 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D or 3D: Who Governs Salience in VLA Models? -- Tri-Stage Token Pruning Framework with Modality Salience Awareness
Apr 10, 2026Vision-Language-Action (VLA) models have emerged as the mainstream of embodied intelligence. Recent VLA models have expanded their input modalities from 2D-only to 2D+3D paradigms, forming multi-visual-modal VLA (MVLA) models. Despite achieving improved spatial perception, MVLA faces a greater acceleration demand due to the increased number of input tokens caused by modal expansion. Token pruning is an effective optimization methods tailored to MVLA models. However, existing token pruning schemes are designed for 2D-only VLA models, ignoring 2D/3D modality salience differences. In this paper, we follow the application process of multi-modal data in MVLA models and develop a tri-stage analysis to capture the discrepancy and dynamics of 2D/3D modality salience. Based on these, we propose a corresponding tri-stage token pruning framework for MVLA models to achieve optimal 2D/3D token selection and efficient pruning. Experiments show that our framework achieves up to a 2.55x inference speedup with minimal accuracy loss, while only costing 5.8% overhead. Our Code is coming soon.
Agentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025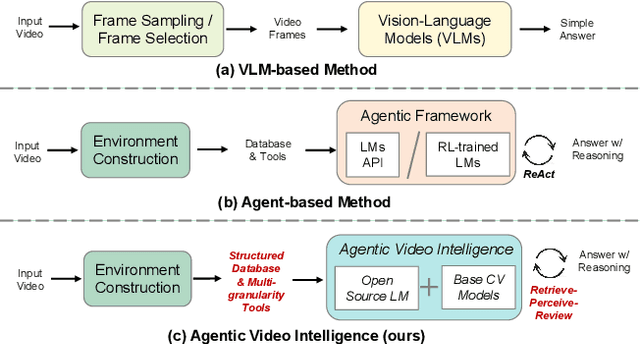
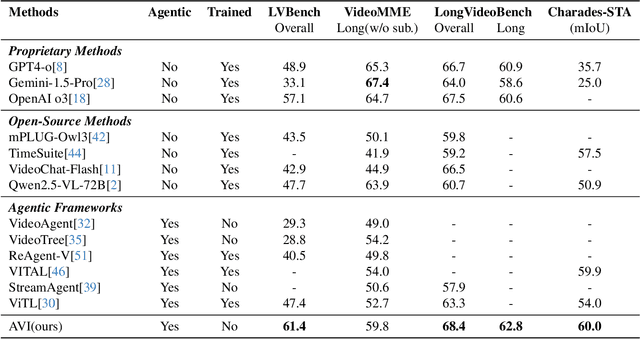
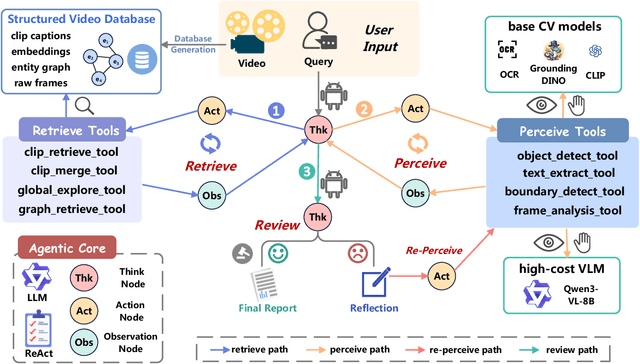
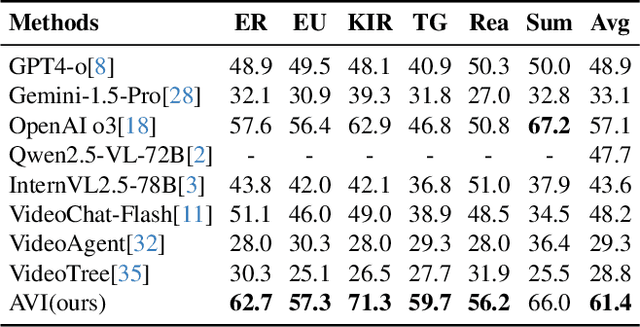
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
Panonut360: A Head and Eye Tracking Dataset for Panoramic Video
Mar 26, 2024With the rapid development and widespread application of VR/AR technology, maximizing the quality of immersive panoramic video services that match users' personal preferences and habits has become a long-standing challenge. Understanding the saliency region where users focus, based on data collected with HMDs, can promote multimedia encoding, transmission, and quality assessment. At the same time, large-scale datasets are essential for researchers and developers to explore short/long-term user behavior patterns and train AI models related to panoramic videos. However, existing panoramic video datasets often include low-frequency user head or eye movement data through short-term videos only, lacking sufficient data for analyzing users' Field of View (FoV) and generating video saliency regions. Driven by these practical factors, in this paper, we present a head and eye tracking dataset involving 50 users (25 males and 25 females) watching 15 panoramic videos. The dataset provides details on the viewport and gaze attention locations of users. Besides, we present some statistics samples extracted from the dataset. For example, the deviation between head and eye movements challenges the widely held assumption that gaze attention decreases from the center of the FoV following a Gaussian distribution. Our analysis reveals a consistent downward offset in gaze fixations relative to the FoV in experimental settings involving multiple users and videos. That's why we name the dataset Panonut, a saliency weighting shaped like a donut. Finally, we also provide a script that generates saliency distributions based on given head or eye coordinates and pre-generated saliency distribution map sets of each video from the collected eye tracking data. The dataset is available on website: https://dianvrlab.github.io/Panonut360/.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023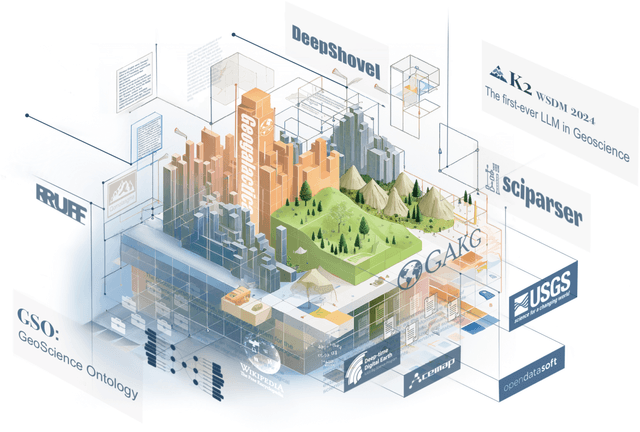

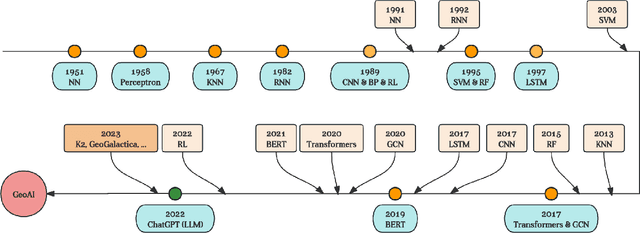
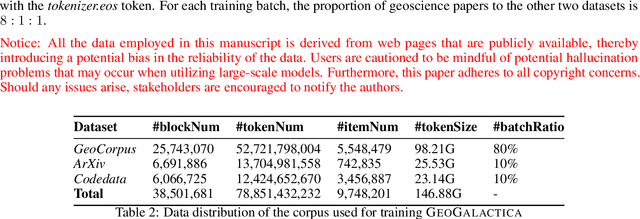
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
ADLight: A Universal Approach of Traffic Signal Control with Augmented Data Using Reinforcement Learning
Oct 24, 2022



Traffic signal control has the potential to reduce congestion in dynamic networks. Recent studies show that traffic signal control with reinforcement learning (RL) methods can significantly reduce the average waiting time. However, a shortcoming of existing methods is that they require model retraining for new intersections with different structures. In this paper, we propose a novel reinforcement learning approach with augmented data (ADLight) to train a universal model for intersections with different structures. We propose a new agent design incorporating features on movements and actions with set current phase duration to allow the generalized model to have the same structure for different intersections. A new data augmentation method named \textit{movement shuffle} is developed to improve the generalization performance. We also test the universal model with new intersections in Simulation of Urban MObility (SUMO). The results show that the performance of our approach is close to the models trained in a single environment directly (only a 5% loss of average waiting time), and we can reduce more than 80% of training time, which saves a lot of computational resources in scalable operations of traffic lights.