 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO-Renderer: Generative Object Rendering with 3D-aware Controllable Video Diffusion Models
Mar 24, 2026Reconstructing a renderable 3D model from images is a useful but challenging task. Recent feedforward 3D reconstruction methods have demonstrated remarkable success in efficiently recovering geometry, but still cannot accurately model the complex appearances of these 3D reconstructed models. Recent diffusion-based generative models can synthesize realistic images or videos of an object using reference images without explicitly modeling its appearance, which provides a promising direction for object rendering, but lacks accurate control over the viewpoints. In this paper, we propose GO-Renderer, a unified framework integrating the reconstructed 3D proxies to guide the video generative models to achieve high-quality object rendering on arbitrary viewpoints under arbitrary lighting conditions. Our method not only enjoys the accurate viewpoint control using the reconstructed 3D proxy but also enables high-quality rendering in different lighting environments using diffusion generative models without explicitly modeling complex materials and lighting. Extensive experiments demonstrate that GO-Renderer achieves state-of-the-art performance across the object rendering tasks, including synthesizing images on new viewpoints, rendering the objects in a novel lighting environment, and inserting an object into an existing video.
Collaborative Prediction: To Join or To Disjoin Datasets
Jun 12, 2025With the recent rise of generative Artificial Intelligence (AI), the need of selecting high-quality dataset to improve machine learning models has garnered increasing attention. However, some part of this topic remains underexplored, even for simple prediction models. In this work, we study the problem of developing practical algorithms that select appropriate dataset to minimize population loss of our prediction model with high probability. Broadly speaking, we investigate when datasets from different sources can be effectively merged to enhance the predictive model's performance, and propose a practical algorithm with theoretical guarantees. By leveraging an oracle inequality and data-driven estimators, the algorithm reduces population loss with high probability. Numerical experiments demonstrate its effectiveness in both standard linear regression and broader machine learning applications. Code is available at https://github.com/kkrokii/collaborative_prediction.
WalnutData: A UAV Remote Sensing Dataset of Green Walnuts and Model Evaluation
Feb 27, 2025



The UAV technology is gradually maturing and can provide extremely powerful support for smart agriculture and precise monitoring. Currently, there is no dataset related to green walnuts in the field of agricultural computer vision. Thus, in order to promote the algorithm design in the field of agricultural computer vision, we used UAV to collect remote-sensing data from 8 walnut sample plots. Considering that green walnuts are subject to various lighting conditions and occlusion, we constructed a large-scale dataset with a higher-granularity of target features - WalnutData. This dataset contains a total of 30,240 images and 706,208 instances, and there are 4 target categories: being illuminated by frontal light and unoccluded (A1), being backlit and unoccluded (A2), being illuminated by frontal light and occluded (B1), and being backlit and occluded (B2). Subsequently, we evaluated many mainstream algorithms on WalnutData and used these evaluation results as the baseline standard. The dataset and all evaluation results can be obtained at https://github.com/1wuming/WalnutData.
Hierarchical Space-Time Attention for Micro-Expression Recognition
May 06, 2024



Micro-expression recognition (MER) aims to recognize the short and subtle facial movements from the Micro-expression (ME) video clips, which reveal real emotions. Recent MER methods mostly only utilize special frames from ME video clips or extract optical flow from these special frames. However, they neglect the relationship between movements and space-time, while facial cues are hidden within these relationships. To solve this issue, we propose the Hierarchical Space-Time Attention (HSTA). Specifically, we first process ME video frames and special frames or data parallelly by our cascaded Unimodal Space-Time Attention (USTA) to establish connections between subtle facial movements and specific facial areas. Then, we design Crossmodal Space-Time Attention (CSTA) to achieve a higher-quality fusion for crossmodal data. Finally, we hierarchically integrate USTA and CSTA to grasp the deeper facial cues. Our model emphasizes temporal modeling without neglecting the processing of special data, and it fuses the contents in different modalities while maintaining their respective uniqueness. Extensive experiments on the four benchmarks show the effectiveness of our proposed HSTA. Specifically, compared with the latest method on the CASME3 dataset, it achieves about 3% score improvement in seven-category classification.
GTC: GNN-Transformer Co-contrastive Learning for Self-supervised Heterogeneous Graph Representation
Mar 22, 2024Graph Neural Networks (GNNs) have emerged as the most powerful weapon for various graph tasks due to the message-passing mechanism's great local information aggregation ability. However, over-smoothing has always hindered GNNs from going deeper and capturing multi-hop neighbors. Unlike GNNs, Transformers can model global information and multi-hop interactions via multi-head self-attention and a proper Transformer structure can show more immunity to the over-smoothing problem. So, can we propose a novel framework to combine GNN and Transformer, integrating both GNN's local information aggregation and Transformer's global information modeling ability to eliminate the over-smoothing problem? To realize this, this paper proposes a collaborative learning scheme for GNN-Transformer and constructs GTC architecture. GTC leverages the GNN and Transformer branch to encode node information from different views respectively, and establishes contrastive learning tasks based on the encoded cross-view information to realize self-supervised heterogeneous graph representation. For the Transformer branch, we propose Metapath-aware Hop2Token and CG-Hetphormer, which can cooperate with GNN to attentively encode neighborhood information from different levels. As far as we know, this is the first attempt in the field of graph representation learning to utilize both GNN and Transformer to collaboratively capture different view information and conduct cross-view contrastive learning. The experiments on real datasets show that GTC exhibits superior performance compared with state-of-the-art methods. Codes can be available at https://github.com/PHD-lanyu/GTC.
SpikeGraphormer: A High-Performance Graph Transformer with Spiking Graph Attention
Mar 21, 2024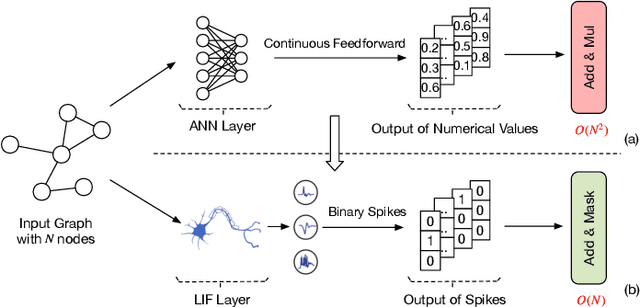

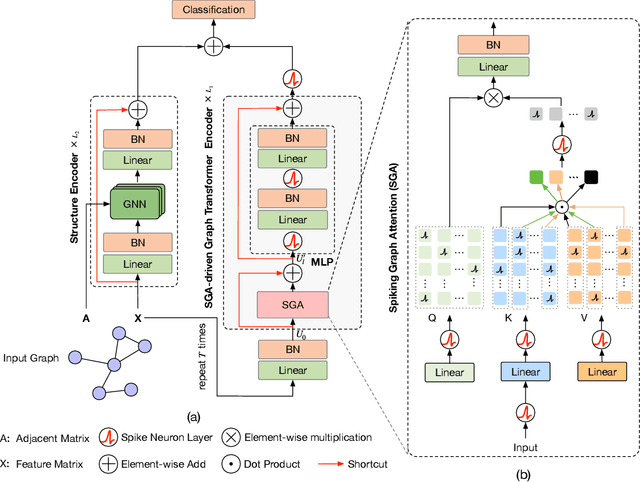

Recently, Graph Transformers have emerged as a promising solution to alleviate the inherent limitations of Graph Neural Networks (GNNs) and enhance graph representation performance. Unfortunately, Graph Transformers are computationally expensive due to the quadratic complexity inherent in self-attention when applied over large-scale graphs, especially for node tasks. In contrast, spiking neural networks (SNNs), with event-driven and binary spikes properties, can perform energy-efficient computation. In this work, we propose a novel insight into integrating SNNs with Graph Transformers and design a Spiking Graph Attention (SGA) module. The matrix multiplication is replaced by sparse addition and mask operations. The linear complexity enables all-pair node interactions on large-scale graphs with limited GPU memory. To our knowledge, our work is the first attempt to introduce SNNs into Graph Transformers. Furthermore, we design SpikeGraphormer, a Dual-branch architecture, combining a sparse GNN branch with our SGA-driven Graph Transformer branch, which can simultaneously perform all-pair node interactions and capture local neighborhoods. SpikeGraphormer consistently outperforms existing state-of-the-art approaches across various datasets and makes substantial improvements in training time, inference time, and GPU memory cost (10 ~ 20x lower than vanilla self-attention). It also performs well in cross-domain applications (image and text classification). We release our code at https://github.com/PHD-lanyu/SpikeGraphormer.
Significant Ties Graph Neural Networks for Continuous-Time Temporal Networks Modeling
Nov 12, 2022



Temporal networks are suitable for modeling complex evolving systems. It has a wide range of applications, such as social network analysis, recommender systems, and epidemiology. Recently, modeling such dynamic systems has drawn great attention in many domains. However, most existing approaches resort to taking discrete snapshots of the temporal networks and modeling all events with equal importance. This paper proposes Significant Ties Graph Neural Networks (STGNN), a novel framework that captures and describes significant ties. To better model the diversity of interactions, STGNN introduces a novel aggregation mechanism to organize the most significant historical neighbors' information and adaptively obtain the significance of node pairs. Experimental results on four real networks demonstrate the effectiveness of the proposed framework.
SCAI: A Spectral data Classification framework with Adaptive Inference for the IoT platform
Jun 24, 2022

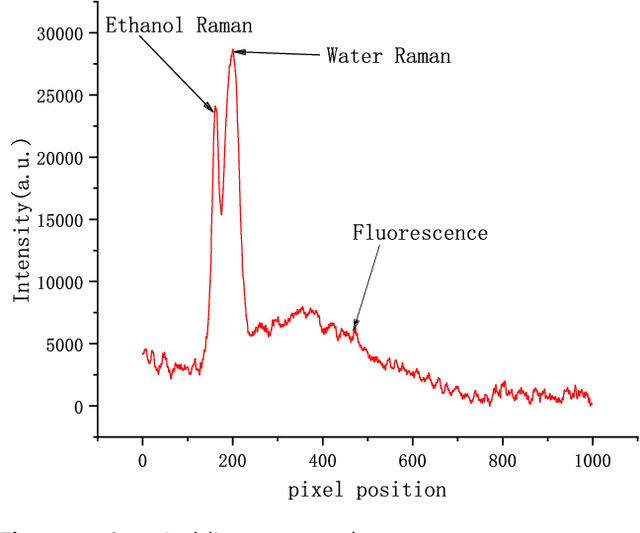
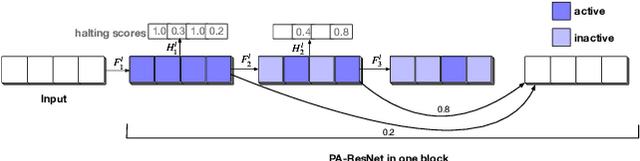
Currently, it is a hot research topic to realize accurate, efficient, and real-time identification of massive spectral data with the help of deep learning and IoT technology. Deep neural networks played a key role in spectral analysis. However, the inference of deeper models is performed in a static manner, and cannot be adjusted according to the device. Not all samples need to allocate all computation to reach confident prediction, which hinders maximizing the overall performance. To address the above issues, we propose a Spectral data Classification framework with Adaptive Inference. Specifically, to allocate different computations for different samples while better exploiting the collaboration among different devices, we leverage Early-exit architecture, place intermediate classifiers at different depths of the architecture, and the model outputs the results when the prediction confidence reaches a preset threshold. We propose a training paradigm of self-distillation learning, the deepest classifier performs soft supervision on the shallow ones to maximize their performance and training speed. At the same time, to mitigate the vulnerability of performance to the location and number settings of intermediate classifiers in the Early-exit paradigm, we propose a Position-Adaptive residual network. It can adjust the number of layers in each block at different curve positions, so it can focus on important positions of the curve (e.g.: Raman peak), and accurately allocate the appropriate computational budget based on task performance and computing resources. To the best of our knowledge, this paper is the first attempt to conduct optimization by adaptive inference for spectral detection under the IoT platform. We conducted many experiments, the experimental results show that our proposed method can achieve higher performance with less computational budget than existing methods.
CCasGNN: Collaborative Cascade Prediction Based on Graph Neural Networks
Dec 07, 2021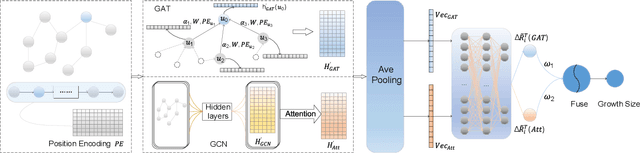
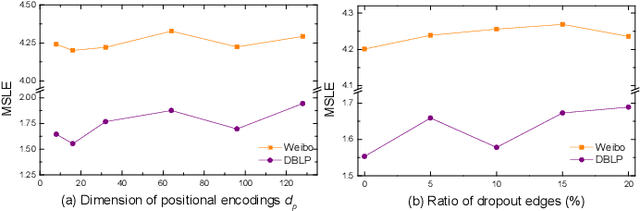
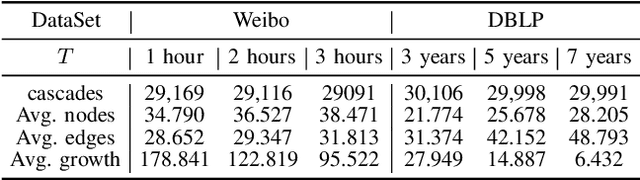
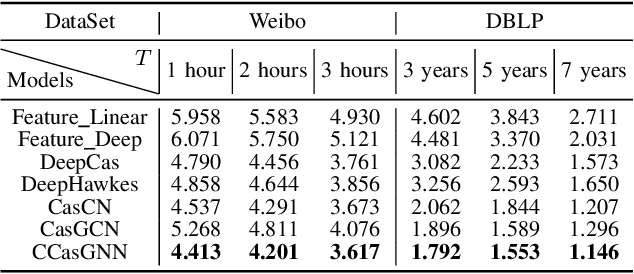
Cascade prediction aims at modeling information diffusion in the network. Most previous methods concentrate on mining either structural or sequential features from the network and the propagation path. Recent efforts devoted to combining network structure and sequence features by graph neural networks and recurrent neural networks. Nevertheless, the limitation of spectral or spatial methods restricts the improvement of prediction performance. Moreover, recurrent neural networks are time-consuming and computation-expensive, which causes the inefficiency of prediction. Here, we propose a novel method CCasGNN considering the individual profile, structural features, and sequence information. The method benefits from using a collaborative framework of GAT and GCN and stacking positional encoding into the layers of graph neural networks, which is different from all existing ones and demonstrates good performance. The experiments conducted on two real-world datasets confirm that our method significantly improves the prediction accuracy compared to state-of-the-art approaches. What's more, the ablation study investigates the contribution of each component in our method.