 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
P2L-CA: An Effective Parameter Tuning Framework for Rehearsal-Free Multi-Label Class-Incremental Learning
Jan 19, 2026Multi-label Class-Incremental Learning aims to continuously recognize novel categories in complex scenes where multiple objects co-occur. However, existing approaches often incur high computational costs due to full-parameter fine-tuning and substantial storage overhead from memory buffers, or they struggle to address feature confusion and domain discrepancies adequately. To overcome these limitations, we introduce P2L-CA, a parameter-efficient framework that integrates a Prompt-to-Label module with a Continuous Adapter module. The P2L module leverages class-specific prompts to disentangle multi-label representations while incorporating linguistic priors to enforce stable semantic-visual alignment. Meanwhile, the CA module employs lightweight adapters to mitigate domain gaps between pre-trained models and downstream tasks, thereby enhancing model plasticity. Extensive experiments across standard and challenging MLCIL settings on MS-COCO and PASCAL VOC show that P2L-CA not only achieves substantial improvements over state-of-the-art methods but also demonstrates strong generalization in CIL scenarios, all while requiring minimal trainable parameters and eliminating the need for memory buffers.
Extreme Value Policy Optimization for Safe Reinforcement Learning
Jan 17, 2026Ensuring safety is a critical challenge in applying Reinforcement Learning (RL) to real-world scenarios. Constrained Reinforcement Learning (CRL) addresses this by maximizing returns under predefined constraints, typically formulated as the expected cumulative cost. However, expectation-based constraints overlook rare but high-impact extreme value events in the tail distribution, such as black swan incidents, which can lead to severe constraint violations. To address this issue, we propose the Extreme Value policy Optimization (EVO) algorithm, leveraging Extreme Value Theory (EVT) to model and exploit extreme reward and cost samples, reducing constraint violations. EVO introduces an extreme quantile optimization objective to explicitly capture extreme samples in the cost tail distribution. Additionally, we propose an extreme prioritization mechanism during replay, amplifying the learning signal from rare but high-impact extreme samples. Theoretically, we establish upper bounds on expected constraint violations during policy updates, guaranteeing strict constraint satisfaction at a zero-violation quantile level. Further, we demonstrate that EVO achieves a lower probability of constraint violations than expectation-based methods and exhibits lower variance than quantile regression methods. Extensive experiments show that EVO significantly reduces constraint violations during training while maintaining competitive policy performance compared to baselines.
Knowledge Restore and Transfer for Multi-label Class-Incremental Learning
Mar 07, 2023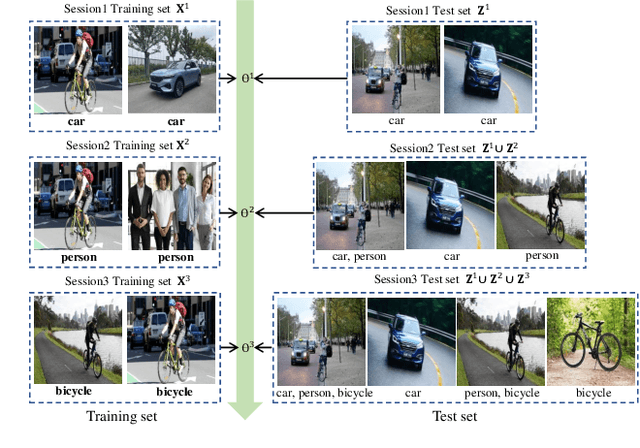



Current class-incremental learning research mainly focuses on single-label classification tasks while multi-label class-incremental learning (MLCIL) with more practical application scenarios is rarely studied. Although there have been many anti-forgetting methods to solve the problem of catastrophic forgetting in class-incremental learning, these methods have difficulty in solving the MLCIL problem due to label absence and information dilution. In this paper, we propose a knowledge restore and transfer (KRT) framework for MLCIL, which includes a dynamic pseudo-label (DPL) module to restore the old class knowledge and an incremental cross-attention(ICA) module to save session-specific knowledge and transfer old class knowledge to the new model sufficiently. Besides, we propose a token loss to jointly optimize the incremental cross-attention module. Experimental results on MS-COCO and PASCAL VOC datasets demonstrate the effectiveness of our method for improving recognition performance and mitigating forgetting on multi-label class-incremental learning tasks.