 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoGenCast: A Coupled Autoregressive-Flow Generative Framework for Time Series Forecasting
Feb 03, 2026Time series forecasting can be viewed as a generative problem that requires both semantic understanding over contextual conditions and stochastic modeling of continuous temporal dynamics. Existing approaches typically rely on either autoregressive large language models (LLMs) for semantic context modeling or diffusion-like models for continuous probabilistic generation. However, neither method alone can adequately model both aspects simultaneously. In this work, we propose CoGenCast, a hybrid generative framework that couples pre-trained LLMs with flow-matching mechanism for effective time series forecasting. Specifically, we reconfigure pre-trained decoder-only LLMs into a native forecasting encoder-decoder backbone by modifying only the attention topology, enabling bidirectional context encoding and causal representation generation. Building on this, a flow-matching mechanism is further integrated to model temporal evolution, capturing continuous stochastic dynamics conditioned on the autoregressively generated representation. Notably, CoGenCast naturally supports multimodal forecasting and cross-domain unified training. Extensive experiments on multiple benchmarks show that CoGenCast consistently outperforms previous compared baselines. Code is available at https://github.com/liuyaguo/_CoGenCast.
MemCast: Memory-Driven Time Series Forecasting with Experience-Conditioned Reasoning
Feb 03, 2026Time series forecasting (TSF) plays a critical role in decision-making for many real-world applications. Recently, LLM-based forecasters have made promising advancements. Despite their effectiveness, existing methods often lack explicit experience accumulation and continual evolution. In this work, we propose MemCast, a learning-to-memory framework that reformulates TSF as an experience-conditioned reasoning task. Specifically, we learn experience from the training set and organize it into a hierarchical memory. This is achieved by summarizing prediction results into historical patterns, distilling inference trajectories into reasoning wisdom, and inducing extracted temporal features into general laws. Furthermore, during inference, we leverage historical patterns to guide the reasoning process and utilize reasoning wisdom to select better trajectories, while general laws serve as criteria for reflective iteration. Additionally, to enable continual evolution, we design a dynamic confidence adaptation strategy that updates the confidence of individual entries without leaking the test set distribution. Extensive experiments on multiple datasets demonstrate that MemCast consistently outperforms previous methods, validating the effectiveness of our approach. Our code is available at https://github.com/Xiaoyu-Tao/MemCast-TS.
Position: Beyond Model-Centric Prediction -- Agentic Time Series Forecasting
Feb 02, 2026Time series forecasting has traditionally been formulated as a model-centric, static, and single-pass prediction problem that maps historical observations to future values. While this paradigm has driven substantial progress, it proves insufficient in adaptive and multi-turn settings where forecasting requires informative feature extraction, reasoning-driven inference, iterative refinement, and continual adaptation over time. In this paper, we argue for agentic time series forecasting (ATSF), which reframes forecasting as an agentic process composed of perception, planning, action, reflection, and memory. Rather than focusing solely on predictive models, ATSF emphasizes organizing forecasting as an agentic workflow that can interact with tools, incorporate feedback from outcomes, and evolve through experience accumulation. We outline three representative implementation paradigms -- workflow-based design, agentic reinforcement learning, and a hybrid agentic workflow paradigm -- and discuss the opportunities and challenges that arise when shifting from model-centric prediction to agentic forecasting. Together, this position aims to establish agentic forecasting as a foundation for future research at the intersection of time series forecasting.
InstructTime++: Time Series Classification with Multimodal Language Modeling via Implicit Feature Enhancement
Jan 21, 2026Most existing time series classification methods adopt a discriminative paradigm that maps input sequences directly to one-hot encoded class labels. While effective, this paradigm struggles to incorporate contextual features and fails to capture semantic relationships among classes. To address these limitations, we propose InstructTime, a novel framework that reformulates time series classification as a multimodal generative task. Specifically, continuous numerical sequences, contextual textual features, and task instructions are treated as multimodal inputs, while class labels are generated as textual outputs by tuned language models. To bridge the modality gap, InstructTime introduces a time series discretization module that converts continuous sequences into discrete temporal tokens, together with an alignment projection layer and a generative self-supervised pre-training strategy to enhance cross-modal representation alignment. Building upon this framework, we further propose InstructTime++, which extends InstructTime by incorporating implicit feature modeling to compensate for the limited inductive bias of language models. InstructTime++ leverages specialized toolkits to mine informative implicit patterns from raw time series and contextual inputs, including statistical feature extraction and vision-language-based image captioning, and translates them into textual descriptions for seamless integration. Extensive experiments on multiple benchmark datasets demonstrate the superior performance of InstructTime++.
Mind2Report: A Cognitive Deep Research Agent for Expert-Level Commercial Report Synthesis
Jan 08, 2026Synthesizing informative commercial reports from massive and noisy web sources is critical for high-stakes business decisions. Although current deep research agents achieve notable progress, their reports still remain limited in terms of quality, reliability, and coverage. In this work, we propose Mind2Report, a cognitive deep research agent that emulates the commercial analyst to synthesize expert-level reports. Specifically, it first probes fine-grained intent, then searches web sources and records distilled information on the fly, and subsequently iteratively synthesizes the report. We design Mind2Report as a training-free agentic workflow that augments general large language models (LLMs) with dynamic memory to support these long-form cognitive processes. To rigorously evaluate Mind2Report, we further construct QRC-Eval comprising 200 real-world commercial tasks and establish a holistic evaluation strategy to assess report quality, reliability, and coverage. Experiments demonstrate that Mind2Report outperforms leading baselines, including OpenAI and Gemini deep research agents. Although this is a preliminary study, we expect it to serve as a foundation for advancing the future design of commercial deep research agents. Our code and data are available at https://github.com/Melmaphother/Mind2Report.
STaR: Towards Cognitive Table Reasoning via Slow-Thinking Large Language Models
Nov 14, 2025Table reasoning with the large language models (LLMs) is a fundamental path toward building intelligent systems that can understand and analyze over structured data. While recent progress has shown promising results, they still suffer from two key limitations: (i) the reasoning processes lack the depth and iterative refinement characteristic of human cognition; and (ii) the reasoning processes exhibit instability, which compromises their reliability in downstream applications. In this work, we present STaR (slow-thinking for table reasoning), a new framework achieving cognitive table reasoning, in which LLMs are equipped with slow-thinking capabilities by explicitly modeling step-by-step thinking and uncertainty-aware inference. During training, STaR employs two-stage difficulty-aware reinforcement learning (DRL), progressively learning from simple to complex queries under a composite reward. During inference, STaR performs trajectory-level uncertainty quantification by integrating token-level confidence and answer consistency, enabling selection of more credible reasoning paths. Extensive experiments on benchmarks demonstrate that STaR achieves superior performance and enhanced reasoning stability. Moreover, strong generalization over out-of-domain datasets further demonstrates STaR's potential as a reliable and cognitively inspired solution for table reasoning with LLMs.
AlphaCast: A Human Wisdom-LLM Intelligence Co-Reasoning Framework for Interactive Time Series Forecasting
Nov 12, 2025Time series forecasting plays a critical role in high-stakes domains such as energy, healthcare, and climate. Although recent advances have improved accuracy, most approaches still treat forecasting as a static one-time mapping task, lacking the interaction, reasoning, and adaptability of human experts. This gap limits their usefulness in complex real-world environments. To address this, we propose AlphaCast, a human wisdom-large language model (LLM) intelligence co-reasoning framework that redefines forecasting as an interactive process. The key idea is to enable step-by-step collaboration between human wisdom and LLM intelligence to jointly prepare, generate, and verify forecasts. The framework consists of two stages: (1) automated prediction preparation, where AlphaCast builds a multi-source cognitive foundation comprising a feature set that captures key statistics and time patterns, a domain knowledge base distilled from corpora and historical series, a contextual repository that stores rich information for each time window, and a case base that retrieves optimal strategies via pattern clustering and matching; and (2) generative reasoning and reflective optimization, where AlphaCast integrates statistical temporal features, prior knowledge, contextual information, and forecasting strategies, triggering a meta-reasoning loop for continuous self-correction and strategy refinement. Extensive experiments on short- and long-term datasets show that AlphaCast consistently outperforms state-of-the-art baselines in predictive accuracy. Code is available at this repository: https://github.com/SkyeGT/AlphaCast_Official .
MemWeaver: A Hierarchical Memory from Textual Interactive Behaviors for Personalized Generation
Oct 09, 2025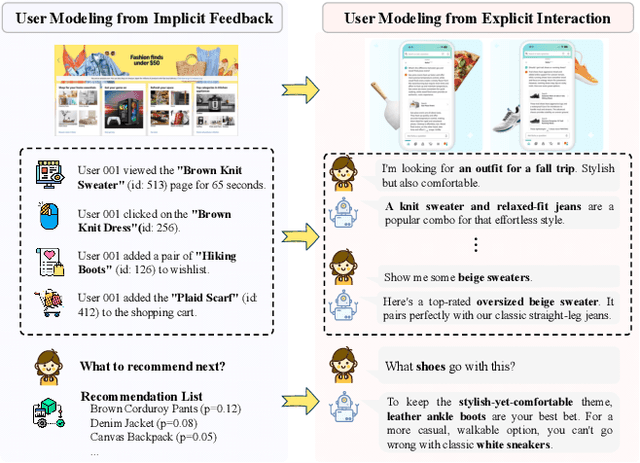
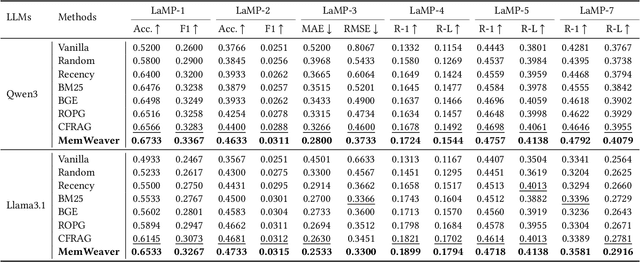
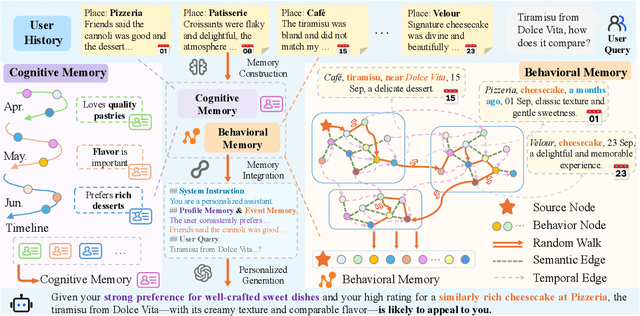
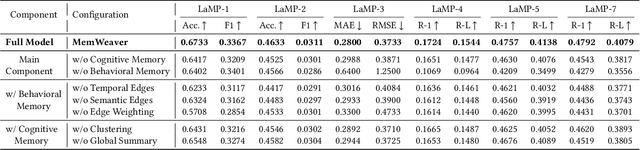
The primary form of user-internet engagement is shifting from leveraging implicit feedback signals, such as browsing and clicks, to harnessing the rich explicit feedback provided by textual interactive behaviors. This shift unlocks a rich source of user textual history, presenting a profound opportunity for a deeper form of personalization. However, prevailing approaches offer only a shallow form of personalization, as they treat user history as a flat list of texts for retrieval and fail to model the rich temporal and semantic structures reflecting dynamic nature of user interests. In this work, we propose \textbf{MemWeaver}, a framework that weaves the user's entire textual history into a hierarchical memory to power deeply personalized generation. The core innovation of our memory lies in its ability to capture both the temporal evolution of interests and the semantic relationships between different activities. To achieve this, MemWeaver builds two complementary memory components that both integrate temporal and semantic information, but at different levels of abstraction: behavioral memory, which captures specific user actions, and cognitive memory, which represents long-term preferences. This dual-component memory serves as a unified representation of the user, allowing large language models (LLMs) to reason over both concrete behaviors and abstracted traits. Experiments on the Language Model Personalization (LaMP) benchmark validate the efficacy of MemWeaver. Our code is available\footnote{https://github.com/fishsure/MemWeaver}.
TextMatch: Enhancing Image-Text Consistency Through Multimodal Optimization
Dec 24, 2024Text-to-image generative models excel in creating images from text but struggle with ensuring alignment and consistency between outputs and prompts. This paper introduces TextMatch, a novel framework that leverages multimodal optimization to address image-text discrepancies in text-to-image (T2I) generation and editing. TextMatch employs a scoring strategy powered by large language models (LLMs) and visual question-answering (VQA) models to evaluate semantic consistency between prompts and generated images. By integrating multimodal in-context learning and chain of thought reasoning, our method dynamically refines prompts through iterative optimization. This process ensures that the generated images better capture user intent of, resulting in higher fidelity and relevance. Extensive experiments demonstrate that TextMatch significantly improves text-image consistency across multiple benchmarks, establishing a reliable framework for advancing the capabilities of text-to-image generative models. Our code is available at https://anonymous.4open.science/r/TextMatch-F55C/.
Hierarchical Multimodal LLMs with Semantic Space Alignment for Enhanced Time Series Classification
Oct 24, 2024



Leveraging large language models (LLMs) has garnered increasing attention and introduced novel perspectives in time series classification. However, existing approaches often overlook the crucial dynamic temporal information inherent in time series data and face challenges in aligning this data with textual semantics. To address these limitations, we propose HiTime, a hierarchical multi-modal model that seamlessly integrates temporal information into LLMs for multivariate time series classification (MTSC). Our model employs a hierarchical feature encoder to capture diverse aspects of time series data through both data-specific and task-specific embeddings. To facilitate semantic space alignment between time series and text, we introduce a dual-view contrastive alignment module that bridges the gap between modalities. Additionally, we adopt a hybrid prompting strategy to fine-tune the pre-trained LLM in a parameter-efficient manner. By effectively incorporating dynamic temporal features and ensuring semantic alignment, HiTime enables LLMs to process continuous time series data and achieves state-of-the-art classification performance through text generation. Extensive experiments on benchmark datasets demonstrate that HiTime significantly enhances time series classification accuracy compared to most competitive baseline methods. Our findings highlight the potential of integrating temporal features into LLMs, paving the way for advanced time series analysis. The code is publicly available for further research and validation. Our codes are publicly available1.