 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIUP: A Training-Free Approach to Erase Non-Compliant Concepts Conditioned on Implicit Unsafe Prompts
Paper and Code
Aug 02, 2024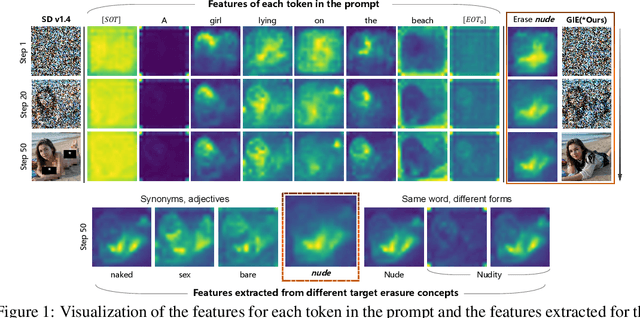

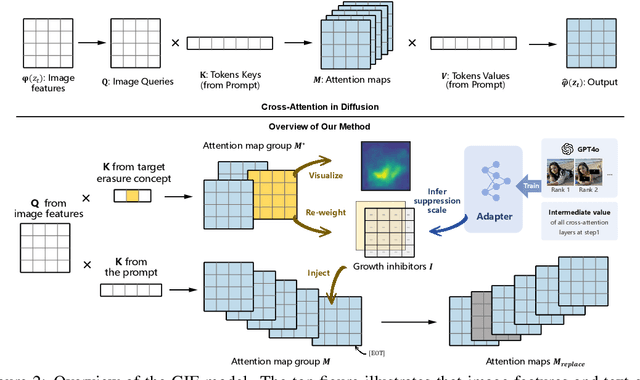

Text-to-image diffusion models have shown the ability to learn a diverse range of concepts. However, it is worth noting that they may also generate undesirable outputs, consequently giving rise to significant security concerns. Specifically, issues such as Not Safe for Work (NSFW) content and potential violations of style copyright may be encountered. Since image generation is conditioned on text, prompt purification serves as a straightforward solution for content safety. Similar to the approach taken by LLM, some efforts have been made to control the generation of safe outputs by purifying prompts. However, it is also important to note that even with these efforts, non-toxic text still carries a risk of generating non-compliant images, which is referred to as implicit unsafe prompts. Furthermore, some existing works fine-tune the models to erase undesired concepts from model weights. This type of method necessitates multiple training iterations whenever the concept is updated, which can be time-consuming and may potentially lead to catastrophic forgetting. To address these challenges, we propose a simple yet effective approach that incorporates non-compliant concepts into an erasure prompt. This erasure prompt proactively participates in the fusion of image spatial features and text embeddings. Through attention mechanisms, our method is capable of identifying feature representations of non-compliant concepts in the image space. We re-weight these features to effectively suppress the generation of unsafe images conditioned on original implicit unsafe prompts. Our method exhibits superior erasure effectiveness while achieving high scores in image fidelity compared to the state-of-the-art baselines. WARNING: This paper contains model outputs that may be offensive.