 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge<SOG_k>: One LLM Token for Explicit Graph Structural Understanding
Feb 02, 2026Large language models show great potential in unstructured data understanding, but still face significant challenges with graphs due to their structural hallucination. Existing approaches mainly either verbalize graphs into natural language, which leads to excessive token consumption and scattered attention, or transform graphs into trainable continuous embeddings (i.e., soft prompt), but exhibit severe misalignment with original text tokens. To solve this problem, we propose to incorporate one special token <SOG_k> to fully represent the Structure Of Graph within a unified token space, facilitating explicit topology input and structural information sharing. Specifically, we propose a topology-aware structural tokenizer that maps each graph topology into a highly selective single token. Afterwards, we construct a set of hybrid structure Question-Answering corpora to align new structural tokens with existing text tokens. With this approach, <SOG_k> empowers LLMs to understand, generate, and reason in a concise and accurate manner. Extensive experiments on five graph-level benchmarks demonstrate the superiority of our method, achieving a performance improvement of 9.9% to 41.4% compared to the baselines while exhibiting interpretability and consistency. Furthermore, our method provides a flexible extension to node-level tasks, enabling both global and local structural understanding. The codebase is publicly available at https://github.com/Jingyao-Wu/SOG.
Controlling Underestimation Bias in Constrained Reinforcement Learning for Safe Exploration
Jan 17, 2026Constrained Reinforcement Learning (CRL) aims to maximize cumulative rewards while satisfying constraints. However, existing CRL algorithms often encounter significant constraint violations during training, limiting their applicability in safety-critical scenarios. In this paper, we identify the underestimation of the cost value function as a key factor contributing to these violations. To address this issue, we propose the Memory-driven Intrinsic Cost Estimation (MICE) method, which introduces intrinsic costs to mitigate underestimation and control bias to promote safer exploration. Inspired by flashbulb memory, where humans vividly recall dangerous experiences to avoid risks, MICE constructs a memory module that stores previously explored unsafe states to identify high-cost regions. The intrinsic cost is formulated as the pseudo-count of the current state visiting these risk regions. Furthermore, we propose an extrinsic-intrinsic cost value function that incorporates intrinsic costs and adopts a bias correction strategy. Using this function, we formulate an optimization objective within the trust region, along with corresponding optimization methods. Theoretically, we provide convergence guarantees for the proposed cost value function and establish the worst-case constraint violation for the MICE update. Extensive experiments demonstrate that MICE significantly reduces constraint violations while preserving policy performance comparable to baselines.
Extreme Value Policy Optimization for Safe Reinforcement Learning
Jan 17, 2026Ensuring safety is a critical challenge in applying Reinforcement Learning (RL) to real-world scenarios. Constrained Reinforcement Learning (CRL) addresses this by maximizing returns under predefined constraints, typically formulated as the expected cumulative cost. However, expectation-based constraints overlook rare but high-impact extreme value events in the tail distribution, such as black swan incidents, which can lead to severe constraint violations. To address this issue, we propose the Extreme Value policy Optimization (EVO) algorithm, leveraging Extreme Value Theory (EVT) to model and exploit extreme reward and cost samples, reducing constraint violations. EVO introduces an extreme quantile optimization objective to explicitly capture extreme samples in the cost tail distribution. Additionally, we propose an extreme prioritization mechanism during replay, amplifying the learning signal from rare but high-impact extreme samples. Theoretically, we establish upper bounds on expected constraint violations during policy updates, guaranteeing strict constraint satisfaction at a zero-violation quantile level. Further, we demonstrate that EVO achieves a lower probability of constraint violations than expectation-based methods and exhibits lower variance than quantile regression methods. Extensive experiments show that EVO significantly reduces constraint violations during training while maintaining competitive policy performance compared to baselines.
Improving LLM Reasoning with Homophily-aware Structural and Semantic Text-Attributed Graph Compression
Jan 13, 2026Large language models (LLMs) have demonstrated promising capabilities in Text-Attributed Graph (TAG) understanding. Recent studies typically focus on verbalizing the graph structures via handcrafted prompts, feeding the target node and its neighborhood context into LLMs. However, constrained by the context window, existing methods mainly resort to random sampling, often implemented via dropping node/edge randomly, which inevitably introduces noise and cause reasoning instability. We argue that graphs inherently contain rich structural and semantic information, and that their effective exploitation can unlock potential gains in LLMs reasoning performance. To this end, we propose Homophily-aware Structural and Semantic Compression for LLMs (HS2C), a framework centered on exploiting graph homophily. Structurally, guided by the principle of Structural Entropy minimization, we perform a global hierarchical partition that decodes the graph's essential topology. This partition identifies naturally cohesive, homophilic communities, while discarding stochastic connectivity noise. Semantically, we deliver the detected structural homophily to the LLM, empowering it to perform differentiated semantic aggregation based on predefined community type. This process compresses redundant background contexts into concise community-level consensus, selectively preserving semantically homophilic information aligned with the target nodes. Extensive experiments on 10 node-level benchmarks across LLMs of varying sizes and families demonstrate that, by feeding LLMs with structurally and semantically compressed inputs, HS2C simultaneously enhances the compression rate and downstream inference accuracy, validating its superiority and scalability. Extensions to 7 diverse graph-level benchmarks further consolidate HS2C's task generalizability.
CHAINSFORMER: Numerical Reasoning on Knowledge Graphs from a Chain Perspective
Apr 19, 2025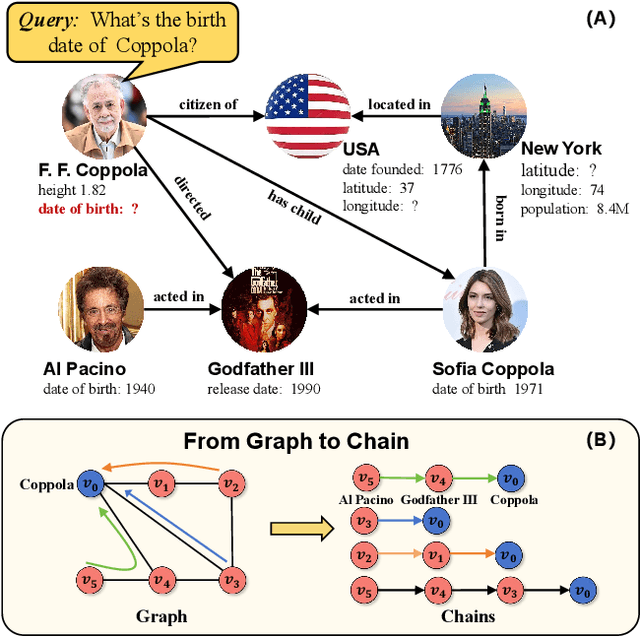
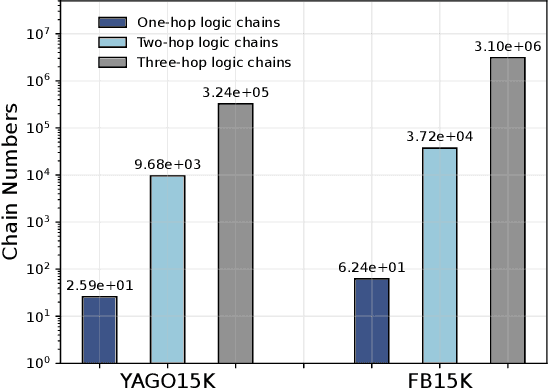
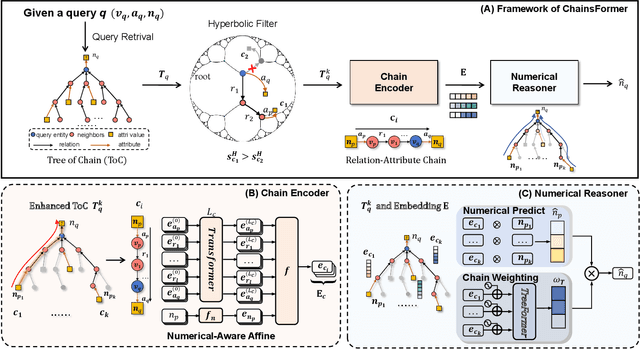
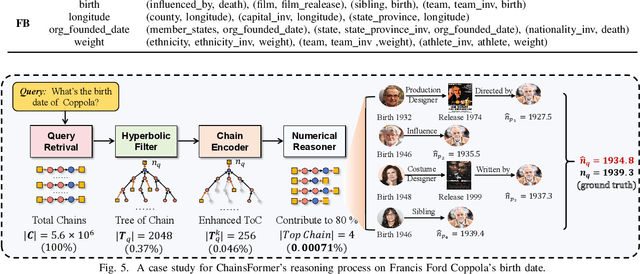
Reasoning over Knowledge Graphs (KGs) plays a pivotal role in knowledge graph completion or question answering systems, providing richer and more accurate triples and attributes. As numerical attributes become increasingly essential in characterizing entities and relations in KGs, the ability to reason over these attributes has gained significant importance. Existing graph-based methods such as Graph Neural Networks (GNNs) and Knowledge Graph Embeddings (KGEs), primarily focus on aggregating homogeneous local neighbors and implicitly embedding diverse triples. However, these approaches often fail to fully leverage the potential of logical paths within the graph, limiting their effectiveness in exploiting the reasoning process. To address these limitations, we propose ChainsFormer, a novel chain-based framework designed to support numerical reasoning. Chainsformer not only explicitly constructs logical chains but also expands the reasoning depth to multiple hops. Specially, we introduces Relation-Attribute Chains (RA-Chains), a specialized logic chain, to model sequential reasoning patterns. ChainsFormer captures the step-by-step nature of multi-hop reasoning along RA-Chains by employing sequential in-context learning. To mitigate the impact of noisy chains, we propose a hyperbolic affinity scoring mechanism that selects relevant logic chains in a variable-resolution space. Furthermore, ChainsFormer incorporates an attention-based numerical reasoner to identify critical reasoning paths, enhancing both reasoning accuracy and transparency. Experimental results demonstrate that ChainsFormer significantly outperforms state-of-the-art methods, achieving up to a 20.0% improvement in performance. The implementations are available at https://github.com/zhaodazhuang2333/ChainsFormer.
AceParse: A Comprehensive Dataset with Diverse Structured Texts for Academic Literature Parsing
Sep 16, 2024With the development of data-centric AI, the focus has shifted from model-driven approaches to improving data quality. Academic literature, as one of the crucial types, is predominantly stored in PDF formats and needs to be parsed into texts before further processing. However, parsing diverse structured texts in academic literature remains challenging due to the lack of datasets that cover various text structures. In this paper, we introduce AceParse, the first comprehensive dataset designed to support the parsing of a wide range of structured texts, including formulas, tables, lists, algorithms, and sentences with embedded mathematical expressions. Based on AceParse, we fine-tuned a multimodal model, named AceParser, which accurately parses various structured texts within academic literature. This model outperforms the previous state-of-the-art by 4.1% in terms of F1 score and by 5% in Jaccard Similarity, demonstrating the potential of multimodal models in academic literature parsing. Our dataset is available at https://github.com/JHW5981/AceParse.
Unlock the Power of Frozen LLMs in Knowledge Graph Completion
Aug 13, 2024Classical knowledge graph completion (KGC) methods rely solely on structural information, struggling with the inherent sparsity of knowledge graphs (KGs). Large Language Models (LLMs) learn extensive knowledge from large corpora with powerful context modeling, which is ideal for mitigating the limitations of previous methods. Directly fine-tuning LLMs offers great capability but comes at the cost of huge time and memory consumption, while utilizing frozen LLMs yields suboptimal results. In this work, we aim to leverage LLMs for KGC effectively and efficiently. We capture the context-aware hidden states of knowledge triples by employing prompts to stimulate the intermediate layers of LLMs. We then train a data-efficient classifier on these hidden states to harness the inherent capabilities of frozen LLMs in KGC. We also generate entity descriptions with subgraph sampling on KGs, reducing the ambiguity of triplets and enriching the knowledge representation. Extensive experiments on standard benchmarks showcase the efficiency and effectiveness of our approach. We outperform classical KGC methods on most datasets and match the performance of fine-tuned LLMs. Additionally, compared to fine-tuned LLMs, we boost GPU memory efficiency by \textbf{$188\times$} and speed up training+inference by \textbf{$13.48\times$}.
AutoFAIR : Automatic Data FAIRification via Machine Reading
Aug 07, 2024



The explosive growth of data fuels data-driven research, facilitating progress across diverse domains. The FAIR principles emerge as a guiding standard, aiming to enhance the findability, accessibility, interoperability, and reusability of data. However, current efforts primarily focus on manual data FAIRification, which can only handle targeted data and lack efficiency. To address this issue, we propose AutoFAIR, an architecture designed to enhance data FAIRness automately. Firstly, We align each data and metadata operation with specific FAIR indicators to guide machine-executable actions. Then, We utilize Web Reader to automatically extract metadata based on language models, even in the absence of structured data webpage schemas. Subsequently, FAIR Alignment is employed to make metadata comply with FAIR principles by ontology guidance and semantic matching. Finally, by applying AutoFAIR to various data, especially in the field of mountain hazards, we observe significant improvements in findability, accessibility, interoperability, and reusability of data. The FAIRness scores before and after applying AutoFAIR indicate enhanced data value.
Exterior Penalty Policy Optimization with Penalty Metric Network under Constraints
Jul 22, 2024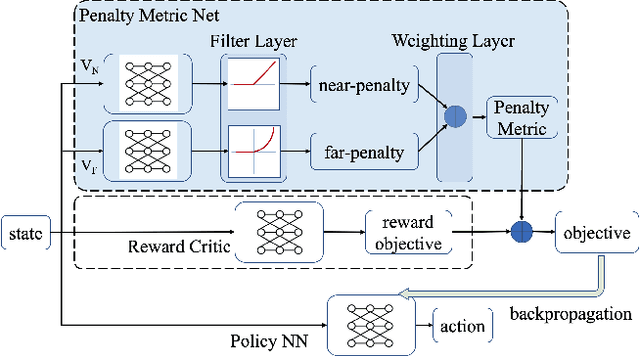
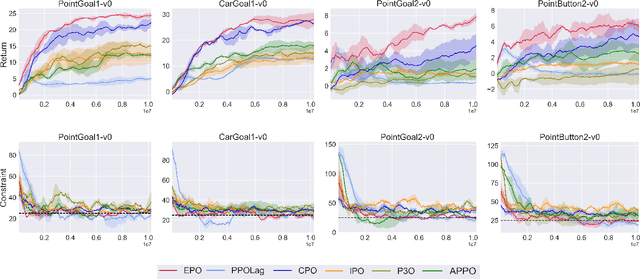
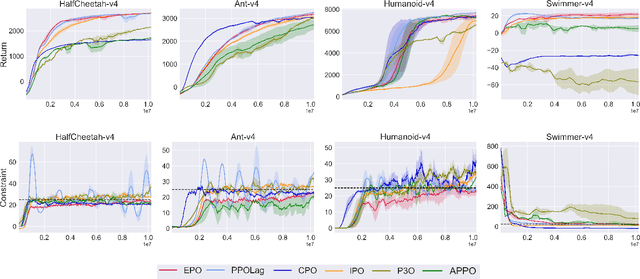
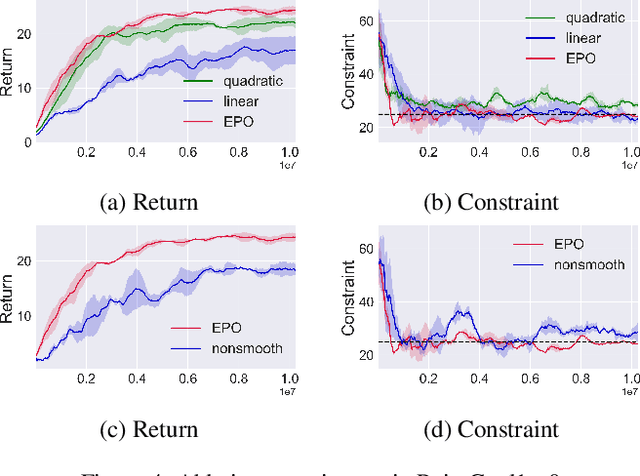
In Constrained Reinforcement Learning (CRL), agents explore the environment to learn the optimal policy while satisfying constraints. The penalty function method has recently been studied as an effective approach for handling constraints, which imposes constraints penalties on the objective to transform the constrained problem into an unconstrained one. However, it is challenging to choose appropriate penalties that balance policy performance and constraint satisfaction efficiently. In this paper, we propose a theoretically guaranteed penalty function method, Exterior Penalty Policy Optimization (EPO), with adaptive penalties generated by a Penalty Metric Network (PMN). PMN responds appropriately to varying degrees of constraint violations, enabling efficient constraint satisfaction and safe exploration. We theoretically prove that EPO consistently improves constraint satisfaction with a convergence guarantee. We propose a new surrogate function and provide worst-case constraint violation and approximation error. In practice, we propose an effective smooth penalty function, which can be easily implemented with a first-order optimizer. Extensive experiments are conducted, showing that EPO outperforms the baselines in terms of policy performance and constraint satisfaction with a stable training process, particularly on complex tasks.
OXYGENERATOR: Reconstructing Global Ocean Deoxygenation Over a Century with Deep Learning
May 12, 2024



Accurately reconstructing the global ocean deoxygenation over a century is crucial for assessing and protecting marine ecosystem. Existing expert-dominated numerical simulations fail to catch up with the dynamic variation caused by global warming and human activities. Besides, due to the high-cost data collection, the historical observations are severely sparse, leading to big challenge for precise reconstruction. In this work, we propose OxyGenerator, the first deep learning based model, to reconstruct the global ocean deoxygenation from 1920 to 2023. Specifically, to address the heterogeneity across large temporal and spatial scales, we propose zoning-varying graph message-passing to capture the complex oceanographic correlations between missing values and sparse observations. Additionally, to further calibrate the uncertainty, we incorporate inductive bias from dissolved oxygen (DO) variations and chemical effects. Compared with in-situ DO observations, OxyGenerator significantly outperforms CMIP6 numerical simulations, reducing MAPE by 38.77%, demonstrating a promising potential to understand the "breathless ocean" in data-driven manner.