 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExterior Penalty Policy Optimization with Penalty Metric Network under Constraints
Paper and Code
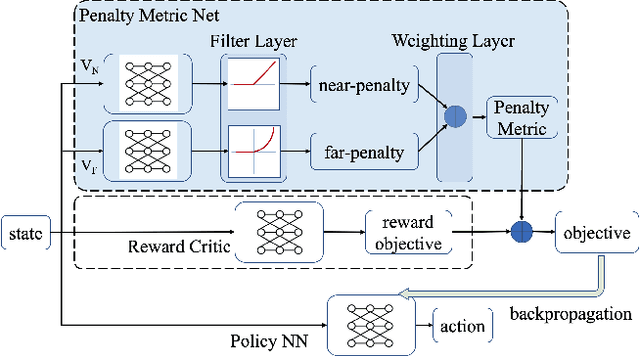
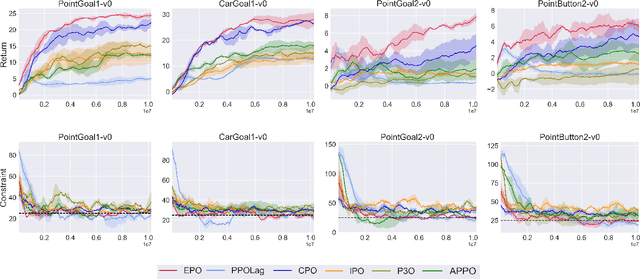
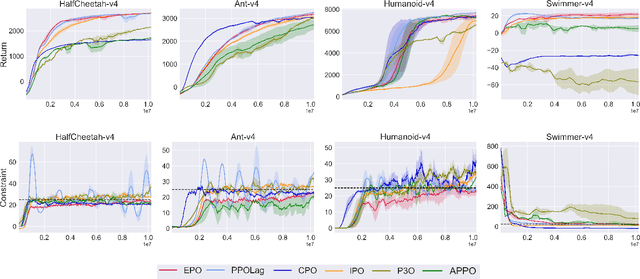
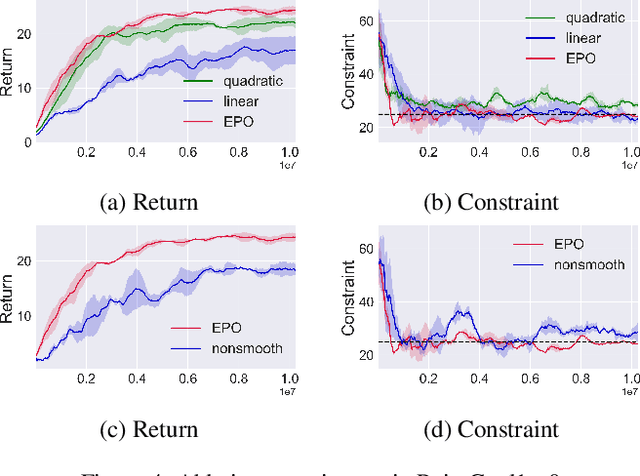
In Constrained Reinforcement Learning (CRL), agents explore the environment to learn the optimal policy while satisfying constraints. The penalty function method has recently been studied as an effective approach for handling constraints, which imposes constraints penalties on the objective to transform the constrained problem into an unconstrained one. However, it is challenging to choose appropriate penalties that balance policy performance and constraint satisfaction efficiently. In this paper, we propose a theoretically guaranteed penalty function method, Exterior Penalty Policy Optimization (EPO), with adaptive penalties generated by a Penalty Metric Network (PMN). PMN responds appropriately to varying degrees of constraint violations, enabling efficient constraint satisfaction and safe exploration. We theoretically prove that EPO consistently improves constraint satisfaction with a convergence guarantee. We propose a new surrogate function and provide worst-case constraint violation and approximation error. In practice, we propose an effective smooth penalty function, which can be easily implemented with a first-order optimizer. Extensive experiments are conducted, showing that EPO outperforms the baselines in terms of policy performance and constraint satisfaction with a stable training process, particularly on complex tasks.