 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRAL: Visual In-Context Reasoning via Analogy in Diffusion Transformers
Feb 03, 2026Replicating In-Context Learning (ICL) in computer vision remains challenging due to task heterogeneity. We propose \textbf{VIRAL}, a framework that elicits visual reasoning from a pre-trained image editing model by formulating ICL as conditional generation via visual analogy ($x_s : x_t :: x_q : y_q$). We adapt a frozen Diffusion Transformer (DiT) using role-aware multi-image conditioning and introduce a Mixture-of-Experts LoRA to mitigate gradient interference across diverse tasks. Additionally, to bridge the gaps in current visual context datasets, we curate a large-scale dataset spanning perception, restoration, and editing. Experiments demonstrate that VIRAL outperforms existing methods, validating that a unified V-ICL paradigm can handle the majority of visual tasks, including open-domain editing. Our code is available at https://anonymous.4open.science/r/VIRAL-744A
Spectral Evolution Search: Efficient Inference-Time Scaling for Reward-Aligned Image Generation
Feb 03, 2026Inference-time scaling offers a versatile paradigm for aligning visual generative models with downstream objectives without parameter updates. However, existing approaches that optimize the high-dimensional initial noise suffer from severe inefficiency, as many search directions exert negligible influence on the final generation. We show that this inefficiency is closely related to a spectral bias in generative dynamics: model sensitivity to initial perturbations diminishes rapidly as frequency increases. Building on this insight, we propose Spectral Evolution Search (SES), a plug-and-play framework for initial noise optimization that executes gradient-free evolutionary search within a low-frequency subspace. Theoretically, we derive the Spectral Scaling Prediction from perturbation propagation dynamics, which explains the systematic differences in the impact of perturbations across frequencies. Extensive experiments demonstrate that SES significantly advances the Pareto frontier of generation quality versus computational cost, consistently outperforming strong baselines under equivalent budgets.
Comprehensive Evaluation and Analysis for NSFW Concept Erasure in Text-to-Image Diffusion Models
May 21, 2025Text-to-image diffusion models have gained widespread application across various domains, demonstrating remarkable creative potential. However, the strong generalization capabilities of diffusion models can inadvertently lead to the generation of not-safe-for-work (NSFW) content, posing significant risks to their safe deployment. While several concept erasure methods have been proposed to mitigate the issue associated with NSFW content, a comprehensive evaluation of their effectiveness across various scenarios remains absent. To bridge this gap, we introduce a full-pipeline toolkit specifically designed for concept erasure and conduct the first systematic study of NSFW concept erasure methods. By examining the interplay between the underlying mechanisms and empirical observations, we provide in-depth insights and practical guidance for the effective application of concept erasure methods in various real-world scenarios, with the aim of advancing the understanding of content safety in diffusion models and establishing a solid foundation for future research and development in this critical area.
Nexus-Gen: A Unified Model for Image Understanding, Generation, and Editing
Apr 30, 2025Unified multimodal large language models (MLLMs) aim to integrate multimodal understanding and generation abilities through a single framework. Despite their versatility, existing open-source unified models exhibit performance gaps against domain-specific architectures. To bridge this gap, we present Nexus-Gen, a unified model that synergizes the language reasoning capabilities of LLMs with the image synthesis power of diffusion models. To align the embedding space of the LLM and diffusion model, we conduct a dual-phase alignment training process. (1) The autoregressive LLM learns to predict image embeddings conditioned on multimodal inputs, while (2) the vision decoder is trained to reconstruct high-fidelity images from these embeddings. During training the LLM, we identified a critical discrepancy between the autoregressive paradigm's training and inference phases, where error accumulation in continuous embedding space severely degrades generation quality. To avoid this issue, we introduce a prefilled autoregression strategy that prefills input sequence with position-embedded special tokens instead of continuous embeddings. Through dual-phase training, Nexus-Gen has developed the integrated capability to comprehensively address the image understanding, generation and editing tasks. All models, datasets, and codes are published at https://github.com/modelscope/Nexus-Gen.git to facilitate further advancements across the field.
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
Apr 24, 2025The Contrastive Language-Image Pre-training (CLIP) framework has become a widely used approach for multimodal representation learning, particularly in image-text retrieval and clustering. However, its efficacy is constrained by three key limitations: (1) text token truncation, (2) isolated image-text encoding, and (3) deficient compositionality due to bag-of-words behavior. While recent Multimodal Large Language Models (MLLMs) have demonstrated significant advances in generalized vision-language understanding, their potential for learning transferable multimodal representations remains underexplored.In this work, we present UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks. In the first stage, we perform textual discriminative knowledge distillation from a powerful LLM-based teacher model to enhance the embedding capability of the MLLM\'s language component. In the second stage, we introduce hard negative enhanced instruction tuning to further advance discriminative representation learning. Specifically, we initially mitigate false negative contamination and then sample multiple hard negatives per instance within each batch, forcing the model to focus on challenging samples. This approach not only improves discriminative power but also enhances instruction-following ability in downstream tasks. We conduct extensive experiments on the MMEB benchmark and multiple retrieval tasks, including short and long caption retrieval and compositional retrieval. Results demonstrate that UniME achieves consistent performance improvement across all tasks, exhibiting superior discriminative and compositional capabilities.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
EliGen: Entity-Level Controlled Image Generation with Regional Attention
Jan 02, 2025



Recent advancements in diffusion models have significantly advanced text-to-image generation, yet global text prompts alone remain insufficient for achieving fine-grained control over individual entities within an image. To address this limitation, we present EliGen, a novel framework for Entity-Level controlled Image Generation. We introduce regional attention, a mechanism for diffusion transformers that requires no additional parameters, seamlessly integrating entity prompts and arbitrary-shaped spatial masks. By contributing a high-quality dataset with fine-grained spatial and semantic entity-level annotations, we train EliGen to achieve robust and accurate entity-level manipulation, surpassing existing methods in both positional control precision and image quality. Additionally, we propose an inpainting fusion pipeline, extending EliGen to multi-entity image inpainting tasks. We further demonstrate its flexibility by integrating it with community models such as IP-Adapter and MLLM, unlocking new creative possibilities. The source code, dataset, and model will be released publicly.
ArtAug: Enhancing Text-to-Image Generation through Synthesis-Understanding Interaction
Dec 18, 2024



The emergence of diffusion models has significantly advanced image synthesis. The recent studies of model interaction and self-corrective reasoning approach in large language models offer new insights for enhancing text-to-image models. Inspired by these studies, we propose a novel method called ArtAug for enhancing text-to-image models in this paper. To the best of our knowledge, ArtAug is the first one that improves image synthesis models via model interactions with understanding models. In the interactions, we leverage human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis models. The interactions can modify the image content to make it aesthetically pleasing, such as adjusting exposure, changing shooting angles, and adding atmospheric effects. The enhancements brought by the interaction are iteratively fused into the synthesis model itself through an additional enhancement module. This enables the synthesis model to directly produce aesthetically pleasing images without any extra computational cost. In the experiments, we train the ArtAug enhancement module on existing text-to-image models. Various evaluation metrics consistently demonstrate that ArtAug enhances the generative capabilities of text-to-image models without incurring additional computational costs. The source code and models will be released publicly.
Minimum Tuning to Unlock Long Output from LLMs with High Quality Data as the Key
Oct 15, 2024As large language models rapidly evolve to support longer context, there is a notable disparity in their capability to generate output at greater lengths. Recent study suggests that the primary cause for this imbalance may arise from the lack of data with long-output during alignment training. In light of this observation, attempts are made to re-align foundation models with data that fills the gap, which result in models capable of generating lengthy output when instructed. In this paper, we explore the impact of data-quality in tuning a model for long output, and the possibility of doing so from the starting points of human-aligned (instruct or chat) models. With careful data curation, we show that it possible to achieve similar performance improvement in our tuned models, with only a small fraction of training data instances and compute. In addition, we assess the generalizability of such approaches by applying our tuning-recipes to several models. our findings suggest that, while capacities for generating long output vary across different models out-of-the-box, our approach to tune them with high-quality data using lite compute, consistently yields notable improvement across all models we experimented on. We have made public our curated dataset for tuning long-writing capability, the implementations of model tuning and evaluation, as well as the fine-tuned models, all of which can be openly-accessed.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024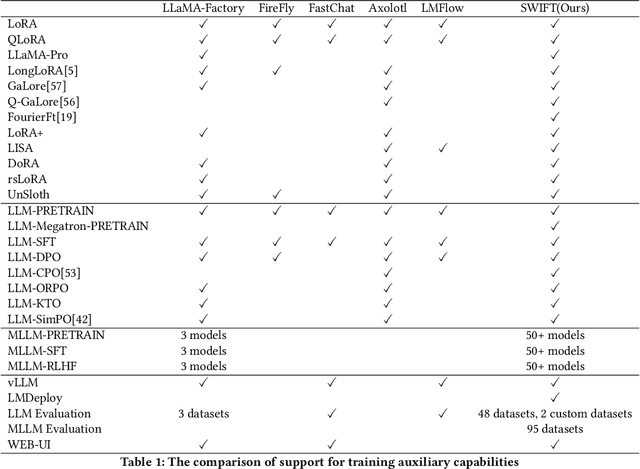
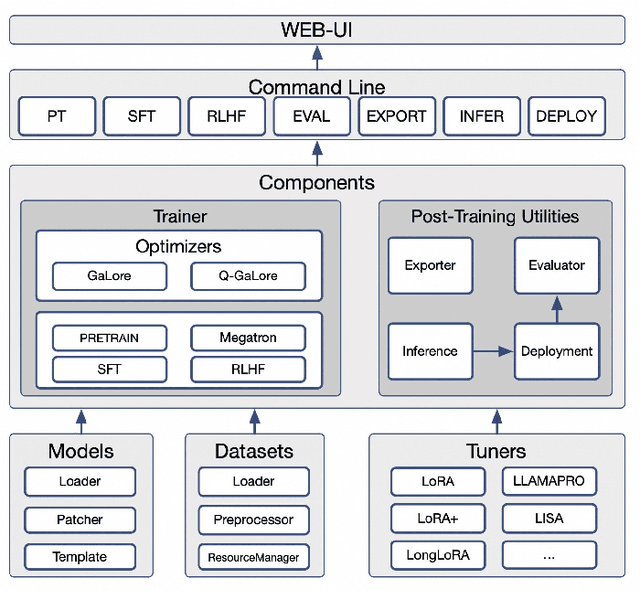


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.