 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Wan-Image: Pushing the Boundaries of Generative Visual Intelligence
Apr 21, 2026We present Wan-Image, a unified visual generation system explicitly engineered to paradigm-shift image generation models from casual synthesizers into professional-grade productivity tools. While contemporary diffusion models excel at aesthetic generation, they frequently encounter critical bottlenecks in rigorous design workflows that demand absolute controllability, complex typography rendering, and strict identity preservation. To address these challenges, Wan-Image features a natively unified multi-modal architecture by synergizing the cognitive capabilities of large language models with the high-fidelity pixel synthesis of diffusion transformers, which seamlessly translates highly nuanced user intents into precise visual outputs. It is fundamentally powered by large-scale multi-modal data scaling, a systematic fine-grained annotation engine, and curated reinforcement learning data to surpass basic instruction following and unlock expert-level professional capabilities. These include ultra-long complex text rendering, hyper-diverse portrait generation, palette-guided generation, multi-subject identity preservation, coherent sequential visual generation, precise multi-modal interactive editing, native alpha-channel generation, and high-efficiency 4K synthesis. Across diverse human evaluations, Wan-Image exceeds Seedream 5.0 Lite and GPT Image 1.5 in overall performance, reaching parity with Nano Banana Pro in challenging tasks. Ultimately, Wan-Image revolutionizes visual content creation across e-commerce, entertainment, education, and personal productivity, redefining the boundaries of professional visual synthesis.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Responsible Diffusion Models via Constraining Text Embeddings within Safe Regions
May 21, 2025The remarkable ability of diffusion models to generate high-fidelity images has led to their widespread adoption. However, concerns have also arisen regarding their potential to produce Not Safe for Work (NSFW) content and exhibit social biases, hindering their practical use in real-world applications. In response to this challenge, prior work has focused on employing security filters to identify and exclude toxic text, or alternatively, fine-tuning pre-trained diffusion models to erase sensitive concepts. Unfortunately, existing methods struggle to achieve satisfactory performance in the sense that they can have a significant impact on the normal model output while still failing to prevent the generation of harmful content in some cases. In this paper, we propose a novel self-discovery approach to identifying a semantic direction vector in the embedding space to restrict text embedding within a safe region. Our method circumvents the need for correcting individual words within the input text and steers the entire text prompt towards a safe region in the embedding space, thereby enhancing model robustness against all possibly unsafe prompts. In addition, we employ Low-Rank Adaptation (LoRA) for semantic direction vector initialization to reduce the impact on the model performance for other semantics. Furthermore, our method can also be integrated with existing methods to improve their social responsibility. Extensive experiments on benchmark datasets demonstrate that our method can effectively reduce NSFW content and mitigate social bias generated by diffusion models compared to several state-of-the-art baselines.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ArtAug: Enhancing Text-to-Image Generation through Synthesis-Understanding Interaction
Dec 18, 2024



The emergence of diffusion models has significantly advanced image synthesis. The recent studies of model interaction and self-corrective reasoning approach in large language models offer new insights for enhancing text-to-image models. Inspired by these studies, we propose a novel method called ArtAug for enhancing text-to-image models in this paper. To the best of our knowledge, ArtAug is the first one that improves image synthesis models via model interactions with understanding models. In the interactions, we leverage human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis models. The interactions can modify the image content to make it aesthetically pleasing, such as adjusting exposure, changing shooting angles, and adding atmospheric effects. The enhancements brought by the interaction are iteratively fused into the synthesis model itself through an additional enhancement module. This enables the synthesis model to directly produce aesthetically pleasing images without any extra computational cost. In the experiments, we train the ArtAug enhancement module on existing text-to-image models. Various evaluation metrics consistently demonstrate that ArtAug enhances the generative capabilities of text-to-image models without incurring additional computational costs. The source code and models will be released publicly.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024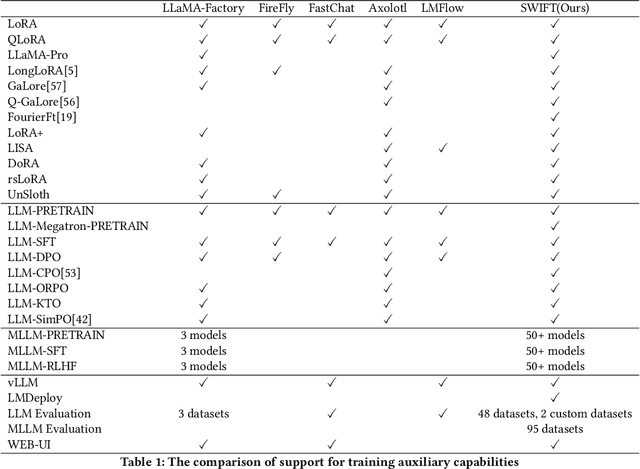
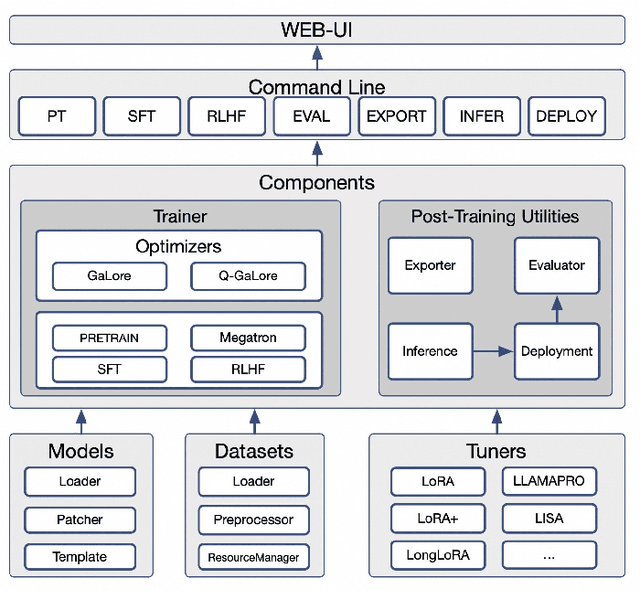


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases
Aug 07, 2024



Large Language Models (LLMs) excel in stand-alone code tasks like HumanEval and MBPP, but struggle with handling entire code repositories. This challenge has prompted research on enhancing LLM-codebase interaction at a repository scale. Current solutions rely on similarity-based retrieval or manual tools and APIs, each with notable drawbacks. Similarity-based retrieval often has low recall in complex tasks, while manual tools and APIs are typically task-specific and require expert knowledge, reducing their generalizability across diverse code tasks and real-world applications. To mitigate these limitations, we introduce \framework, a system that integrates LLM agents with graph database interfaces extracted from code repositories. By leveraging the structural properties of graph databases and the flexibility of the graph query language, \framework enables the LLM agent to construct and execute queries, allowing for precise, code structure-aware context retrieval and code navigation. We assess \framework using three benchmarks: CrossCodeEval, SWE-bench, and EvoCodeBench. Additionally, we develop five real-world coding applications. With a unified graph database schema, \framework demonstrates competitive performance and potential in both academic and real-world environments, showcasing its versatility and efficacy in software engineering. Our application demo: https://github.com/modelscope/modelscope-agent/tree/master/apps/codexgraph_agent.
EIUP: A Training-Free Approach to Erase Non-Compliant Concepts Conditioned on Implicit Unsafe Prompts
Aug 02, 2024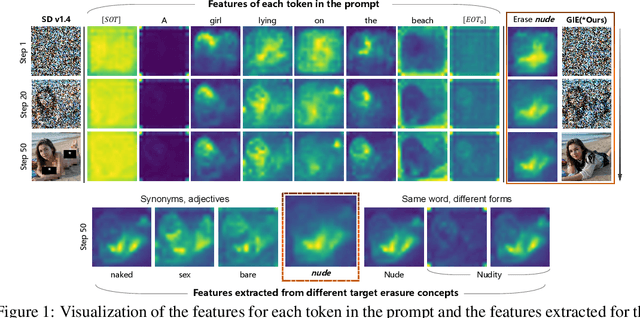

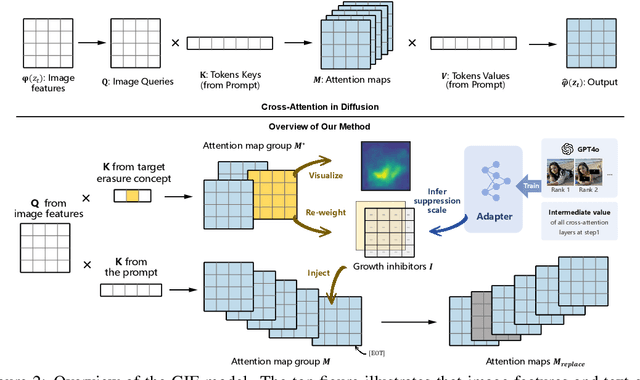

Text-to-image diffusion models have shown the ability to learn a diverse range of concepts. However, it is worth noting that they may also generate undesirable outputs, consequently giving rise to significant security concerns. Specifically, issues such as Not Safe for Work (NSFW) content and potential violations of style copyright may be encountered. Since image generation is conditioned on text, prompt purification serves as a straightforward solution for content safety. Similar to the approach taken by LLM, some efforts have been made to control the generation of safe outputs by purifying prompts. However, it is also important to note that even with these efforts, non-toxic text still carries a risk of generating non-compliant images, which is referred to as implicit unsafe prompts. Furthermore, some existing works fine-tune the models to erase undesired concepts from model weights. This type of method necessitates multiple training iterations whenever the concept is updated, which can be time-consuming and may potentially lead to catastrophic forgetting. To address these challenges, we propose a simple yet effective approach that incorporates non-compliant concepts into an erasure prompt. This erasure prompt proactively participates in the fusion of image spatial features and text embeddings. Through attention mechanisms, our method is capable of identifying feature representations of non-compliant concepts in the image space. We re-weight these features to effectively suppress the generation of unsafe images conditioned on original implicit unsafe prompts. Our method exhibits superior erasure effectiveness while achieving high scores in image fidelity compared to the state-of-the-art baselines. WARNING: This paper contains model outputs that may be offensive.
ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning
Jun 20, 2024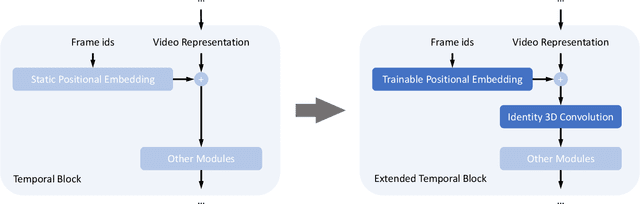



Recently, advancements in video synthesis have attracted significant attention. Video synthesis models such as AnimateDiff and Stable Video Diffusion have demonstrated the practical applicability of diffusion models in creating dynamic visual content. The emergence of SORA has further spotlighted the potential of video generation technologies. Nonetheless, the extension of video lengths has been constrained by the limitations in computational resources. Most existing video synthesis models can only generate short video clips. In this paper, we propose a novel post-tuning methodology for video synthesis models, called ExVideo. This approach is designed to enhance the capability of current video synthesis models, allowing them to produce content over extended temporal durations while incurring lower training expenditures. In particular, we design extension strategies across common temporal model architectures respectively, including 3D convolution, temporal attention, and positional embedding. To evaluate the efficacy of our proposed post-tuning approach, we conduct extension training on the Stable Video Diffusion model. Our approach augments the model's capacity to generate up to $5\times$ its original number of frames, requiring only 1.5k GPU hours of training on a dataset comprising 40k videos. Importantly, the substantial increase in video length doesn't compromise the model's innate generalization capabilities, and the model showcases its advantages in generating videos of diverse styles and resolutions. We will release the source code and the enhanced model publicly.