 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute to Reason: Adaptive Routing for LLM and Reasoning Strategy Selection
May 26, 2025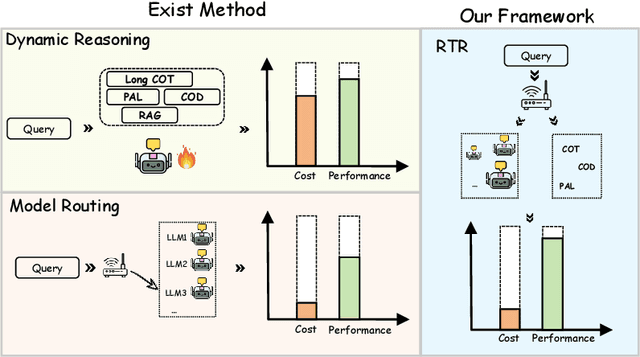
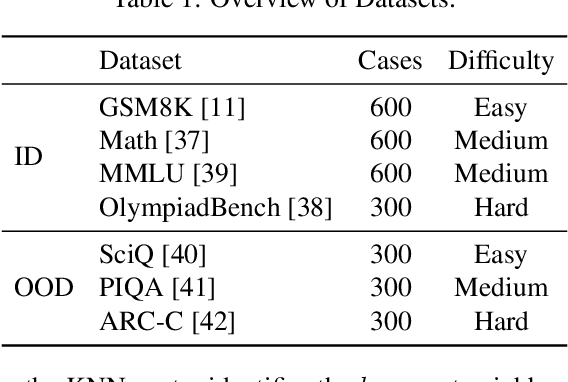
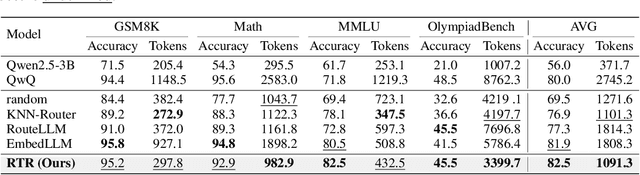
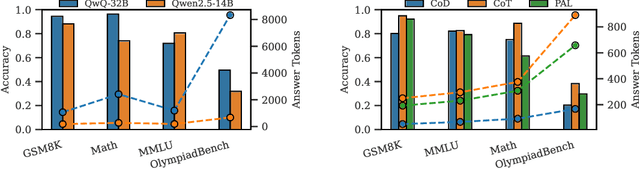
The inherent capabilities of a language model (LM) and the reasoning strategies it employs jointly determine its performance in reasoning tasks. While test-time scaling is regarded as an effective approach to tackling complex reasoning tasks, it incurs substantial computational costs and often leads to "overthinking", where models become trapped in "thought pitfalls". To address this challenge, we propose Route-To-Reason (RTR), a novel unified routing framework that dynamically allocates both LMs and reasoning strategies according to task difficulty under budget constraints. RTR learns compressed representations of both expert models and reasoning strategies, enabling their joint and adaptive selection at inference time. This method is low-cost, highly flexible, and can be seamlessly extended to arbitrary black-box or white-box models and strategies, achieving true plug-and-play functionality. Extensive experiments across seven open source models and four reasoning strategies demonstrate that RTR achieves an optimal trade-off between accuracy and computational efficiency among all baselines, achieving higher accuracy than the best single model while reducing token usage by over 60%.
Nexus-Gen: A Unified Model for Image Understanding, Generation, and Editing
Apr 30, 2025Unified multimodal large language models (MLLMs) aim to integrate multimodal understanding and generation abilities through a single framework. Despite their versatility, existing open-source unified models exhibit performance gaps against domain-specific architectures. To bridge this gap, we present Nexus-Gen, a unified model that synergizes the language reasoning capabilities of LLMs with the image synthesis power of diffusion models. To align the embedding space of the LLM and diffusion model, we conduct a dual-phase alignment training process. (1) The autoregressive LLM learns to predict image embeddings conditioned on multimodal inputs, while (2) the vision decoder is trained to reconstruct high-fidelity images from these embeddings. During training the LLM, we identified a critical discrepancy between the autoregressive paradigm's training and inference phases, where error accumulation in continuous embedding space severely degrades generation quality. To avoid this issue, we introduce a prefilled autoregression strategy that prefills input sequence with position-embedded special tokens instead of continuous embeddings. Through dual-phase training, Nexus-Gen has developed the integrated capability to comprehensively address the image understanding, generation and editing tasks. All models, datasets, and codes are published at https://github.com/modelscope/Nexus-Gen.git to facilitate further advancements across the field.
Unveiling the Magic of Code Reasoning through Hypothesis Decomposition and Amendment
Feb 17, 2025The reasoning abilities are one of the most enigmatic and captivating aspects of large language models (LLMs). Numerous studies are dedicated to exploring and expanding the boundaries of this reasoning capability. However, tasks that embody both reasoning and recall characteristics are often overlooked. In this paper, we introduce such a novel task, code reasoning, to provide a new perspective for the reasoning abilities of LLMs. We summarize three meta-benchmarks based on established forms of logical reasoning, and instantiate these into eight specific benchmark tasks. Our testing on these benchmarks reveals that LLMs continue to struggle with identifying satisfactory reasoning pathways. Additionally, we present a new pathway exploration pipeline inspired by human intricate problem-solving methods. This Reflective Hypothesis Decomposition and Amendment (RHDA) pipeline consists of the following iterative steps: (1) Proposing potential hypotheses based on observations and decomposing them; (2) Utilizing tools to validate hypotheses and reflection outcomes; (3) Revising hypothesis in light of observations. Our approach effectively mitigates logical chain collapses arising from forgetting or hallucination issues in multi-step reasoning, resulting in performance gains of up to $3\times$. Finally, we expanded this pipeline by applying it to simulate complex household tasks in real-world scenarios, specifically in VirtualHome, enhancing the handling of failure cases. We release our code and all of results at https://github.com/TnTWoW/code_reasoning.
DisenTS: Disentangled Channel Evolving Pattern Modeling for Multivariate Time Series Forecasting
Oct 30, 2024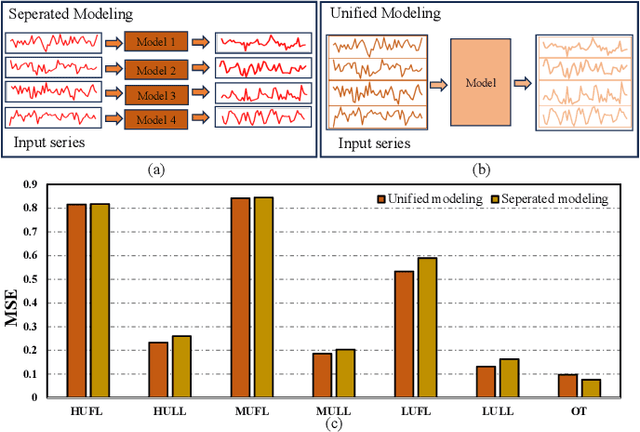
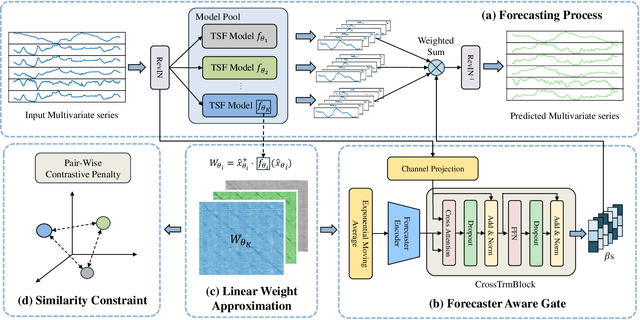

Multivariate time series forecasting plays a crucial role in various real-world applications. Significant efforts have been made to integrate advanced network architectures and training strategies that enhance the capture of temporal dependencies, thereby improving forecasting accuracy. On the other hand, mainstream approaches typically utilize a single unified model with simplistic channel-mixing embedding or cross-channel attention operations to account for the critical intricate inter-channel dependencies. Moreover, some methods even trade capacity for robust prediction based on the channel-independent assumption. Nonetheless, as time series data may display distinct evolving patterns due to the unique characteristics of each channel (including multiple strong seasonalities and trend changes), the unified modeling methods could yield suboptimal results. To this end, we propose DisenTS, a tailored framework for modeling disentangled channel evolving patterns in general multivariate time series forecasting. The central idea of DisenTS is to model the potential diverse patterns within the multivariate time series data in a decoupled manner. Technically, the framework employs multiple distinct forecasting models, each tasked with uncovering a unique evolving pattern. To guide the learning process without supervision of pattern partition, we introduce a novel Forecaster Aware Gate (FAG) module that generates the routing signals adaptively according to both the forecasters' states and input series' characteristics. The forecasters' states are derived from the Linear Weight Approximation (LWA) strategy, which quantizes the complex deep neural networks into compact matrices. Additionally, the Similarity Constraint (SC) is further proposed to guide each model to specialize in an underlying pattern by minimizing the mutual information between the representations.
Minimum Tuning to Unlock Long Output from LLMs with High Quality Data as the Key
Oct 15, 2024As large language models rapidly evolve to support longer context, there is a notable disparity in their capability to generate output at greater lengths. Recent study suggests that the primary cause for this imbalance may arise from the lack of data with long-output during alignment training. In light of this observation, attempts are made to re-align foundation models with data that fills the gap, which result in models capable of generating lengthy output when instructed. In this paper, we explore the impact of data-quality in tuning a model for long output, and the possibility of doing so from the starting points of human-aligned (instruct or chat) models. With careful data curation, we show that it possible to achieve similar performance improvement in our tuned models, with only a small fraction of training data instances and compute. In addition, we assess the generalizability of such approaches by applying our tuning-recipes to several models. our findings suggest that, while capacities for generating long output vary across different models out-of-the-box, our approach to tune them with high-quality data using lite compute, consistently yields notable improvement across all models we experimented on. We have made public our curated dataset for tuning long-writing capability, the implementations of model tuning and evaluation, as well as the fine-tuned models, all of which can be openly-accessed.
RePair: Automated Program Repair with Process-based Feedback
Aug 21, 2024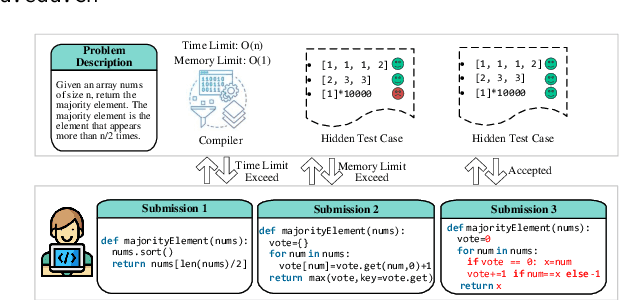

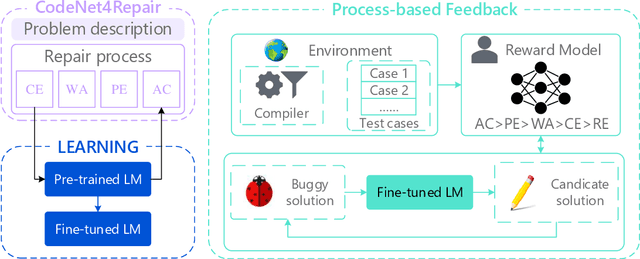

The gap between the trepidation of program reliability and the expense of repairs underscores the indispensability of Automated Program Repair (APR). APR is instrumental in transforming vulnerable programs into more robust ones, bolstering program reliability while simultaneously diminishing the financial burden of manual repairs. Commercial-scale language models (LM) have taken APR to unprecedented levels. However, the emergence reveals that for models fewer than 100B parameters, making single-step modifications may be difficult to achieve the desired effect. Moreover, humans interact with the LM through explicit prompts, which hinders the LM from receiving feedback from compiler and test cases to automatically optimize its repair policies. In this literature, we explore how small-scale LM (less than 20B) achieve excellent performance through process supervision and feedback. We start by constructing a dataset named CodeNet4Repair, replete with multiple repair records, which supervises the fine-tuning of a foundational model. Building upon the encouraging outcomes of reinforcement learning, we develop a reward model that serves as a critic, providing feedback for the fine-tuned LM's action, progressively optimizing its policy. During inference, we require the LM to generate solutions iteratively until the repair effect no longer improves or hits the maximum step limit. The results show that process-based not only outperforms larger outcome-based generation methods, but also nearly matches the performance of closed-source commercial large-scale LMs.
* 15 pages, 13 figures
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024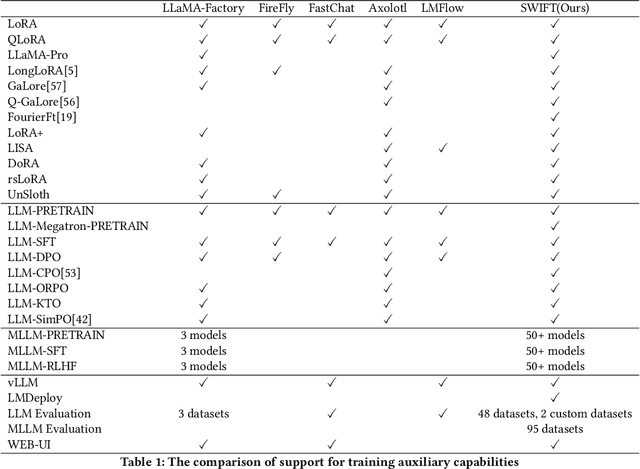
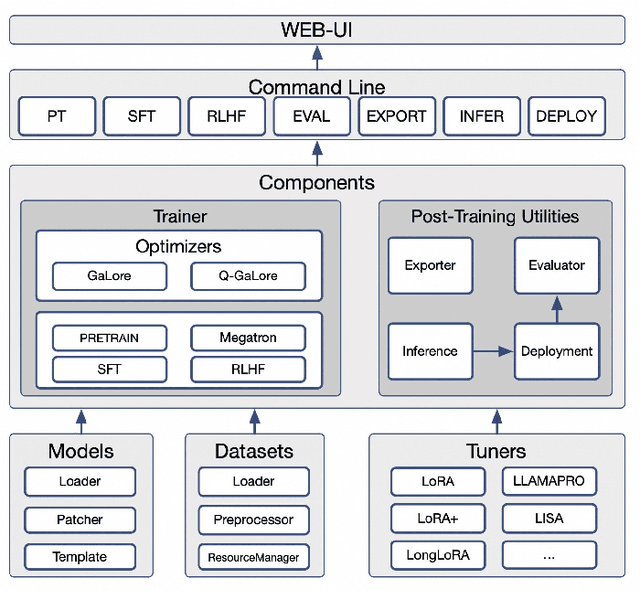


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023



Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
A New Clustering neural network for Chinese word segmentation
Feb 18, 2020
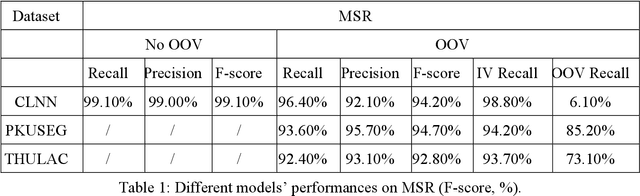


In this article I proposed a new model to achieve Chinese word segmentation(CWS),which may have the potentiality to apply in other domains in the future.It is a new thinking in CWS compared to previous works,to consider it as a clustering problem instead of a labeling problem.In this model,LSTM and self attention structures are used to collect context also sentence level features in every layer,and after several layers,a clustering model is applied to split characters into groups,which are the final segmentation results.I call this model CLNN.This algorithm can reach 98 percent of F score (without OOV words) and 85 percent to 95 percent F score (with OOV words) in training data sets.Error analyses shows that OOV words will greatly reduce performances,which needs a deeper research in the future.