 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBus-Conditioned Zero-Shot Trajectory Generation via Task Arithmetic
Feb 13, 2026Mobility trajectory data provide essential support for smart city applications. However, such data are often difficult to obtain. Meanwhile, most existing trajectory generation methods implicitly assume that at least a subset of real mobility data from target city is available, which limits their applicability in data-inaccessible scenarios. In this work, we propose a new problem setting, called bus-conditioned zero-shot trajectory generation, where no mobility trajectories from a target city are accessible. The generation process relies solely on source city mobility data and publicly available bus timetables from both cities. Under this setting, we propose MobTA, the first approach to introduce task arithmetic into trajectory generation. MobTA models the parameter shift from bus-timetable-based trajectory generation to mobility trajectory generation in source city, and applies this shift to target city through arithmetic operations on task vectors. This enables trajectory generation that reflects target-city mobility patterns without requiring any real mobility data from it. Furthermore, we theoretically analyze MobTA's stability across base and instruction-tuned LLMs. Extensive experiments show that MobTA significantly outperforms existing methods, and achieves performance close to models finetuned using target city mobility trajectories.
SurfSplat: Conquering Feedforward 2D Gaussian Splatting with Surface Continuity Priors
Feb 03, 2026Reconstructing 3D scenes from sparse images remains a challenging task due to the difficulty of recovering accurate geometry and texture without optimization. Recent approaches leverage generalizable models to generate 3D scenes using 3D Gaussian Splatting (3DGS) primitive. However, they often fail to produce continuous surfaces and instead yield discrete, color-biased point clouds that appear plausible at normal resolution but reveal severe artifacts under close-up views. To address this issue, we present SurfSplat, a feedforward framework based on 2D Gaussian Splatting (2DGS) primitive, which provides stronger anisotropy and higher geometric precision. By incorporating a surface continuity prior and a forced alpha blending strategy, SurfSplat reconstructs coherent geometry together with faithful textures. Furthermore, we introduce High-Resolution Rendering Consistency (HRRC), a new evaluation metric designed to evaluate high-resolution reconstruction quality. Extensive experiments on RealEstate10K, DL3DV, and ScanNet demonstrate that SurfSplat consistently outperforms prior methods on both standard metrics and HRRC, establishing a robust solution for high-fidelity 3D reconstruction from sparse inputs. Project page: https://hebing-sjtu.github.io/SurfSplat-website/
Mixture-of-Experts for Personalized and Semantic-Aware Next Location Prediction
May 30, 2025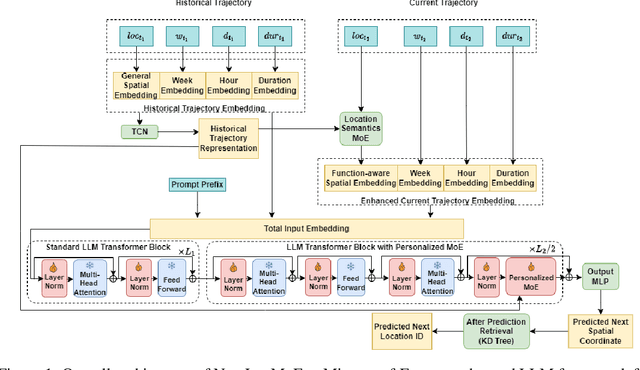
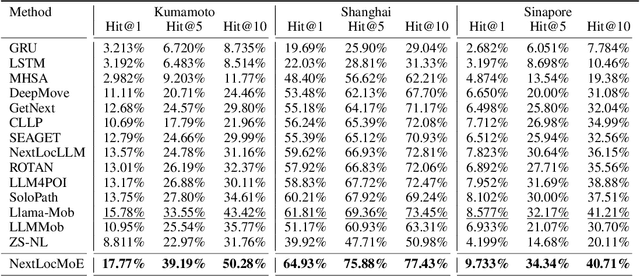
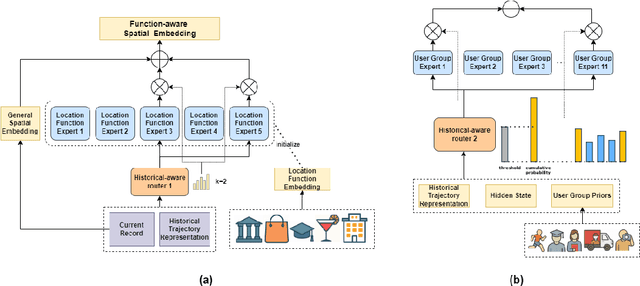
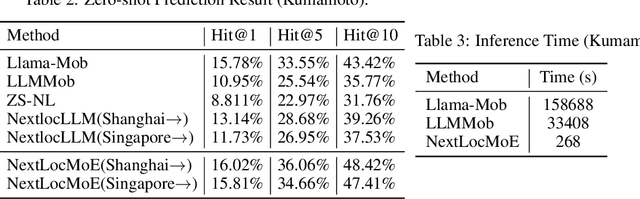
Next location prediction plays a critical role in understanding human mobility patterns. However, existing approaches face two core limitations: (1) they fall short in capturing the complex, multi-functional semantics of real-world locations; and (2) they lack the capacity to model heterogeneous behavioral dynamics across diverse user groups. To tackle these challenges, we introduce NextLocMoE, a novel framework built upon large language models (LLMs) and structured around a dual-level Mixture-of-Experts (MoE) design. Our architecture comprises two specialized modules: a Location Semantics MoE that operates at the embedding level to encode rich functional semantics of locations, and a Personalized MoE embedded within the Transformer backbone to dynamically adapt to individual user mobility patterns. In addition, we incorporate a history-aware routing mechanism that leverages long-term trajectory data to enhance expert selection and ensure prediction stability. Empirical evaluations across several real-world urban datasets show that NextLocMoE achieves superior performance in terms of predictive accuracy, cross-domain generalization, and interpretability
Large Language Model for Lossless Image Compression with Visual Prompts
Feb 22, 2025


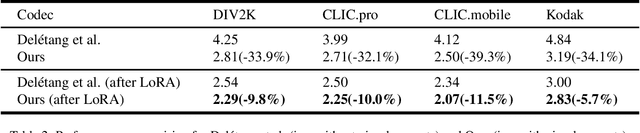
Recent advancements in deep learning have driven significant progress in lossless image compression. With the emergence of Large Language Models (LLMs), preliminary attempts have been made to leverage the extensive prior knowledge embedded in these pretrained models to enhance lossless image compression, particularly by improving the entropy model. However, a significant challenge remains in bridging the gap between the textual prior knowledge within LLMs and lossless image compression. To tackle this challenge and unlock the potential of LLMs, this paper introduces a novel paradigm for lossless image compression that incorporates LLMs with visual prompts. Specifically, we first generate a lossy reconstruction of the input image as visual prompts, from which we extract features to serve as visual embeddings for the LLM. The residual between the original image and the lossy reconstruction is then fed into the LLM along with these visual embeddings, enabling the LLM to function as an entropy model to predict the probability distribution of the residual. Extensive experiments on multiple benchmark datasets demonstrate our method achieves state-of-the-art compression performance, surpassing both traditional and learning-based lossless image codecs. Furthermore, our approach can be easily extended to images from other domains, such as medical and screen content images, achieving impressive performance. These results highlight the potential of LLMs for lossless image compression and may inspire further research in related directions.
nextlocllm: next location prediction using LLMs
Oct 11, 2024



Next location prediction is a critical task in human mobility analysis and serves as a foundation for various downstream applications. Existing methods typically rely on discrete IDs to represent locations, which inherently overlook spatial relationships and cannot generalize across cities. In this paper, we propose NextLocLLM, which leverages the advantages of large language models (LLMs) in processing natural language descriptions and their strong generalization capabilities for next location prediction. Specifically, instead of using IDs, NextLocLLM encodes locations based on continuous spatial coordinates to better model spatial relationships. These coordinates are further normalized to enable robust cross-city generalization. Another highlight of NextlocLLM is its LLM-enhanced POI embeddings. It utilizes LLMs' ability to encode each POI category's natural language description into embeddings. These embeddings are then integrated via nonlinear projections to form this LLM-enhanced POI embeddings, effectively capturing locations' functional attributes. Furthermore, task and data prompt prefix, together with trajectory embeddings, are incorporated as input for partly-frozen LLM backbone. NextLocLLM further introduces prediction retrieval module to ensure structural consistency in prediction. Experiments show that NextLocLLM outperforms existing models in next location prediction, excelling in both supervised and zero-shot settings.
Towards Graph Prompt Learning: A Survey and Beyond
Aug 26, 2024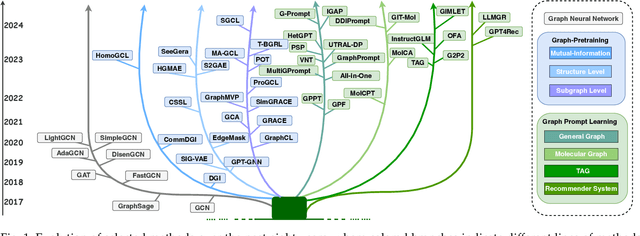
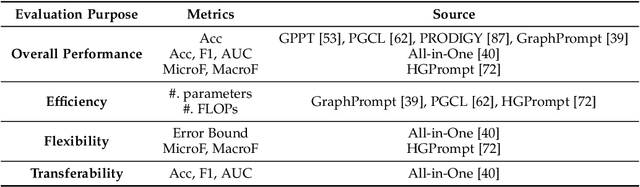
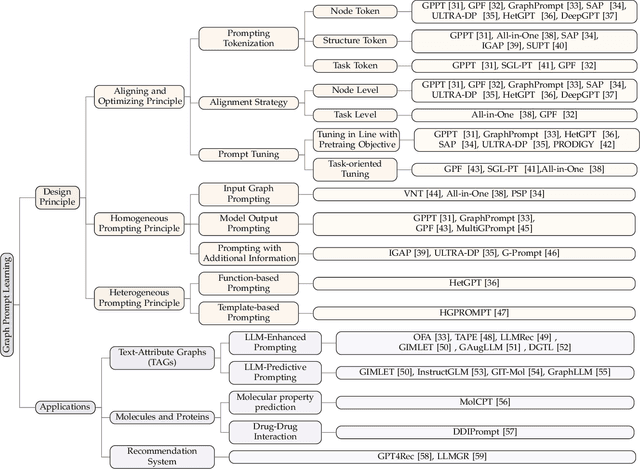
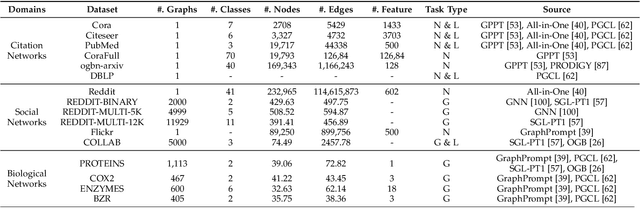
Large-scale "pre-train and prompt learning" paradigms have demonstrated remarkable adaptability, enabling broad applications across diverse domains such as question answering, image recognition, and multimodal retrieval. This approach fully leverages the potential of large-scale pre-trained models, reducing downstream data requirements and computational costs while enhancing model applicability across various tasks. Graphs, as versatile data structures that capture relationships between entities, play pivotal roles in fields such as social network analysis, recommender systems, and biological graphs. Despite the success of pre-train and prompt learning paradigms in Natural Language Processing (NLP) and Computer Vision (CV), their application in graph domains remains nascent. In graph-structured data, not only do the node and edge features often have disparate distributions, but the topological structures also differ significantly. This diversity in graph data can lead to incompatible patterns or gaps between pre-training and fine-tuning on downstream graphs. We aim to bridge this gap by summarizing methods for alleviating these disparities. This includes exploring prompt design methodologies, comparing related techniques, assessing application scenarios and datasets, and identifying unresolved problems and challenges. This survey categorizes over 100 relevant works in this field, summarizing general design principles and the latest applications, including text-attributed graphs, molecules, proteins, and recommendation systems. Through this extensive review, we provide a foundational understanding of graph prompt learning, aiming to impact not only the graph mining community but also the broader Artificial General Intelligence (AGI) community.
SpikeGraphormer: A High-Performance Graph Transformer with Spiking Graph Attention
Mar 21, 2024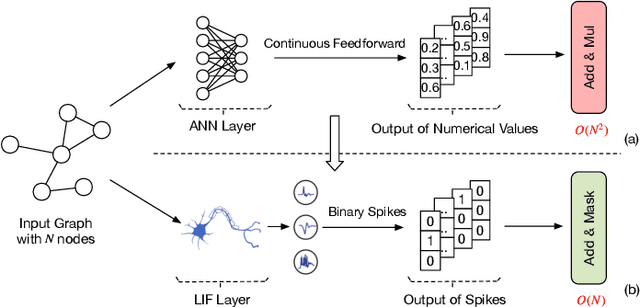

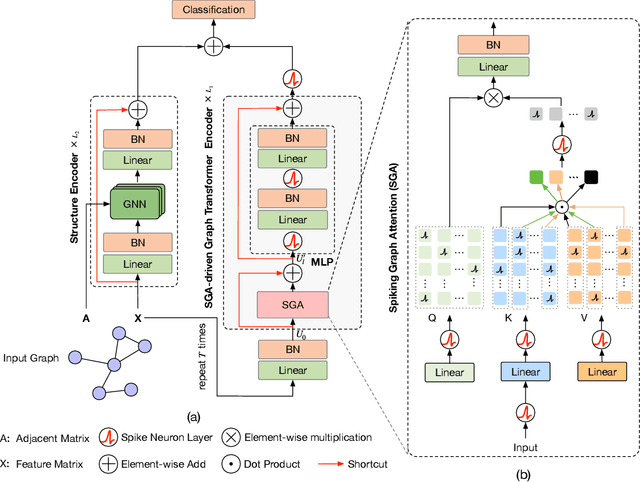

Recently, Graph Transformers have emerged as a promising solution to alleviate the inherent limitations of Graph Neural Networks (GNNs) and enhance graph representation performance. Unfortunately, Graph Transformers are computationally expensive due to the quadratic complexity inherent in self-attention when applied over large-scale graphs, especially for node tasks. In contrast, spiking neural networks (SNNs), with event-driven and binary spikes properties, can perform energy-efficient computation. In this work, we propose a novel insight into integrating SNNs with Graph Transformers and design a Spiking Graph Attention (SGA) module. The matrix multiplication is replaced by sparse addition and mask operations. The linear complexity enables all-pair node interactions on large-scale graphs with limited GPU memory. To our knowledge, our work is the first attempt to introduce SNNs into Graph Transformers. Furthermore, we design SpikeGraphormer, a Dual-branch architecture, combining a sparse GNN branch with our SGA-driven Graph Transformer branch, which can simultaneously perform all-pair node interactions and capture local neighborhoods. SpikeGraphormer consistently outperforms existing state-of-the-art approaches across various datasets and makes substantial improvements in training time, inference time, and GPU memory cost (10 ~ 20x lower than vanilla self-attention). It also performs well in cross-domain applications (image and text classification). We release our code at https://github.com/PHD-lanyu/SpikeGraphormer.
Security Matters: A Survey on Adversarial Machine Learning
Oct 23, 2018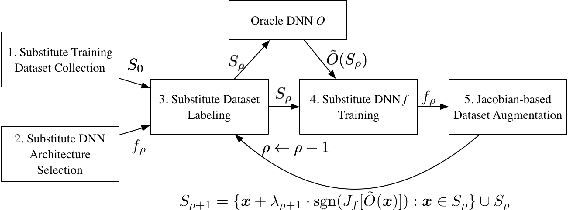
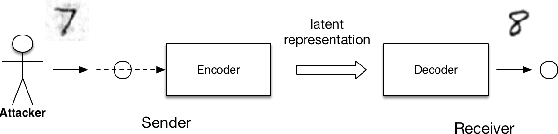
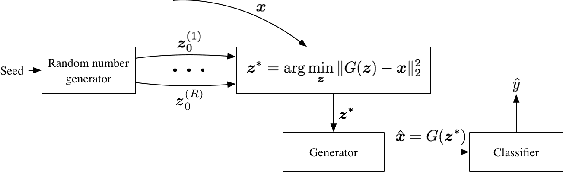
Adversarial machine learning is a fast growing research area, which considers the scenarios when machine learning systems may face potential adversarial attackers, who intentionally synthesize input data to make a well-trained model to make mistake. It always involves a defending side, usually a classifier, and an attacking side that aims to cause incorrect output. The earliest studies on the adversarial examples for machine learning algorithms start from the information security area, which considers a much wider varieties of attacking methods. But recent research focus that popularized by the deep learning community places strong emphasis on how the "imperceivable" perturbations on the normal inputs may cause dramatic mistakes by the deep learning with supposed super-human accuracy. This paper serves to give a comprehensive introduction to a range of aspects of the adversarial deep learning topic, including its foundations, typical attacking and defending strategies, and some extended studies.