 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Transfer Noise Patterns? A Multi-environment Spectrum Analysis Model Using Generated Cases
Aug 14, 2023



Spectrum analysis systems in online water quality testing are designed to detect types and concentrations of pollutants and enable regulatory agencies to respond promptly to pollution incidents. However, spectral data-based testing devices suffer from complex noise patterns when deployed in non-laboratory environments. To make the analysis model applicable to more environments, we propose a noise patterns transferring model, which takes the spectrum of standard water samples in different environments as cases and learns the differences in their noise patterns, thus enabling noise patterns to transfer to unknown samples. Unfortunately, the inevitable sample-level baseline noise makes the model unable to obtain the paired data that only differ in dataset-level environmental noise. To address the problem, we generate a sample-to-sample case-base to exclude the interference of sample-level noise on dataset-level noise learning, enhancing the system's learning performance. Experiments on spectral data with different background noises demonstrate the good noise-transferring ability of the proposed method against baseline systems ranging from wavelet denoising, deep neural networks, and generative models. From this research, we posit that our method can enhance the performance of DL models by generating high-quality cases. The source code is made publicly available online at https://github.com/Magnomic/CNST.
SCAI: A Spectral data Classification framework with Adaptive Inference for the IoT platform
Jun 24, 2022

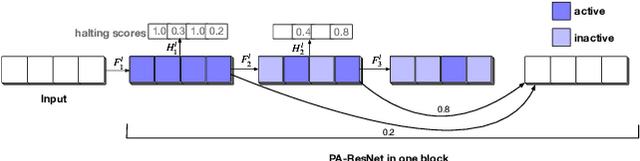
Currently, it is a hot research topic to realize accurate, efficient, and real-time identification of massive spectral data with the help of deep learning and IoT technology. Deep neural networks played a key role in spectral analysis. However, the inference of deeper models is performed in a static manner, and cannot be adjusted according to the device. Not all samples need to allocate all computation to reach confident prediction, which hinders maximizing the overall performance. To address the above issues, we propose a Spectral data Classification framework with Adaptive Inference. Specifically, to allocate different computations for different samples while better exploiting the collaboration among different devices, we leverage Early-exit architecture, place intermediate classifiers at different depths of the architecture, and the model outputs the results when the prediction confidence reaches a preset threshold. We propose a training paradigm of self-distillation learning, the deepest classifier performs soft supervision on the shallow ones to maximize their performance and training speed. At the same time, to mitigate the vulnerability of performance to the location and number settings of intermediate classifiers in the Early-exit paradigm, we propose a Position-Adaptive residual network. It can adjust the number of layers in each block at different curve positions, so it can focus on important positions of the curve (e.g.: Raman peak), and accurately allocate the appropriate computational budget based on task performance and computing resources. To the best of our knowledge, this paper is the first attempt to conduct optimization by adaptive inference for spectral detection under the IoT platform. We conducted many experiments, the experimental results show that our proposed method can achieve higher performance with less computational budget than existing methods.
Self-supervised Recommendation with Cross-channel Matching Representation and Hierarchical Contrastive Learning
Sep 14, 2021


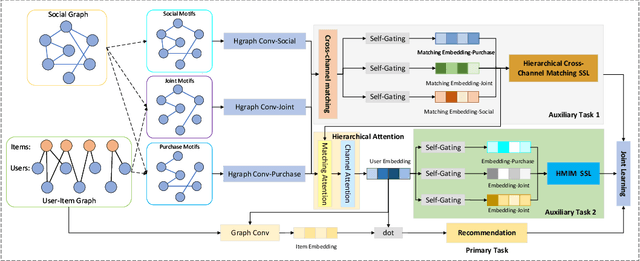
Recently, using different channels to model social semantic information, and using self-supervised learning tasks to maintain the characteristics of each channel when fusing the information, which has been proven to be a very promising work. However, how to deeply dig out the relationship between different channels and make full use of it while maintaining the uniqueness of each channel is a problem that has not been well studied and resolved in this field. Under such circumstances, this paper explores and verifies the deficiency of directly constructing contrastive learning tasks on different channels with practical experiments and proposes the scheme of interactive modeling and matching representation across different channels. This is the first attempt in the field of recommender systems, we believe the insight of this paper is inspirational to future self-supervised learning research based on multi-channel information. To solve this problem, we propose a cross-channel matching representation model based on attentive interaction, which realizes efficient modeling of the relationship between cross-channel information. Based on this, we also proposed a hierarchical self-supervised learning model, which realized two levels of self-supervised learning within and between channels and improved the ability of self-supervised tasks to autonomously mine different levels of potential information. We have conducted abundant experiments, and many experimental metrics on multiple public data sets show that the method proposed in this paper has a significant improvement compared with the state-of-the-art methods, no matter in the general or cold-start scenario. And in the experiment of model variant analysis, the benefits of the cross-channel matching representation model and the hierarchical self-supervised model proposed in this paper are also fully verified.
MHNF: Multi-hop Heterogeneous Neighborhood information Fusion graph representation learning
Jun 17, 2021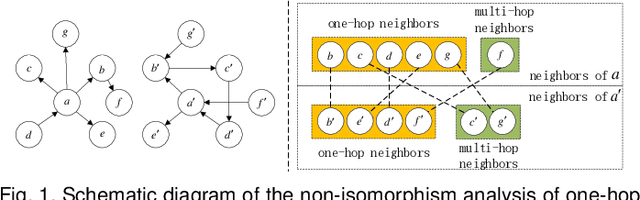

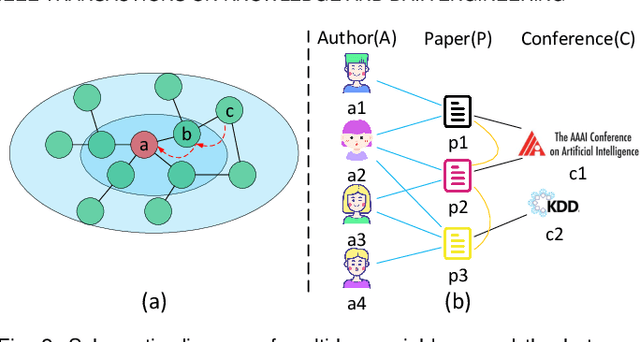
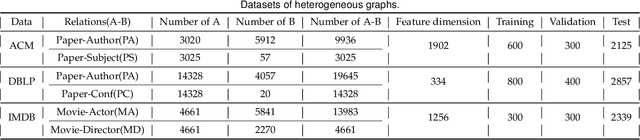
Attention mechanism enables the Graph Neural Networks(GNNs) to learn the attention weights between the target node and its one-hop neighbors, the performance is further improved. However, the most existing GNNs are oriented to homogeneous graphs and each layer can only aggregate the information of one-hop neighbors. Stacking multi-layer networks will introduce a lot of noise and easily lead to over smoothing. We propose a Multi-hop Heterogeneous Neighborhood information Fusion graph representation learning method (MHNF). Specifically, we first propose a hybrid metapath autonomous extraction model to efficiently extract multi-hop hybrid neighbors. Then, we propose a hop-level heterogeneous Information aggregation model, which selectively aggregates different-hop neighborhood information within the same hybrid metapath. Finally, a hierarchical semantic attention fusion model (HSAF) is proposed, which can efficiently integrate different-hop and different-path neighborhood information respectively. This paper can solve the problem of aggregating the multi-hop neighborhood information and can learn hybrid metapaths for target task, reducing the limitation of manually specifying metapaths. In addition, HSAF can extract the internal node information of the metapaths and better integrate the semantic information of different levels. Experimental results on real datasets show that MHNF is superior to state-of-the-art methods in node classification and clustering tasks (10.94% - 69.09% and 11.58% - 394.93% relative improvement on average, respectively).