 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Parameter Isolation Better for Prompt-Based Continual Learning?
Jan 28, 2026Prompt-based continual learning methods effectively mitigate catastrophic forgetting. However, most existing methods assign a fixed set of prompts to each task, completely isolating knowledge across tasks and resulting in suboptimal parameter utilization. To address this, we consider the practical needs of continual learning and propose a prompt-sharing framework. This framework constructs a global prompt pool and introduces a task-aware gated routing mechanism that sparsely activates a subset of prompts to achieve dynamic decoupling and collaborative optimization of task-specific feature representations. Furthermore, we introduce a history-aware modulator that leverages cumulative prompt activation statistics to protect frequently used prompts from excessive updates, thereby mitigating inefficient parameter usage and knowledge forgetting. Extensive analysis and empirical results demonstrate that our approach consistently outperforms existing static allocation strategies in effectiveness and efficiency.
P2L-CA: An Effective Parameter Tuning Framework for Rehearsal-Free Multi-Label Class-Incremental Learning
Jan 19, 2026Multi-label Class-Incremental Learning aims to continuously recognize novel categories in complex scenes where multiple objects co-occur. However, existing approaches often incur high computational costs due to full-parameter fine-tuning and substantial storage overhead from memory buffers, or they struggle to address feature confusion and domain discrepancies adequately. To overcome these limitations, we introduce P2L-CA, a parameter-efficient framework that integrates a Prompt-to-Label module with a Continuous Adapter module. The P2L module leverages class-specific prompts to disentangle multi-label representations while incorporating linguistic priors to enforce stable semantic-visual alignment. Meanwhile, the CA module employs lightweight adapters to mitigate domain gaps between pre-trained models and downstream tasks, thereby enhancing model plasticity. Extensive experiments across standard and challenging MLCIL settings on MS-COCO and PASCAL VOC show that P2L-CA not only achieves substantial improvements over state-of-the-art methods but also demonstrates strong generalization in CIL scenarios, all while requiring minimal trainable parameters and eliminating the need for memory buffers.
Beyond CLIP Generalization: Against Forward&Backward Forgetting Adapter for Continual Learning of Vision-Language Models
May 12, 2025This study aims to address the problem of multi-domain task incremental learning~(MTIL), which requires that vision-language models~(VLMs) continuously acquire new knowledge while maintaining their inherent zero-shot recognition capability. Existing paradigms delegate the testing of unseen-domain samples to the original CLIP, which only prevents the degradation of the model's zero-shot capability but fails to enhance the generalization of the VLM further. To this end, we propose a novel MTIL framework, named AFA, which comprises two core modules: (1) an against forward-forgetting adapter that learns task-invariant information for each dataset in the incremental tasks to enhance the zero-shot recognition ability of VLMs; (2) an against backward-forgetting adapter that strengthens the few-shot learning capability of VLMs while supporting incremental learning. Extensive experiments demonstrate that the AFA method significantly outperforms existing state-of-the-art approaches, especially in few-shot MTIL tasks, and surpasses the inherent zero-shot performance of CLIP in terms of transferability. The code is provided in the Supplementary Material.
Learn by Reasoning: Analogical Weight Generation for Few-Shot Class-Incremental Learning
Mar 27, 2025Few-shot class-incremental Learning (FSCIL) enables models to learn new classes from limited data while retaining performance on previously learned classes. Traditional FSCIL methods often require fine-tuning parameters with limited new class data and suffer from a separation between learning new classes and utilizing old knowledge. Inspired by the analogical learning mechanisms of the human brain, we propose a novel analogical generative method. Our approach includes the Brain-Inspired Analogical Generator (BiAG), which derives new class weights from existing classes without parameter fine-tuning during incremental stages. BiAG consists of three components: Weight Self-Attention Module (WSA), Weight & Prototype Analogical Attention Module (WPAA), and Semantic Conversion Module (SCM). SCM uses Neural Collapse theory for semantic conversion, WSA supplements new class weights, and WPAA computes analogies to generate new class weights. Experiments on miniImageNet, CUB-200, and CIFAR-100 datasets demonstrate that our method achieves higher final and average accuracy compared to SOTA methods.
Diversity Covariance-Aware Prompt Learning for Vision-Language Models
Mar 03, 2025Prompt tuning can further enhance the performance of visual-language models across various downstream tasks (e.g., few-shot learning), enabling them to better adapt to specific applications and needs. In this paper, we present a Diversity Covariance-Aware framework that learns distributional information from the data to enhance the few-shot ability of the prompt model. First, we propose a covariance-aware method that models the covariance relationships between visual features and uses anisotropic Mahalanobis distance, instead of the suboptimal cosine distance, to measure the similarity between two modalities. We rigorously derive and prove the validity of this modeling process. Then, we propose the diversity-aware method, which learns multiple diverse soft prompts to capture different attributes of categories and aligns them independently with visual modalities. This method achieves multi-centered covariance modeling, leading to more diverse decision boundaries. Extensive experiments on 11 datasets in various tasks demonstrate the effectiveness of our method.
Space Rotation with Basis Transformation for Training-free Test-Time Adaptation
Feb 27, 2025With the development of visual-language models (VLM) in downstream task applications, test-time adaptation methods based on VLM have attracted increasing attention for their ability to address changes distribution in test-time. Although prior approaches have achieved some progress, they typically either demand substantial computational resources or are constrained by the limitations of the original feature space, rendering them less effective for test-time adaptation tasks. To address these challenges, we propose a training-free feature space rotation with basis transformation for test-time adaptation. By leveraging the inherent distinctions among classes, we reconstruct the original feature space and map it to a new representation, thereby enhancing the clarity of class differences and providing more effective guidance for the model during testing. Additionally, to better capture relevant information from various classes, we maintain a dynamic queue to store representative samples. Experimental results across multiple benchmarks demonstrate that our method outperforms state-of-the-art techniques in terms of both performance and efficiency.
LOBG:Less Overfitting for Better Generalization in Vision-Language Model
Oct 14, 2024Existing prompt learning methods in Vision-Language Models (VLM) have effectively enhanced the transfer capability of VLM to downstream tasks, but they suffer from a significant decline in generalization due to severe overfitting. To address this issue, we propose a framework named LOBG for vision-language models. Specifically, we use CLIP to filter out fine-grained foreground information that might cause overfitting, thereby guiding prompts with basic visual concepts. To further mitigate overfitting, we devel oped a structural topology preservation (STP) loss at the feature level, which endows the feature space with overall plasticity, allowing effective reshaping of the feature space during optimization. Additionally, we employed hierarchical logit distilation (HLD) at the output level to constrain outputs, complementing STP at the output end. Extensive experimental results demonstrate that our method significantly improves generalization capability and alleviates overfitting compared to state-of-the-art approaches.
Beyond Prompt Learning: Continual Adapter for Efficient Rehearsal-Free Continual Learning
Jul 14, 2024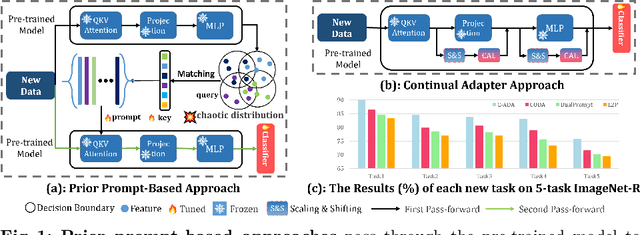
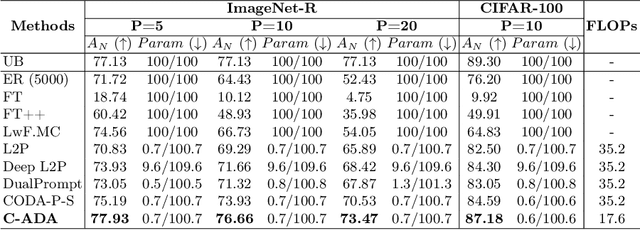
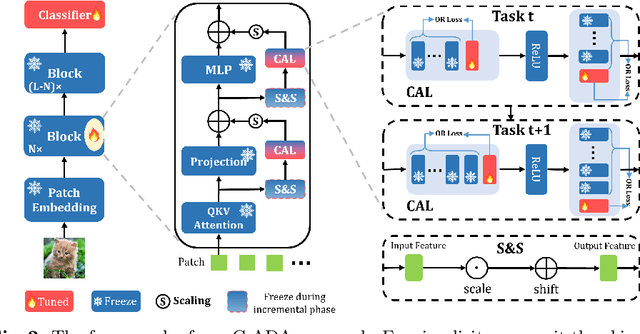
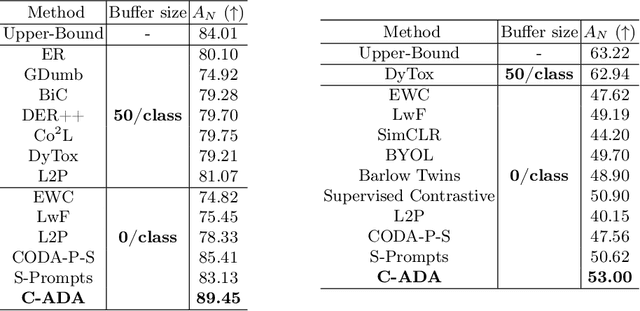
The problem of Rehearsal-Free Continual Learning (RFCL) aims to continually learn new knowledge while preventing forgetting of the old knowledge, without storing any old samples and prototypes. The latest methods leverage large-scale pre-trained models as the backbone and use key-query matching to generate trainable prompts to learn new knowledge. However, the domain gap between the pre-training dataset and the downstream datasets can easily lead to inaccuracies in key-query matching prompt selection when directly generating queries using the pre-trained model, which hampers learning new knowledge. Thus, in this paper, we propose a beyond prompt learning approach to the RFCL task, called Continual Adapter (C-ADA). It mainly comprises a parameter-extensible continual adapter layer (CAL) and a scaling and shifting (S&S) module in parallel with the pre-trained model. C-ADA flexibly extends specific weights in CAL to learn new knowledge for each task and freezes old weights to preserve prior knowledge, thereby avoiding matching errors and operational inefficiencies introduced by key-query matching. To reduce the gap, C-ADA employs an S&S module to transfer the feature space from pre-trained datasets to downstream datasets. Moreover, we propose an orthogonal loss to mitigate the interaction between old and new knowledge. Our approach achieves significantly improved performance and training speed, outperforming the current state-of-the-art (SOTA) method. Additionally, we conduct experiments on domain-incremental learning, surpassing the SOTA, and demonstrating the generality of our approach in different settings.
I2CANSAY:Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning
Apr 21, 2024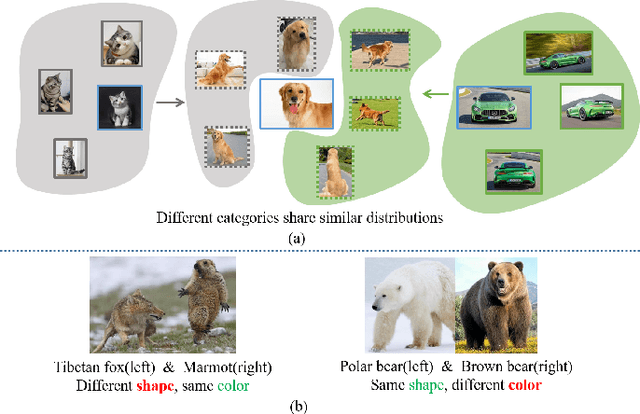



Online task-free continual learning (OTFCL) is a more challenging variant of continual learning which emphasizes the gradual shift of task boundaries and learns in an online mode. Existing methods rely on a memory buffer composed of old samples to prevent forgetting. However,the use of memory buffers not only raises privacy concerns but also hinders the efficient learning of new samples. To address this problem, we propose a novel framework called I2CANSAY that gets rid of the dependence on memory buffers and efficiently learns the knowledge of new data from one-shot samples. Concretely, our framework comprises two main modules. Firstly, the Inter-Class Analogical Augmentation (ICAN) module generates diverse pseudo-features for old classes based on the inter-class analogy of feature distributions for different new classes, serving as a substitute for the memory buffer. Secondly, the Intra-Class Significance Analysis (ISAY) module analyzes the significance of attributes for each class via its distribution standard deviation, and generates the importance vector as a correction bias for the linear classifier, thereby enhancing the capability of learning from new samples. We run our experiments on four popular image classification datasets: CoRe50, CIFAR-10, CIFAR-100, and CUB-200, our approach outperforms the prior state-of-the-art by a large margin.
Few-shot Online Anomaly Detection and Segmentation
Mar 27, 2024



Detecting anomaly patterns from images is a crucial artificial intelligence technique in industrial applications. Recent research in this domain has emphasized the necessity of a large volume of training data, overlooking the practical scenario where, post-deployment of the model, unlabeled data containing both normal and abnormal samples can be utilized to enhance the model's performance. Consequently, this paper focuses on addressing the challenging yet practical few-shot online anomaly detection and segmentation (FOADS) task. Under the FOADS framework, models are trained on a few-shot normal dataset, followed by inspection and improvement of their capabilities by leveraging unlabeled streaming data containing both normal and abnormal samples simultaneously. To tackle this issue, we propose modeling the feature distribution of normal images using a Neural Gas network, which offers the flexibility to adapt the topology structure to identify outliers in the data flow. In order to achieve improved performance with limited training samples, we employ multi-scale feature embedding extracted from a CNN pre-trained on ImageNet to obtain a robust representation. Furthermore, we introduce an algorithm that can incrementally update parameters without the need to store previous samples. Comprehensive experimental results demonstrate that our method can achieve substantial performance under the FOADS setting, while ensuring that the time complexity remains within an acceptable range on MVTec AD and BTAD datasets.