 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Evolution Search: Efficient Inference-Time Scaling for Reward-Aligned Image Generation
Feb 03, 2026Inference-time scaling offers a versatile paradigm for aligning visual generative models with downstream objectives without parameter updates. However, existing approaches that optimize the high-dimensional initial noise suffer from severe inefficiency, as many search directions exert negligible influence on the final generation. We show that this inefficiency is closely related to a spectral bias in generative dynamics: model sensitivity to initial perturbations diminishes rapidly as frequency increases. Building on this insight, we propose Spectral Evolution Search (SES), a plug-and-play framework for initial noise optimization that executes gradient-free evolutionary search within a low-frequency subspace. Theoretically, we derive the Spectral Scaling Prediction from perturbation propagation dynamics, which explains the systematic differences in the impact of perturbations across frequencies. Extensive experiments demonstrate that SES significantly advances the Pareto frontier of generation quality versus computational cost, consistently outperforming strong baselines under equivalent budgets.
VIRAL: Visual In-Context Reasoning via Analogy in Diffusion Transformers
Feb 03, 2026Replicating In-Context Learning (ICL) in computer vision remains challenging due to task heterogeneity. We propose \textbf{VIRAL}, a framework that elicits visual reasoning from a pre-trained image editing model by formulating ICL as conditional generation via visual analogy ($x_s : x_t :: x_q : y_q$). We adapt a frozen Diffusion Transformer (DiT) using role-aware multi-image conditioning and introduce a Mixture-of-Experts LoRA to mitigate gradient interference across diverse tasks. Additionally, to bridge the gaps in current visual context datasets, we curate a large-scale dataset spanning perception, restoration, and editing. Experiments demonstrate that VIRAL outperforms existing methods, validating that a unified V-ICL paradigm can handle the majority of visual tasks, including open-domain editing. Our code is available at https://anonymous.4open.science/r/VIRAL-744A
Responsible Diffusion Models via Constraining Text Embeddings within Safe Regions
May 21, 2025The remarkable ability of diffusion models to generate high-fidelity images has led to their widespread adoption. However, concerns have also arisen regarding their potential to produce Not Safe for Work (NSFW) content and exhibit social biases, hindering their practical use in real-world applications. In response to this challenge, prior work has focused on employing security filters to identify and exclude toxic text, or alternatively, fine-tuning pre-trained diffusion models to erase sensitive concepts. Unfortunately, existing methods struggle to achieve satisfactory performance in the sense that they can have a significant impact on the normal model output while still failing to prevent the generation of harmful content in some cases. In this paper, we propose a novel self-discovery approach to identifying a semantic direction vector in the embedding space to restrict text embedding within a safe region. Our method circumvents the need for correcting individual words within the input text and steers the entire text prompt towards a safe region in the embedding space, thereby enhancing model robustness against all possibly unsafe prompts. In addition, we employ Low-Rank Adaptation (LoRA) for semantic direction vector initialization to reduce the impact on the model performance for other semantics. Furthermore, our method can also be integrated with existing methods to improve their social responsibility. Extensive experiments on benchmark datasets demonstrate that our method can effectively reduce NSFW content and mitigate social bias generated by diffusion models compared to several state-of-the-art baselines.
Comprehensive Evaluation and Analysis for NSFW Concept Erasure in Text-to-Image Diffusion Models
May 21, 2025Text-to-image diffusion models have gained widespread application across various domains, demonstrating remarkable creative potential. However, the strong generalization capabilities of diffusion models can inadvertently lead to the generation of not-safe-for-work (NSFW) content, posing significant risks to their safe deployment. While several concept erasure methods have been proposed to mitigate the issue associated with NSFW content, a comprehensive evaluation of their effectiveness across various scenarios remains absent. To bridge this gap, we introduce a full-pipeline toolkit specifically designed for concept erasure and conduct the first systematic study of NSFW concept erasure methods. By examining the interplay between the underlying mechanisms and empirical observations, we provide in-depth insights and practical guidance for the effective application of concept erasure methods in various real-world scenarios, with the aim of advancing the understanding of content safety in diffusion models and establishing a solid foundation for future research and development in this critical area.
Comprehensive Assessment and Analysis for NSFW Content Erasure in Text-to-Image Diffusion Models
Feb 18, 2025Text-to-image (T2I) diffusion models have gained widespread application across various domains, demonstrating remarkable creative potential. However, the strong generalization capabilities of these models can inadvertently led they to generate NSFW content even with efforts on filtering NSFW content from the training dataset, posing risks to their safe deployment. While several concept erasure methods have been proposed to mitigate this issue, a comprehensive evaluation of their effectiveness remains absent. To bridge this gap, we present the first systematic investigation of concept erasure methods for NSFW content and its sub-themes in text-to-image diffusion models. At the task level, we provide a holistic evaluation of 11 state-of-the-art baseline methods with 14 variants. Specifically, we analyze these methods from six distinct assessment perspectives, including three conventional perspectives, i.e., erasure proportion, image quality, and semantic alignment, and three new perspectives, i.e., excessive erasure, the impact of explicit and implicit unsafe prompts, and robustness. At the tool level, we perform a detailed toxicity analysis of NSFW datasets and compare the performance of different NSFW classifiers, offering deeper insights into their performance alongside a compilation of comprehensive evaluation metrics. Our benchmark not only systematically evaluates concept erasure methods, but also delves into the underlying factors influencing their performance at the insight level. By synthesizing insights from various evaluation perspectives, we provide a deeper understanding of the challenges and opportunities in the field, offering actionable guidance and inspiration for advancing research and practical applications in concept erasure.
EIUP: A Training-Free Approach to Erase Non-Compliant Concepts Conditioned on Implicit Unsafe Prompts
Aug 02, 2024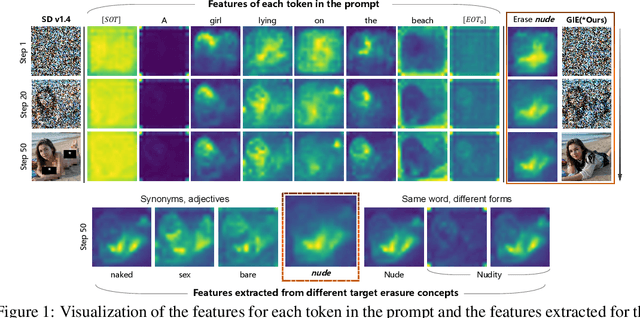

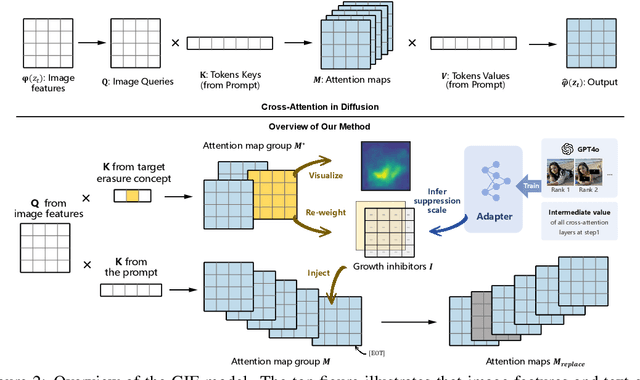

Text-to-image diffusion models have shown the ability to learn a diverse range of concepts. However, it is worth noting that they may also generate undesirable outputs, consequently giving rise to significant security concerns. Specifically, issues such as Not Safe for Work (NSFW) content and potential violations of style copyright may be encountered. Since image generation is conditioned on text, prompt purification serves as a straightforward solution for content safety. Similar to the approach taken by LLM, some efforts have been made to control the generation of safe outputs by purifying prompts. However, it is also important to note that even with these efforts, non-toxic text still carries a risk of generating non-compliant images, which is referred to as implicit unsafe prompts. Furthermore, some existing works fine-tune the models to erase undesired concepts from model weights. This type of method necessitates multiple training iterations whenever the concept is updated, which can be time-consuming and may potentially lead to catastrophic forgetting. To address these challenges, we propose a simple yet effective approach that incorporates non-compliant concepts into an erasure prompt. This erasure prompt proactively participates in the fusion of image spatial features and text embeddings. Through attention mechanisms, our method is capable of identifying feature representations of non-compliant concepts in the image space. We re-weight these features to effectively suppress the generation of unsafe images conditioned on original implicit unsafe prompts. Our method exhibits superior erasure effectiveness while achieving high scores in image fidelity compared to the state-of-the-art baselines. WARNING: This paper contains model outputs that may be offensive.
XFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Learning robot inverse dynamics using sparse online Gaussian process with forgetting mechanism
Aug 06, 2022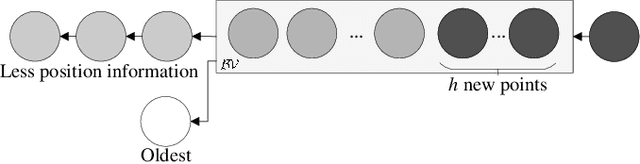
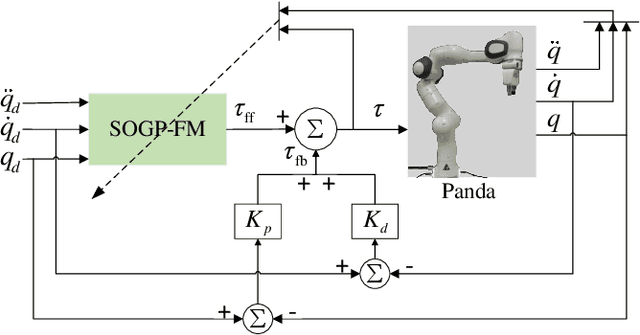
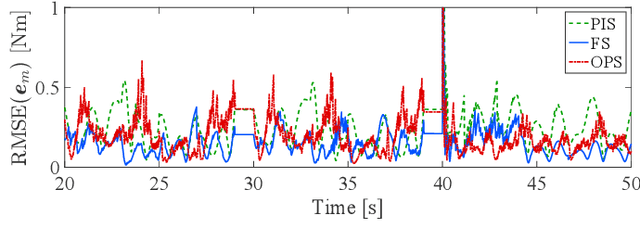
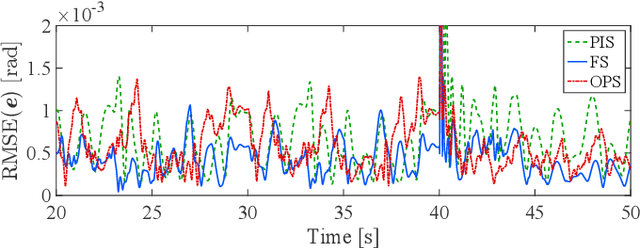
Online Gaussian processes (GPs), typically used for learning models from time-series data, are more flexible and robust than offline GPs. Both local and sparse approximations of GPs can efficiently learn complex models online. Yet, these approaches assume that all signals are relatively accurate and that all data are available for learning without misleading data. Besides, the online learning capacity of GPs is limited for high-dimension problems and long-term tasks in practice. This paper proposes a sparse online GP (SOGP) with a forgetting mechanism to forget distant model information at a specific rate. The proposed approach combines two general data deletion schemes for the basis vector set of SOGP: The position information-based scheme and the oldest points-based scheme. We apply our approach to learn the inverse dynamics of a collaborative robot with 7 degrees of freedom under a two-segment trajectory tracking problem with task switching. Both simulations and experiments have shown that the proposed approach achieves better tracking accuracy and predictive smoothness compared with the two general data deletion schemes.
A Learning Framework for Diffeomorphic Image Registration based on Quasi-conformal Geometry
Oct 20, 2021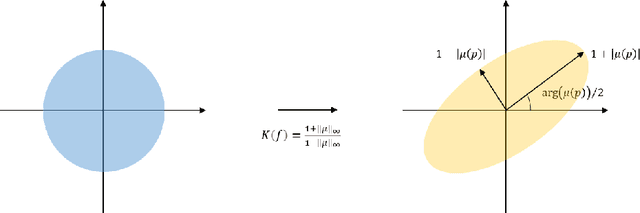
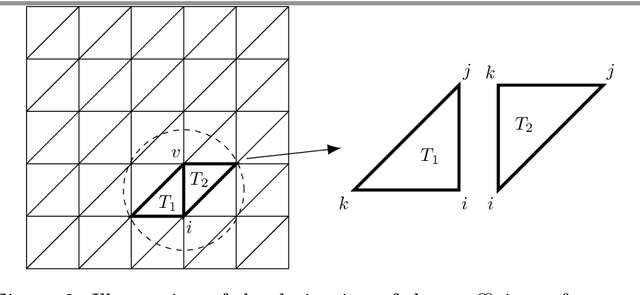
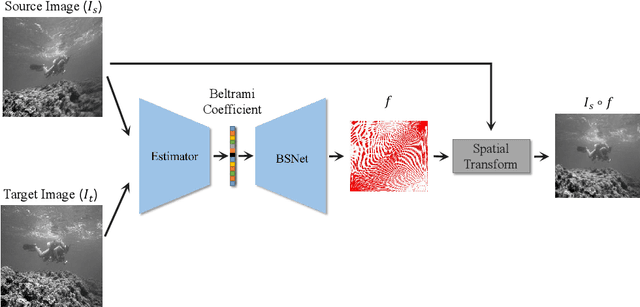
Image registration, the process of defining meaningful correspondences between images, is essential for various image analysis tasks, especially medical imaging. Numerous learning-based methods, notably convolutional neural networks (CNNs), for deformable image registration proposed in recent years have demonstrated the feasibility and superiority of deep learning techniques for registration problems. Besides, compared to traditional algorithms' optimization scheme of the objective function for each image pair, learning-based algorithms are several orders of magnitude faster. However, these data-driven methods without proper constraint on the deformation field will easily lead to topological foldings. To tackle this problem, We propose the quasi-conformal registration network (QCRegNet), an unsupervised learning framework, to obtain diffeomorphic 2D image registrations with large deformations based on quasi-conformal (QC) map, an orientation-preserving homeomorphism between two manifolds. The basic idea is to design a CNN mapping image pairs to deformation fields. QCRegNet consists of the estimator network and the Beltrami solver network (BSNet). The estimator network takes image pair as input and outputs the Beltrami coefficient (BC). The BC, which captures conformal distortion of a QC map and guarantees the bijectivity, will then be input to the BSNet, a task-independent network which reconstructs the desired QC map. Furthermore, we reduce the number of network parameters and computational complexity by utilizing Fourier approximation to compress BC. Experiments have been carried out on different data such as underwater and medical images. Registration results show that the registration accuracy is comparable to state-of-the-art methods and diffeomorphism is to a great extent guaranteed compared to other diffeomorphic registration algorithms.