 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAI: A Spectral data Classification framework with Adaptive Inference for the IoT platform
Paper and Code
Jun 24, 2022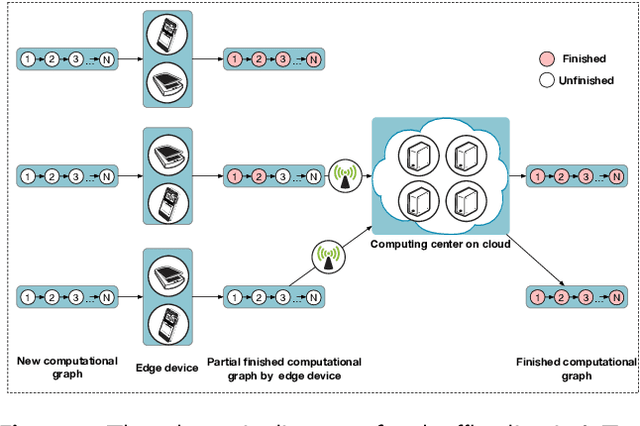

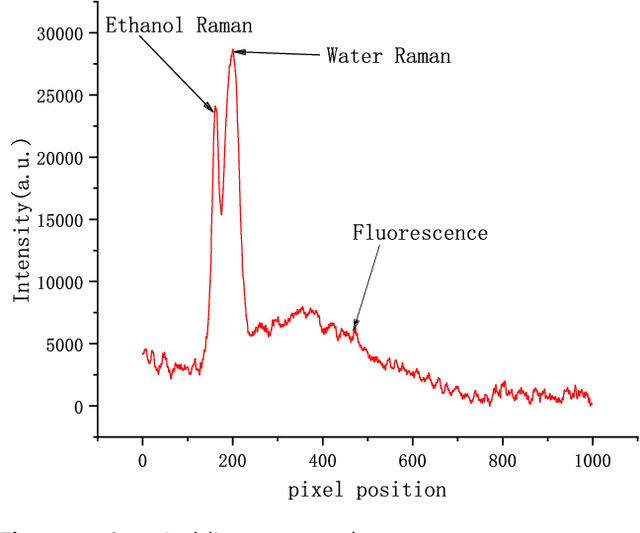
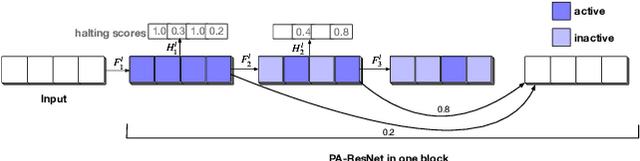
Currently, it is a hot research topic to realize accurate, efficient, and real-time identification of massive spectral data with the help of deep learning and IoT technology. Deep neural networks played a key role in spectral analysis. However, the inference of deeper models is performed in a static manner, and cannot be adjusted according to the device. Not all samples need to allocate all computation to reach confident prediction, which hinders maximizing the overall performance. To address the above issues, we propose a Spectral data Classification framework with Adaptive Inference. Specifically, to allocate different computations for different samples while better exploiting the collaboration among different devices, we leverage Early-exit architecture, place intermediate classifiers at different depths of the architecture, and the model outputs the results when the prediction confidence reaches a preset threshold. We propose a training paradigm of self-distillation learning, the deepest classifier performs soft supervision on the shallow ones to maximize their performance and training speed. At the same time, to mitigate the vulnerability of performance to the location and number settings of intermediate classifiers in the Early-exit paradigm, we propose a Position-Adaptive residual network. It can adjust the number of layers in each block at different curve positions, so it can focus on important positions of the curve (e.g.: Raman peak), and accurately allocate the appropriate computational budget based on task performance and computing resources. To the best of our knowledge, this paper is the first attempt to conduct optimization by adaptive inference for spectral detection under the IoT platform. We conducted many experiments, the experimental results show that our proposed method can achieve higher performance with less computational budget than existing methods.