthesis framework designed to mitigate the impact of semantic ambiguity. We define hardness as the degree of semantic ambiguity associated with an action and develop two complementary modules: (1) hardness-driven exploration, which guides data collection toward ambiguous yet informative interactions, and (2) alignment-guided refinement, which iteratively validates and repairs instruction-execution alignment. The two modules operate in a closed loop: exploration supplies refinement with challenging trajectories, while refinement feedback updates the hardness signal to guide future exploration. Extensive experiments show that agents trained with HATS consistently outperform state-of-the-art baselines across benchmark GUI environments.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
Qwen2 Technical Report
Jul 16, 2024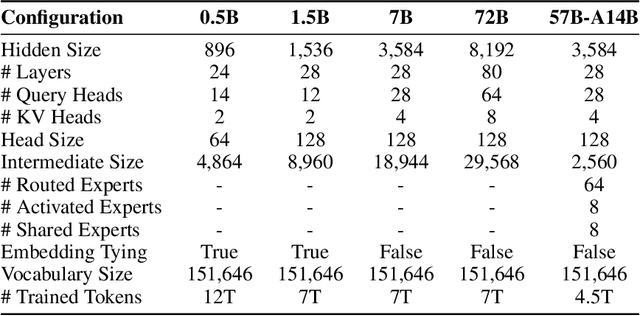
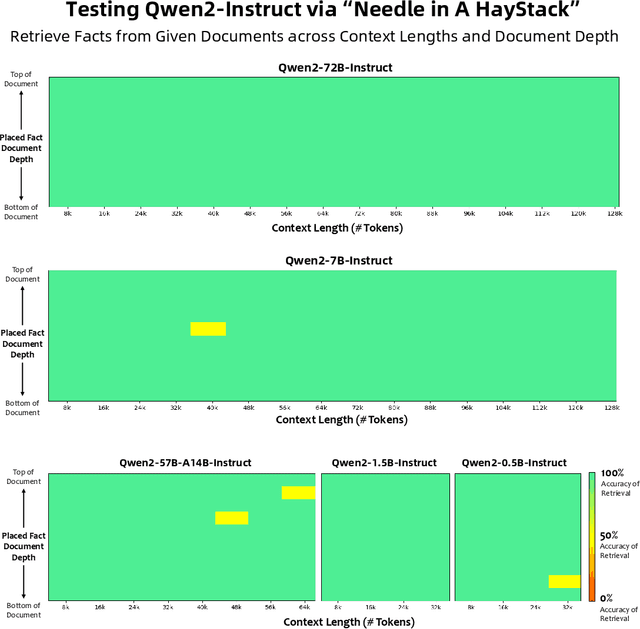
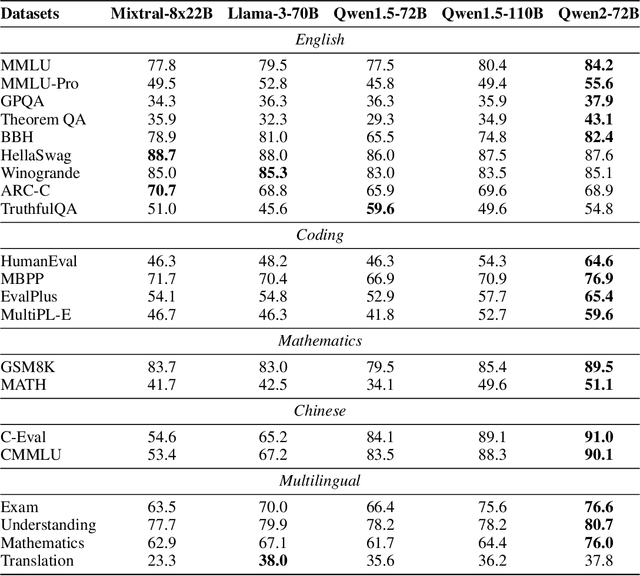
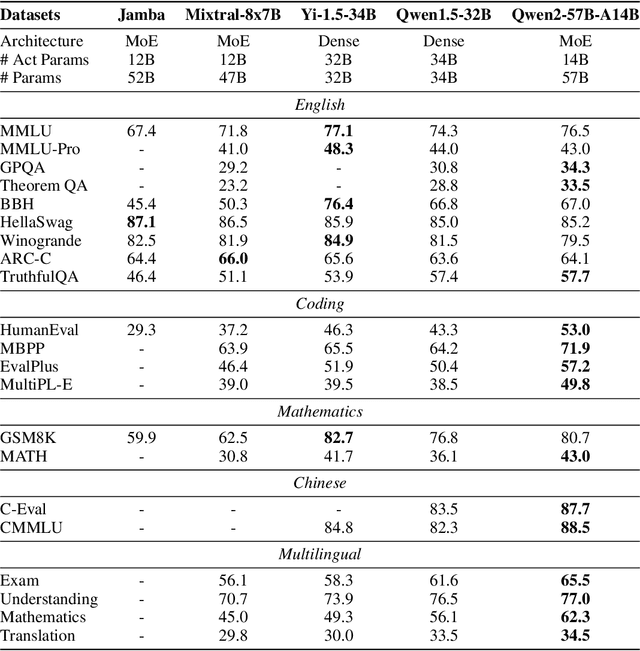
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Scalable Continuous-time Diffusion Framework for Network Inference and Influence Estimation
Mar 05, 2024



The study of continuous-time information diffusion has been an important area of research for many applications in recent years. When only the diffusion traces (cascades) are accessible, cascade-based network inference and influence estimation are two essential problems to explore. Alas, existing methods exhibit limited capability to infer and process networks with more than a few thousand nodes, suffering from scalability issues. In this paper, we view the diffusion process as a continuous-time dynamical system, based on which we establish a continuous-time diffusion model. Subsequently, we instantiate the model to a scalable and effective framework (FIM) to approximate the diffusion propagation from available cascades, thereby inferring the underlying network structure. Furthermore, we undertake an analysis of the approximation error of FIM for network inference. To achieve the desired scalability for influence estimation, we devise an advanced sampling technique and significantly boost the efficiency. We also quantify the effect of the approximation error on influence estimation theoretically. Experimental results showcase the effectiveness and superior scalability of FIM on network inference and influence estimation.
IMTLab: An Open-Source Platform for Building, Evaluating, and Diagnosing Interactive Machine Translation Systems
Oct 17, 2023We present IMTLab, an open-source end-to-end interactive machine translation (IMT) system platform that enables researchers to quickly build IMT systems with state-of-the-art models, perform an end-to-end evaluation, and diagnose the weakness of systems. IMTLab treats the whole interactive translation process as a task-oriented dialogue with a human-in-the-loop setting, in which human interventions can be explicitly incorporated to produce high-quality, error-free translations. To this end, a general communication interface is designed to support the flexible IMT architectures and user policies. Based on the proposed design, we construct a simulated and real interactive environment to achieve end-to-end evaluation and leverage the framework to systematically evaluate previous IMT systems. Our simulated and manual experiments show that the prefix-constrained decoding approach still gains the lowest editing cost in the end-to-end evaluation, while BiTIIMT achieves comparable editing cost with a better interactive experience.
Nearest Neighbor Machine Translation is Meta-Optimizer on Output Projection Layer
May 22, 2023



Nearest Neighbor Machine Translation ($k$NN-MT) has achieved great success on domain adaptation tasks by integrating pre-trained Neural Machine Translation (NMT) models with domain-specific token-level retrieval. However, the reasons underlying its success have not been thoroughly investigated. In this paper, we provide a comprehensive analysis of $k$NN-MT through theoretical and empirical studies. Initially, we offer a theoretical interpretation of the working mechanism of $k$NN-MT as an efficient technique to implicitly execute gradient descent on the output projection layer of NMT, indicating that it is a specific case of model fine-tuning. Subsequently, we conduct multi-domain experiments and word-level analysis to examine the differences in performance between $k$NN-MT and entire-model fine-tuning. Our findings suggest that: (1) Incorporating $k$NN-MT with adapters yields comparable translation performance to fine-tuning on in-domain test sets, while achieving better performance on out-of-domain test sets; (2) Fine-tuning significantly outperforms $k$NN-MT on the recall of low-frequency domain-specific words, but this gap could be bridged by optimizing the context representations with additional adapter layers.
Fast and Reliable Evaluation of Adversarial Robustness with Minimum-Margin Attack
Jun 15, 2022The AutoAttack (AA) has been the most reliable method to evaluate adversarial robustness when considerable computational resources are available. However, the high computational cost (e.g., 100 times more than that of the project gradient descent attack) makes AA infeasible for practitioners with limited computational resources, and also hinders applications of AA in the adversarial training (AT). In this paper, we propose a novel method, minimum-margin (MM) attack, to fast and reliably evaluate adversarial robustness. Compared with AA, our method achieves comparable performance but only costs 3% of the computational time in extensive experiments. The reliability of our method lies in that we evaluate the quality of adversarial examples using the margin between two targets that can precisely identify the most adversarial example. The computational efficiency of our method lies in an effective Sequential TArget Ranking Selection (STARS) method, ensuring that the cost of the MM attack is independent of the number of classes. The MM attack opens a new way for evaluating adversarial robustness and provides a feasible and reliable way to generate high-quality adversarial examples in AT.
Deep Reinforcement Learning for Solving the Heterogeneous Capacitated Vehicle Routing Problem
Oct 06, 2021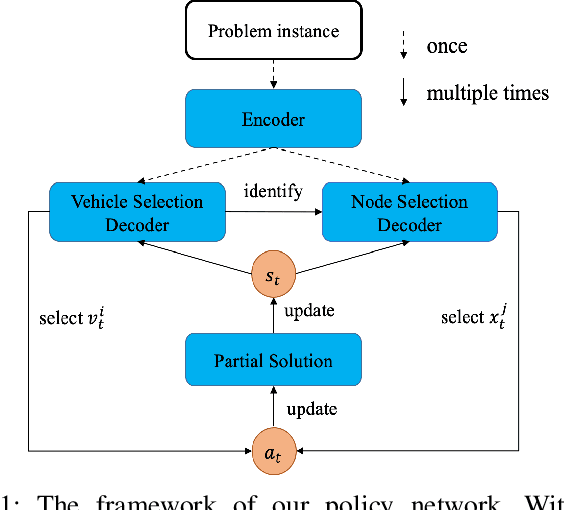
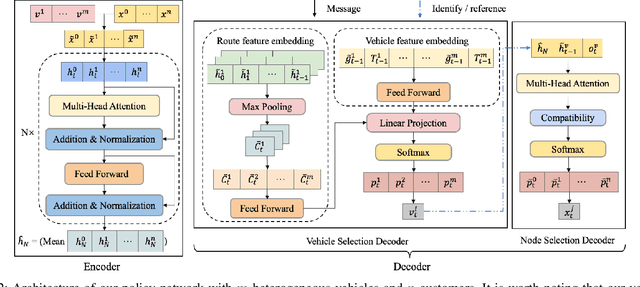
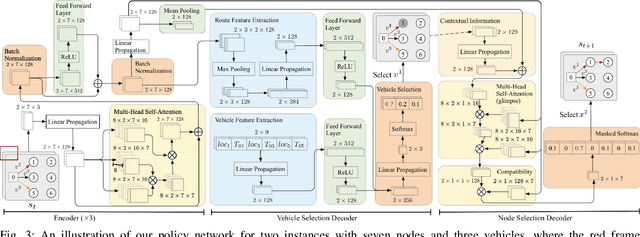
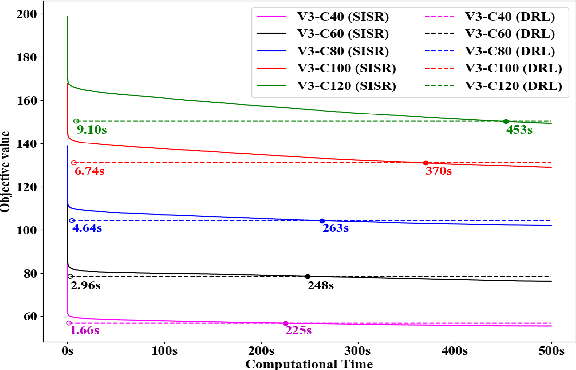
Existing deep reinforcement learning (DRL) based methods for solving the capacitated vehicle routing problem (CVRP) intrinsically cope with homogeneous vehicle fleet, in which the fleet is assumed as repetitions of a single vehicle. Hence, their key to construct a solution solely lies in the selection of the next node (customer) to visit excluding the selection of vehicle. However, vehicles in real-world scenarios are likely to be heterogeneous with different characteristics that affect their capacity (or travel speed), rendering existing DRL methods less effective. In this paper, we tackle heterogeneous CVRP (HCVRP), where vehicles are mainly characterized by different capacities. We consider both min-max and min-sum objectives for HCVRP, which aim to minimize the longest or total travel time of the vehicle(s) in the fleet. To solve those problems, we propose a DRL method based on the attention mechanism with a vehicle selection decoder accounting for the heterogeneous fleet constraint and a node selection decoder accounting for the route construction, which learns to construct a solution by automatically selecting both a vehicle and a node for this vehicle at each step. Experimental results based on randomly generated instances show that, with desirable generalization to various problem sizes, our method outperforms the state-of-the-art DRL method and most of the conventional heuristics, and also delivers competitive performance against the state-of-the-art heuristic method, i.e., SISR. Additionally, the results of extended experiments demonstrate that our method is also able to solve CVRPLib instances with satisfactory performance.