 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKuaiSearch: A Large-Scale E-Commerce Search Dataset for Recall, Ranking, and Relevance
Feb 12, 2026E-commerce search serves as a central interface, connecting user demands with massive product inventories and plays a vital role in our daily lives. However, in real-world applications, it faces challenges, including highly ambiguous queries, noisy product texts with weak semantic order, and diverse user preferences, all of which make it difficult to accurately capture user intent and fine-grained product semantics. In recent years, significant advances in large language models (LLMs) for semantic representation and contextual reasoning have created new opportunities to address these challenges. Nevertheless, existing e-commerce search datasets still suffer from notable limitations: queries are often heuristically constructed, cold-start users and long-tail products are filtered out, query and product texts are anonymized, and most datasets cover only a single stage of the search pipeline. Collectively, these issues constrain research on LLM-based e-commerce search. To address these challenges, we construct and release KuaiSearch. To the best of our knowledge, it is the largest e-commerce search dataset currently available. KuaiSearch is built upon real user search interactions from the Kuaishou platform, preserving authentic user queries and natural-language product texts, covering cold-start users and long-tail products, and systematically spanning three key stages of the search pipeline: recall, ranking, and relevance judgment. We conduct a comprehensive analysis of KuaiSearch from multiple perspectives, including products, users, and queries, and establish benchmark experiments across several representative search tasks. Experimental results demonstrate that KuaiSearch provides a valuable foundation for research on real-world e-commerce search.
Preference Trajectory Modeling via Flow Matching for Sequential Recommendation
Aug 25, 2025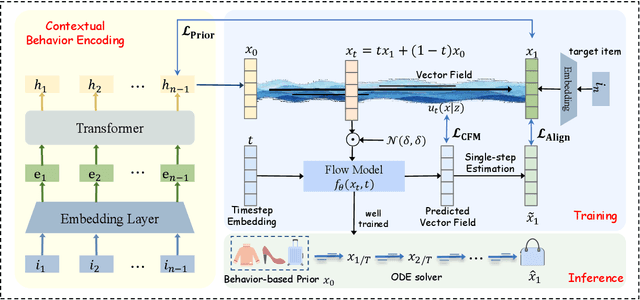
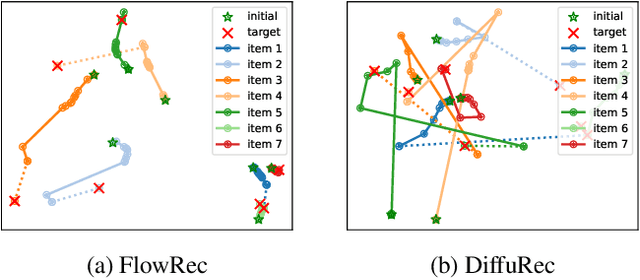
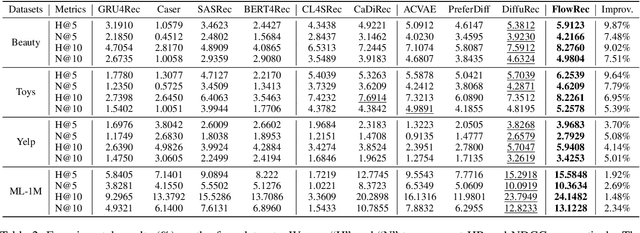
Sequential recommendation predicts each user's next item based on their historical interaction sequence. Recently, diffusion models have attracted significant attention in this area due to their strong ability to model user interest distributions. They typically generate target items by denoising Gaussian noise conditioned on historical interactions. However, these models face two critical limitations. First, they exhibit high sensitivity to the condition, making it difficult to recover target items from pure Gaussian noise. Second, the inference process is computationally expensive, limiting practical deployment. To address these issues, we propose FlowRec, a simple yet effective sequential recommendation framework which leverages flow matching to explicitly model user preference trajectories from current states to future interests. Flow matching is an emerging generative paradigm, which offers greater flexibility in initial distributions and enables more efficient sampling. Based on this, we construct a personalized behavior-based prior distribution to replace Gaussian noise and learn a vector field to model user preference trajectories. To better align flow matching with the recommendation objective, we further design a single-step alignment loss incorporating both positive and negative samples, improving sampling efficiency and generation quality. Extensive experiments on four benchmark datasets verify the superiority of FlowRec over the state-of-the-art baselines.
Improving Time Series Forecasting via Instance-aware Post-hoc Revision
May 29, 2025Time series forecasting plays a vital role in various real-world applications and has attracted significant attention in recent decades. While recent methods have achieved remarkable accuracy by incorporating advanced inductive biases and training strategies, we observe that instance-level variations remain a significant challenge. These variations--stemming from distribution shifts, missing data, and long-tail patterns--often lead to suboptimal forecasts for specific instances, even when overall performance appears strong. To address this issue, we propose a model-agnostic framework, PIR, designed to enhance forecasting performance through Post-forecasting Identification and Revision. Specifically, PIR first identifies biased forecasting instances by estimating their accuracy. Based on this, the framework revises the forecasts using contextual information, including covariates and historical time series, from both local and global perspectives in a post-processing fashion. Extensive experiments on real-world datasets with mainstream forecasting models demonstrate that PIR effectively mitigates instance-level errors and significantly improves forecasting reliability.
Unveiling the Magic of Code Reasoning through Hypothesis Decomposition and Amendment
Feb 17, 2025The reasoning abilities are one of the most enigmatic and captivating aspects of large language models (LLMs). Numerous studies are dedicated to exploring and expanding the boundaries of this reasoning capability. However, tasks that embody both reasoning and recall characteristics are often overlooked. In this paper, we introduce such a novel task, code reasoning, to provide a new perspective for the reasoning abilities of LLMs. We summarize three meta-benchmarks based on established forms of logical reasoning, and instantiate these into eight specific benchmark tasks. Our testing on these benchmarks reveals that LLMs continue to struggle with identifying satisfactory reasoning pathways. Additionally, we present a new pathway exploration pipeline inspired by human intricate problem-solving methods. This Reflective Hypothesis Decomposition and Amendment (RHDA) pipeline consists of the following iterative steps: (1) Proposing potential hypotheses based on observations and decomposing them; (2) Utilizing tools to validate hypotheses and reflection outcomes; (3) Revising hypothesis in light of observations. Our approach effectively mitigates logical chain collapses arising from forgetting or hallucination issues in multi-step reasoning, resulting in performance gains of up to $3\times$. Finally, we expanded this pipeline by applying it to simulate complex household tasks in real-world scenarios, specifically in VirtualHome, enhancing the handling of failure cases. We release our code and all of results at https://github.com/TnTWoW/code_reasoning.
DisenTS: Disentangled Channel Evolving Pattern Modeling for Multivariate Time Series Forecasting
Oct 30, 2024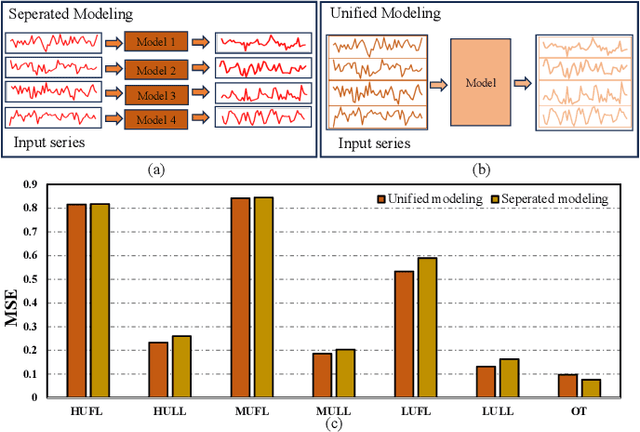
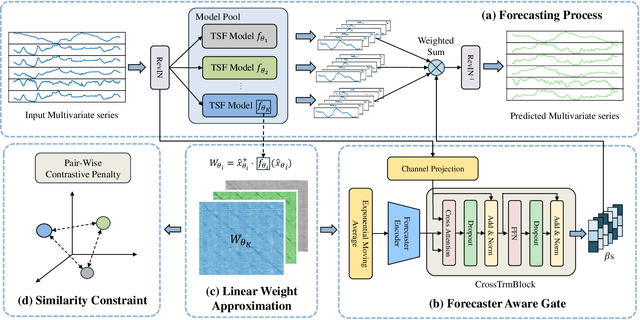

Multivariate time series forecasting plays a crucial role in various real-world applications. Significant efforts have been made to integrate advanced network architectures and training strategies that enhance the capture of temporal dependencies, thereby improving forecasting accuracy. On the other hand, mainstream approaches typically utilize a single unified model with simplistic channel-mixing embedding or cross-channel attention operations to account for the critical intricate inter-channel dependencies. Moreover, some methods even trade capacity for robust prediction based on the channel-independent assumption. Nonetheless, as time series data may display distinct evolving patterns due to the unique characteristics of each channel (including multiple strong seasonalities and trend changes), the unified modeling methods could yield suboptimal results. To this end, we propose DisenTS, a tailored framework for modeling disentangled channel evolving patterns in general multivariate time series forecasting. The central idea of DisenTS is to model the potential diverse patterns within the multivariate time series data in a decoupled manner. Technically, the framework employs multiple distinct forecasting models, each tasked with uncovering a unique evolving pattern. To guide the learning process without supervision of pattern partition, we introduce a novel Forecaster Aware Gate (FAG) module that generates the routing signals adaptively according to both the forecasters' states and input series' characteristics. The forecasters' states are derived from the Linear Weight Approximation (LWA) strategy, which quantizes the complex deep neural networks into compact matrices. Additionally, the Similarity Constraint (SC) is further proposed to guide each model to specialize in an underlying pattern by minimizing the mutual information between the representations.
FDF: Flexible Decoupled Framework for Time Series Forecasting with Conditional Denoising and Polynomial Modeling
Oct 17, 2024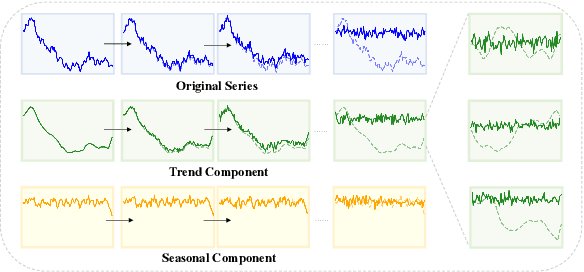



Time series forecasting is vital in numerous web applications, influencing critical decision-making across industries. While diffusion models have recently gained increasing popularity for this task, we argue they suffer from a significant drawback: indiscriminate noise addition to the original time series followed by denoising, which can obscure underlying dynamic evolving trend and complicate forecasting. To address this limitation, we propose a novel flexible decoupled framework (FDF) that learns high-quality time series representations for enhanced forecasting performance. A key characteristic of our approach leverages the inherent inductive bias of time series data by decomposing it into trend and seasonal components, each modeled separately to enable decoupled analysis and modeling. Specifically, we propose an innovative Conditional Denoising Seasonal Module (CDSM) within the diffusion model, which leverages statistical information from the historical window to conditionally model the complex seasonal component. Notably, we incorporate a Polynomial Trend Module (PTM) to effectively capture the smooth trend component, thereby enhancing the model's ability to represent temporal dependencies. Extensive experiments validate the effectiveness of our framework, demonstrating superior performance over existing methods and higlighting its flexibility in time series forecasting. We hope our work can bring a new perspective for time series forecasting. We intend to make our code publicly available as open-source in the future.
Diffusion Auto-regressive Transformer for Effective Self-supervised Time Series Forecasting
Oct 08, 2024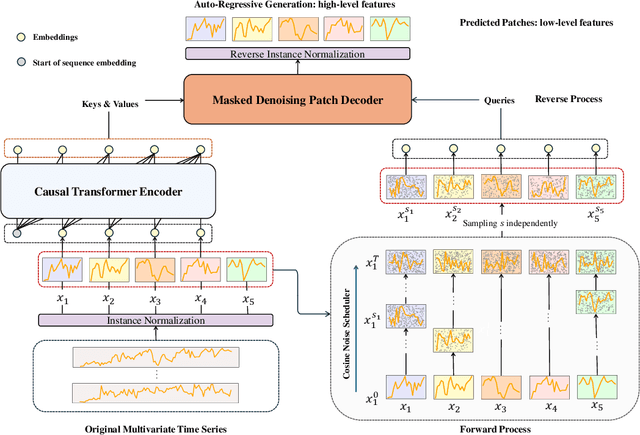
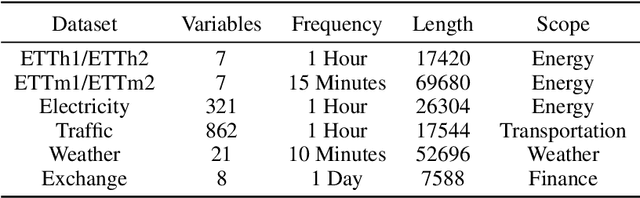
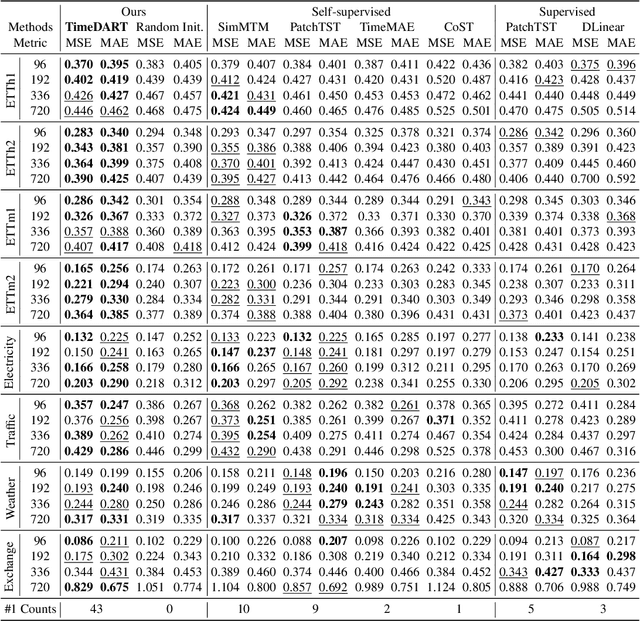
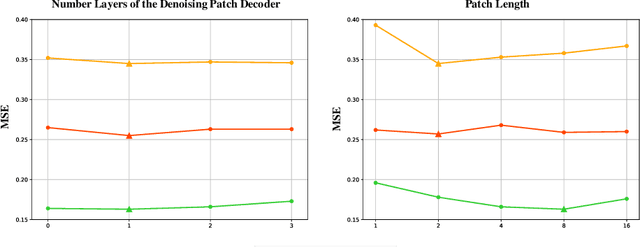
Self-supervised learning has become a popular and effective approach for enhancing time series forecasting, enabling models to learn universal representations from unlabeled data. However, effectively capturing both the global sequence dependence and local detail features within time series data remains challenging. To address this, we propose a novel generative self-supervised method called TimeDART, denoting Diffusion Auto-regressive Transformer for Time series forecasting. In TimeDART, we treat time series patches as basic modeling units. Specifically, we employ an self-attention based Transformer encoder to model the dependencies of inter-patches. Additionally, we introduce diffusion and denoising mechanisms to capture the detail locality features of intra-patch. Notably, we design a cross-attention-based denoising decoder that allows for adjustable optimization difficulty in the self-supervised task, facilitating more effective self-supervised pre-training. Furthermore, the entire model is optimized in an auto-regressive manner to obtain transferable representations. Extensive experiments demonstrate that TimeDART achieves state-of-the-art fine-tuning performance compared to the most advanced competitive methods in forecasting tasks. Our code is publicly available at https://github.com/Melmaphother/TimeDART.
HMF: A Hybrid Multi-Factor Framework for Dynamic Intraoperative Hypotension Prediction
Sep 17, 2024



Intraoperative hypotension (IOH) prediction using Mean Arterial Pressure (MAP) is a critical research area with significant implications for patient outcomes during surgery. However, existing approaches predominantly employ static modeling paradigms that overlook the dynamic nature of physiological signals. In this paper, we introduce a novel Hybrid Multi-Factor (HMF) framework that reformulates IOH prediction as a blood pressure forecasting task. Our framework leverages a Transformer encoder, specifically designed to effectively capture the temporal evolution of MAP series through a patch-based input representation, which segments the input physiological series into informative patches for accurate analysis. To address the challenges of distribution shift in physiological series, our approach incorporates two key innovations: (1) Symmetric normalization and de-normalization processes help mitigate distributional drift in statistical properties, thereby ensuring the model's robustness across varying conditions, and (2) Sequence decomposition, which disaggregates the input series into trend and seasonal components, allowing for a more precise modeling of inherent sequence dependencies. Extensive experiments conducted on two real-world datasets demonstrate the superior performance of our approach compared to competitive baselines, particularly in capturing the nuanced variations in input series that are crucial for accurate IOH prediction.
Advancing Time Series Classification with Multimodal Language Modeling
Mar 19, 2024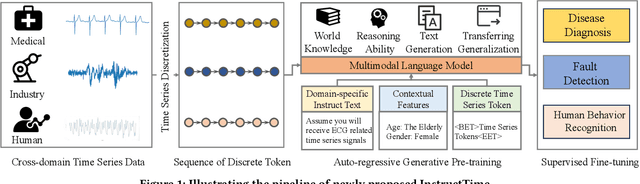
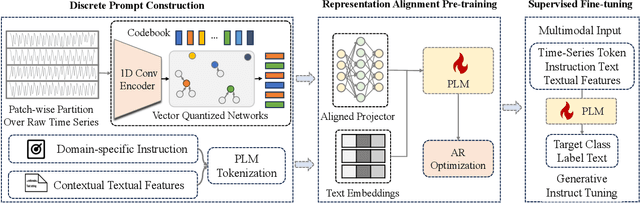
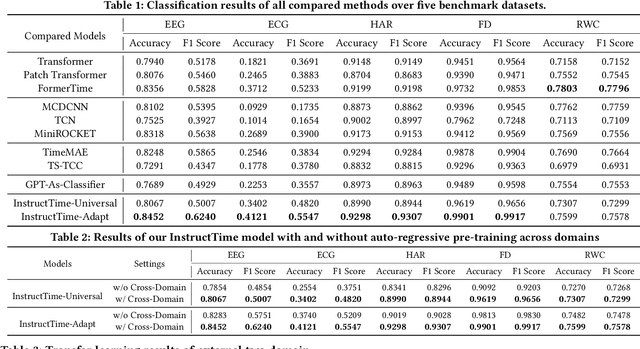

For the advancements of time series classification, scrutinizing previous studies, most existing methods adopt a common learning-to-classify paradigm - a time series classifier model tries to learn the relation between sequence inputs and target label encoded by one-hot distribution. Although effective, this paradigm conceals two inherent limitations: (1) encoding target categories with one-hot distribution fails to reflect the comparability and similarity between labels, and (2) it is very difficult to learn transferable model across domains, which greatly hinder the development of universal serving paradigm. In this work, we propose InstructTime, a novel attempt to reshape time series classification as a learning-to-generate paradigm. Relying on the powerful generative capacity of the pre-trained language model, the core idea is to formulate the classification of time series as a multimodal understanding task, in which both task-specific instructions and raw time series are treated as multimodal inputs while the label information is represented by texts. To accomplish this goal, three distinct designs are developed in the InstructTime. Firstly, a time series discretization module is designed to convert continuous time series into a sequence of hard tokens to solve the inconsistency issue across modal inputs. To solve the modality representation gap issue, for one thing, we introduce an alignment projected layer before feeding the transformed token of time series into language models. For another, we highlight the necessity of auto-regressive pre-training across domains, which can facilitate the transferability of the language model and boost the generalization performance. Extensive experiments are conducted over benchmark datasets, whose results uncover the superior performance of InstructTime and the potential for a universal foundation model in time series classification.
Generative Pretrained Hierarchical Transformer for Time Series Forecasting
Feb 26, 2024



Recent efforts have been dedicated to enhancing time series forecasting accuracy by introducing advanced network architectures and self-supervised pretraining strategies. Nevertheless, existing approaches still exhibit two critical drawbacks. Firstly, these methods often rely on a single dataset for training, limiting the model's generalizability due to the restricted scale of the training data. Secondly, the one-step generation schema is widely followed, which necessitates a customized forecasting head and overlooks the temporal dependencies in the output series, and also leads to increased training costs under different horizon length settings. To address these issues, we propose a novel generative pretrained hierarchical transformer architecture for forecasting, named GPHT. There are two aspects of key designs in GPHT. On the one hand, we advocate for constructing a mixed dataset for pretraining our model, comprising various datasets from diverse data scenarios. This approach significantly expands the scale of training data, allowing our model to uncover commonalities in time series data and facilitating improved transfer to specific datasets. On the other hand, GPHT employs an auto-regressive forecasting approach under the channel-independent assumption, effectively modeling temporal dependencies in the output series. Importantly, no customized forecasting head is required, enabling a single model to forecast at arbitrary horizon settings. We conduct sufficient experiments on eight datasets with mainstream self-supervised pretraining models and supervised models. The results demonstrated that GPHT surpasses the baseline models across various fine-tuning and zero/few-shot learning settings in the traditional long-term forecasting task, providing support for verifying the feasibility of pretrained time series large models.