 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Underestimation Bias in Constrained Reinforcement Learning for Safe Exploration
Jan 17, 2026Constrained Reinforcement Learning (CRL) aims to maximize cumulative rewards while satisfying constraints. However, existing CRL algorithms often encounter significant constraint violations during training, limiting their applicability in safety-critical scenarios. In this paper, we identify the underestimation of the cost value function as a key factor contributing to these violations. To address this issue, we propose the Memory-driven Intrinsic Cost Estimation (MICE) method, which introduces intrinsic costs to mitigate underestimation and control bias to promote safer exploration. Inspired by flashbulb memory, where humans vividly recall dangerous experiences to avoid risks, MICE constructs a memory module that stores previously explored unsafe states to identify high-cost regions. The intrinsic cost is formulated as the pseudo-count of the current state visiting these risk regions. Furthermore, we propose an extrinsic-intrinsic cost value function that incorporates intrinsic costs and adopts a bias correction strategy. Using this function, we formulate an optimization objective within the trust region, along with corresponding optimization methods. Theoretically, we provide convergence guarantees for the proposed cost value function and establish the worst-case constraint violation for the MICE update. Extensive experiments demonstrate that MICE significantly reduces constraint violations while preserving policy performance comparable to baselines.
Extreme Value Policy Optimization for Safe Reinforcement Learning
Jan 17, 2026Ensuring safety is a critical challenge in applying Reinforcement Learning (RL) to real-world scenarios. Constrained Reinforcement Learning (CRL) addresses this by maximizing returns under predefined constraints, typically formulated as the expected cumulative cost. However, expectation-based constraints overlook rare but high-impact extreme value events in the tail distribution, such as black swan incidents, which can lead to severe constraint violations. To address this issue, we propose the Extreme Value policy Optimization (EVO) algorithm, leveraging Extreme Value Theory (EVT) to model and exploit extreme reward and cost samples, reducing constraint violations. EVO introduces an extreme quantile optimization objective to explicitly capture extreme samples in the cost tail distribution. Additionally, we propose an extreme prioritization mechanism during replay, amplifying the learning signal from rare but high-impact extreme samples. Theoretically, we establish upper bounds on expected constraint violations during policy updates, guaranteeing strict constraint satisfaction at a zero-violation quantile level. Further, we demonstrate that EVO achieves a lower probability of constraint violations than expectation-based methods and exhibits lower variance than quantile regression methods. Extensive experiments show that EVO significantly reduces constraint violations during training while maintaining competitive policy performance compared to baselines.
Exterior Penalty Policy Optimization with Penalty Metric Network under Constraints
Jul 22, 2024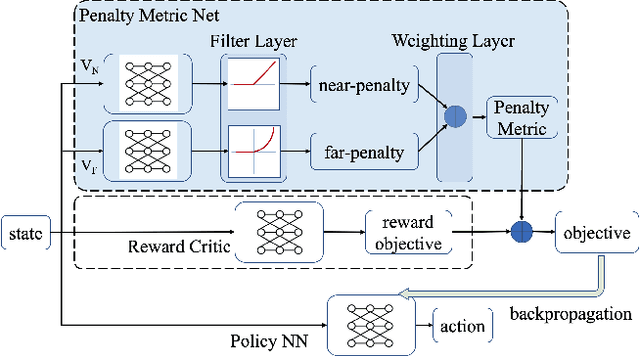
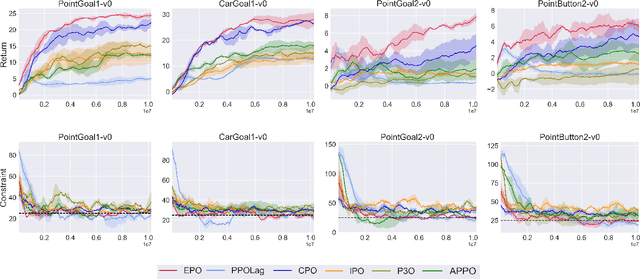
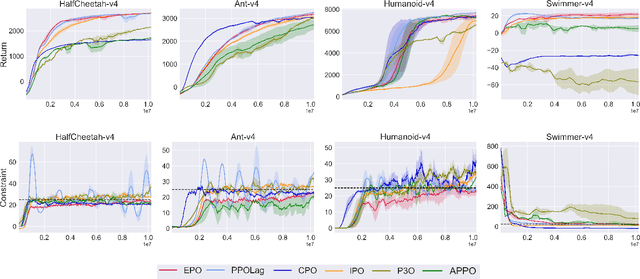
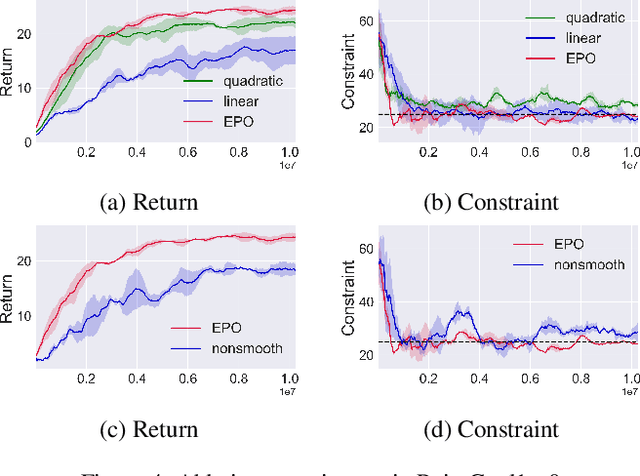
In Constrained Reinforcement Learning (CRL), agents explore the environment to learn the optimal policy while satisfying constraints. The penalty function method has recently been studied as an effective approach for handling constraints, which imposes constraints penalties on the objective to transform the constrained problem into an unconstrained one. However, it is challenging to choose appropriate penalties that balance policy performance and constraint satisfaction efficiently. In this paper, we propose a theoretically guaranteed penalty function method, Exterior Penalty Policy Optimization (EPO), with adaptive penalties generated by a Penalty Metric Network (PMN). PMN responds appropriately to varying degrees of constraint violations, enabling efficient constraint satisfaction and safe exploration. We theoretically prove that EPO consistently improves constraint satisfaction with a convergence guarantee. We propose a new surrogate function and provide worst-case constraint violation and approximation error. In practice, we propose an effective smooth penalty function, which can be easily implemented with a first-order optimizer. Extensive experiments are conducted, showing that EPO outperforms the baselines in terms of policy performance and constraint satisfaction with a stable training process, particularly on complex tasks.