 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Representation Image Compression at Ultra-Low Bitrates via Explicit Semantics and Implicit Textures
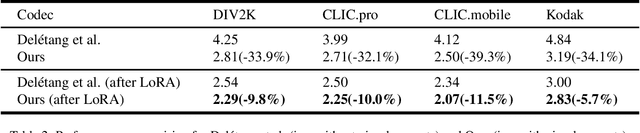
Feb 05, 2026While recent neural codecs achieve strong performance at low bitrates when optimized for perceptual quality, their effectiveness deteriorates significantly under ultra-low bitrate conditions. To mitigate this, generative compression methods leveraging semantic priors from pretrained models have emerged as a promising paradigm. However, existing approaches are fundamentally constrained by a tradeoff between semantic faithfulness and perceptual realism. Methods based on explicit representations preserve content structure but often lack fine-grained textures, whereas implicit methods can synthesize visually plausible details at the cost of semantic drift. In this work, we propose a unified framework that bridges this gap by coherently integrating explicit and implicit representations in a training-free manner. Specifically, We condition a diffusion model on explicit high-level semantics while employing reverse-channel coding to implicitly convey fine-grained details. Moreover, we introduce a plug-in encoder that enables flexible control of the distortion-perception tradeoff by modulating the implicit information. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art rate-perception performance, outperforming existing methods and surpassing DiffC by 29.92%, 19.33%, and 20.89% in DISTS BD-Rate on the Kodak, DIV2K, and CLIC2020 datasets, respectively.
Large Language Model for Lossless Image Compression with Visual Prompts
Feb 22, 2025


Recent advancements in deep learning have driven significant progress in lossless image compression. With the emergence of Large Language Models (LLMs), preliminary attempts have been made to leverage the extensive prior knowledge embedded in these pretrained models to enhance lossless image compression, particularly by improving the entropy model. However, a significant challenge remains in bridging the gap between the textual prior knowledge within LLMs and lossless image compression. To tackle this challenge and unlock the potential of LLMs, this paper introduces a novel paradigm for lossless image compression that incorporates LLMs with visual prompts. Specifically, we first generate a lossy reconstruction of the input image as visual prompts, from which we extract features to serve as visual embeddings for the LLM. The residual between the original image and the lossy reconstruction is then fed into the LLM along with these visual embeddings, enabling the LLM to function as an entropy model to predict the probability distribution of the residual. Extensive experiments on multiple benchmark datasets demonstrate our method achieves state-of-the-art compression performance, surpassing both traditional and learning-based lossless image codecs. Furthermore, our approach can be easily extended to images from other domains, such as medical and screen content images, achieving impressive performance. These results highlight the potential of LLMs for lossless image compression and may inspire further research in related directions.
Controllable Distortion-Perception Tradeoff Through Latent Diffusion for Neural Image Compression
Dec 16, 2024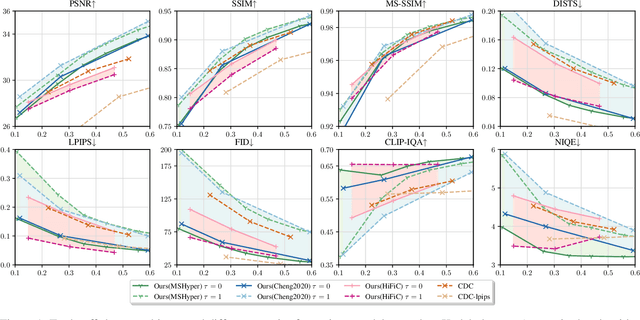

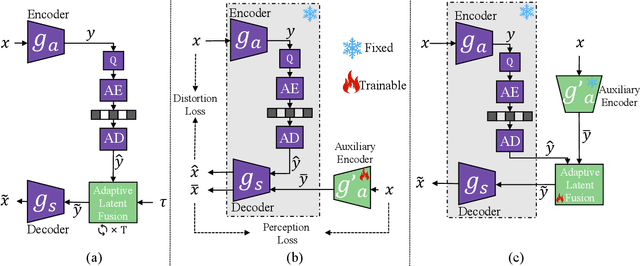
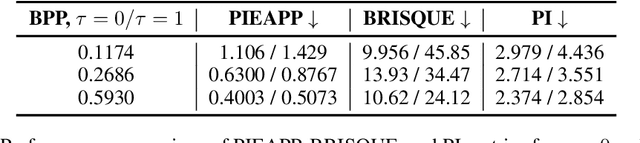
Neural image compression often faces a challenging trade-off among rate, distortion and perception. While most existing methods typically focus on either achieving high pixel-level fidelity or optimizing for perceptual metrics, we propose a novel approach that simultaneously addresses both aspects for a fixed neural image codec. Specifically, we introduce a plug-and-play module at the decoder side that leverages a latent diffusion process to transform the decoded features, enhancing either low distortion or high perceptual quality without altering the original image compression codec. Our approach facilitates fusion of original and transformed features without additional training, enabling users to flexibly adjust the balance between distortion and perception during inference. Extensive experimental results demonstrate that our method significantly enhances the pretrained codecs with a wide, adjustable distortion-perception range while maintaining their original compression capabilities. For instance, we can achieve more than 150% improvement in LPIPS-BDRate without sacrificing more than 1 dB in PSNR.