 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model for Lossless Image Compression with Visual Prompts
Feb 22, 2025


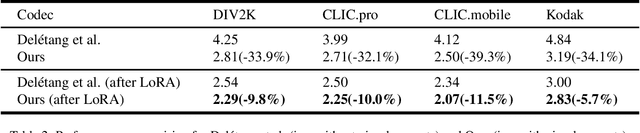
Recent advancements in deep learning have driven significant progress in lossless image compression. With the emergence of Large Language Models (LLMs), preliminary attempts have been made to leverage the extensive prior knowledge embedded in these pretrained models to enhance lossless image compression, particularly by improving the entropy model. However, a significant challenge remains in bridging the gap between the textual prior knowledge within LLMs and lossless image compression. To tackle this challenge and unlock the potential of LLMs, this paper introduces a novel paradigm for lossless image compression that incorporates LLMs with visual prompts. Specifically, we first generate a lossy reconstruction of the input image as visual prompts, from which we extract features to serve as visual embeddings for the LLM. The residual between the original image and the lossy reconstruction is then fed into the LLM along with these visual embeddings, enabling the LLM to function as an entropy model to predict the probability distribution of the residual. Extensive experiments on multiple benchmark datasets demonstrate our method achieves state-of-the-art compression performance, surpassing both traditional and learning-based lossless image codecs. Furthermore, our approach can be easily extended to images from other domains, such as medical and screen content images, achieving impressive performance. These results highlight the potential of LLMs for lossless image compression and may inspire further research in related directions.
Panonut360: A Head and Eye Tracking Dataset for Panoramic Video
Mar 26, 2024With the rapid development and widespread application of VR/AR technology, maximizing the quality of immersive panoramic video services that match users' personal preferences and habits has become a long-standing challenge. Understanding the saliency region where users focus, based on data collected with HMDs, can promote multimedia encoding, transmission, and quality assessment. At the same time, large-scale datasets are essential for researchers and developers to explore short/long-term user behavior patterns and train AI models related to panoramic videos. However, existing panoramic video datasets often include low-frequency user head or eye movement data through short-term videos only, lacking sufficient data for analyzing users' Field of View (FoV) and generating video saliency regions. Driven by these practical factors, in this paper, we present a head and eye tracking dataset involving 50 users (25 males and 25 females) watching 15 panoramic videos. The dataset provides details on the viewport and gaze attention locations of users. Besides, we present some statistics samples extracted from the dataset. For example, the deviation between head and eye movements challenges the widely held assumption that gaze attention decreases from the center of the FoV following a Gaussian distribution. Our analysis reveals a consistent downward offset in gaze fixations relative to the FoV in experimental settings involving multiple users and videos. That's why we name the dataset Panonut, a saliency weighting shaped like a donut. Finally, we also provide a script that generates saliency distributions based on given head or eye coordinates and pre-generated saliency distribution map sets of each video from the collected eye tracking data. The dataset is available on website: https://dianvrlab.github.io/Panonut360/.