 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Transfer Learning in Non-Stationary Data Streams
Sep 09, 2025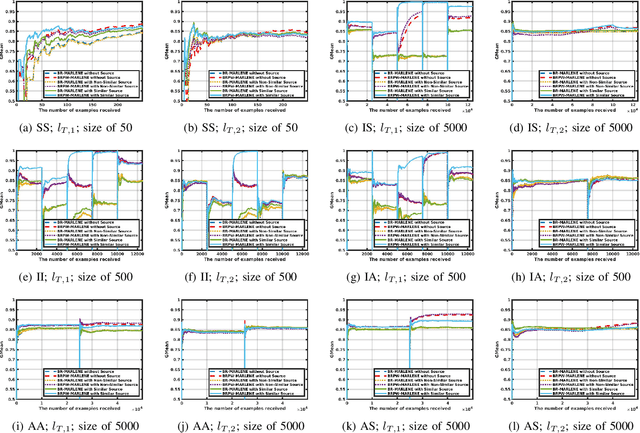



Label concepts in multi-label data streams often experience drift in non-stationary environments, either independently or in relation to other labels. Transferring knowledge between related labels can accelerate adaptation, yet research on multi-label transfer learning for data streams remains limited. To address this, we propose two novel transfer learning methods: BR-MARLENE leverages knowledge from different labels in both source and target streams for multi-label classification; BRPW-MARLENE builds on this by explicitly modelling and transferring pairwise label dependencies to enhance learning performance. Comprehensive experiments show that both methods outperform state-of-the-art multi-label stream approaches in non-stationary environments, demonstrating the effectiveness of inter-label knowledge transfer for improved predictive performance.
Deep Learning Approaches for Medical Imaging Under Varying Degrees of Label Availability: A Comprehensive Survey
Apr 15, 2025



Deep learning has achieved significant breakthroughs in medical imaging, but these advancements are often dependent on large, well-annotated datasets. However, obtaining such datasets poses a significant challenge, as it requires time-consuming and labor-intensive annotations from medical experts. Consequently, there is growing interest in learning paradigms such as incomplete, inexact, and absent supervision, which are designed to operate under limited, inexact, or missing labels. This survey categorizes and reviews the evolving research in these areas, analyzing around 600 notable contributions since 2018. It covers tasks such as image classification, segmentation, and detection across various medical application areas, including but not limited to brain, chest, and cardiac imaging. We attempt to establish the relationships among existing research studies in related areas. We provide formal definitions of different learning paradigms and offer a comprehensive summary and interpretation of various learning mechanisms and strategies, aiding readers in better understanding the current research landscape and ideas. We also discuss potential future research challenges.
Transformers4NewsRec: A Transformer-based News Recommendation Framework
Oct 17, 2024



Pre-trained transformer models have shown great promise in various natural language processing tasks, including personalized news recommendations. To harness the power of these models, we introduce Transformers4NewsRec, a new Python framework built on the \textbf{Transformers} library. This framework is designed to unify and compare the performance of various news recommendation models, including deep neural networks and graph-based models. Transformers4NewsRec offers flexibility in terms of model selection, data preprocessing, and evaluation, allowing both quantitative and qualitative analysis.
An AI System for Continuous Knee Osteoarthritis Severity Grading Using Self-Supervised Anomaly Detection with Limited Data
Jul 16, 2024The diagnostic accuracy and subjectivity of existing Knee Osteoarthritis (OA) ordinal grading systems has been a subject of on-going debate and concern. Existing automated solutions are trained to emulate these imperfect systems, whilst also being reliant on large annotated databases for fully-supervised training. This work proposes a three stage approach for automated continuous grading of knee OA that is built upon the principles of Anomaly Detection (AD); learning a robust representation of healthy knee X-rays and grading disease severity based on its distance to the centre of normality. In the first stage, SS-FewSOME is proposed, a self-supervised AD technique that learns the 'normal' representation, requiring only examples of healthy subjects and <3% of the labels that existing methods require. In the second stage, this model is used to pseudo label a subset of unlabelled data as 'normal' or 'anomalous', followed by denoising of pseudo labels with CLIP. The final stage involves retraining on labelled and pseudo labelled data using the proposed Dual Centre Representation Learning (DCRL) which learns the centres of two representation spaces; normal and anomalous. Disease severity is then graded based on the distance to the learned centres. The proposed methodology outperforms existing techniques by margins of up to 24% in terms of OA detection and the disease severity scores correlate with the Kellgren-Lawrence grading system at the same level as human expert performance. Code available at https://github.com/niamhbelton/SS-FewSOME_Disease_Severity_Knee_Osteoarthritis.
Breaking the Barrier: Selective Uncertainty-based Active Learning for Medical Image Segmentation
Jan 29, 2024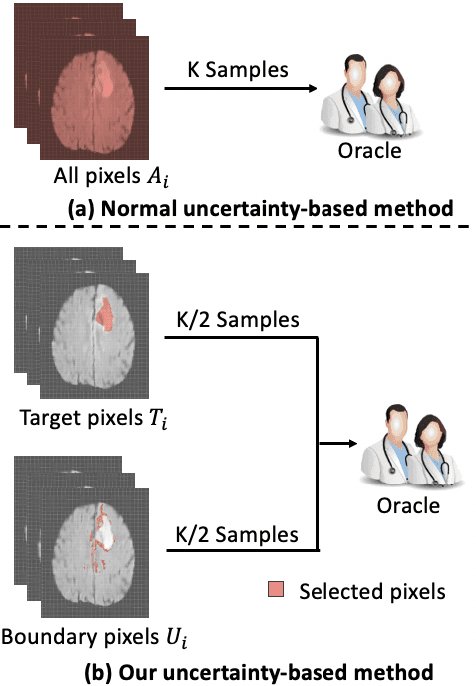

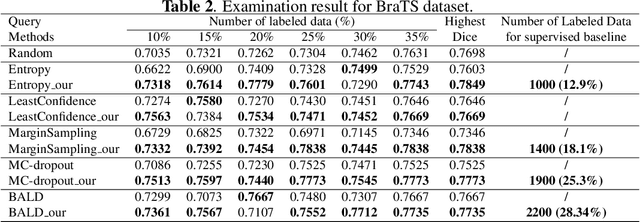
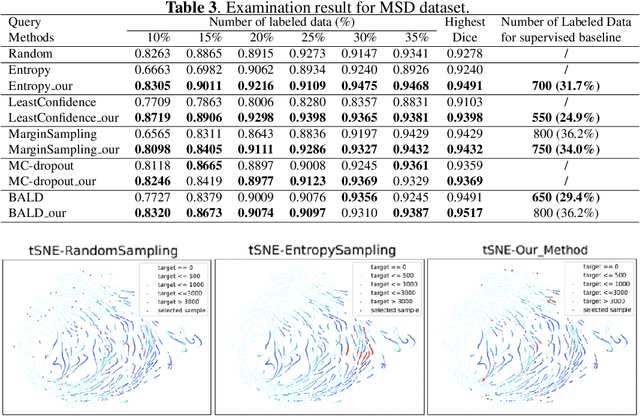
Active learning (AL) has found wide applications in medical image segmentation, aiming to alleviate the annotation workload and enhance performance. Conventional uncertainty-based AL methods, such as entropy and Bayesian, often rely on an aggregate of all pixel-level metrics. However, in imbalanced settings, these methods tend to neglect the significance of target regions, eg., lesions, and tumors. Moreover, uncertainty-based selection introduces redundancy. These factors lead to unsatisfactory performance, and in many cases, even underperform random sampling. To solve this problem, we introduce a novel approach called the Selective Uncertainty-based AL, avoiding the conventional practice of summing up the metrics of all pixels. Through a filtering process, our strategy prioritizes pixels within target areas and those near decision boundaries. This resolves the aforementioned disregard for target areas and redundancy. Our method showed substantial improvements across five different uncertainty-based methods and two distinct datasets, utilizing fewer labeled data to reach the supervised baseline and consistently achieving the highest overall performance. Our code is available at https://github.com/HelenMa9998/Selective\_Uncertainty\_AL.
RecPrompt: A Prompt Tuning Framework for News Recommendation Using Large Language Models
Dec 16, 2023



In the evolving field of personalized news recommendation, understanding the semantics of the underlying data is crucial. Large Language Models (LLMs) like GPT-4 have shown promising performance in understanding natural language. However, the extent of their applicability in news recommendation systems remains to be validated. This paper introduces RecPrompt, the first framework for news recommendation that leverages the capabilities of LLMs through prompt engineering. This system incorporates a prompt optimizer that applies an iterative bootstrapping process, enhancing the LLM-based recommender's ability to align news content with user preferences and interests more effectively. Moreover, this study offers insights into the effective use of LLMs in news recommendation, emphasizing both the advantages and the challenges of incorporating LLMs into recommendation systems.
Can We Transfer Noise Patterns? A Multi-environment Spectrum Analysis Model Using Generated Cases
Aug 14, 2023



Spectrum analysis systems in online water quality testing are designed to detect types and concentrations of pollutants and enable regulatory agencies to respond promptly to pollution incidents. However, spectral data-based testing devices suffer from complex noise patterns when deployed in non-laboratory environments. To make the analysis model applicable to more environments, we propose a noise patterns transferring model, which takes the spectrum of standard water samples in different environments as cases and learns the differences in their noise patterns, thus enabling noise patterns to transfer to unknown samples. Unfortunately, the inevitable sample-level baseline noise makes the model unable to obtain the paired data that only differ in dataset-level environmental noise. To address the problem, we generate a sample-to-sample case-base to exclude the interference of sample-level noise on dataset-level noise learning, enhancing the system's learning performance. Experiments on spectral data with different background noises demonstrate the good noise-transferring ability of the proposed method against baseline systems ranging from wavelet denoising, deep neural networks, and generative models. From this research, we posit that our method can enhance the performance of DL models by generating high-quality cases. The source code is made publicly available online at https://github.com/Magnomic/CNST.
Pure Spectral Graph Embeddings: Reinterpreting Graph Convolution for Top-N Recommendation
May 28, 2023The use of graph convolution in the development of recommender system algorithms has recently achieved state-of-the-art results in the collaborative filtering task (CF). While it has been demonstrated that the graph convolution operation is connected to a filtering operation on the graph spectral domain, the theoretical rationale for why this leads to higher performance on the collaborative filtering problem remains unknown. The presented work makes two contributions. First, we investigate the effect of using graph convolution throughout the user and item representation learning processes, demonstrating how the latent features learned are pushed from the filtering operation into the subspace spanned by the eigenvectors associated with the highest eigenvalues of the normalised adjacency matrix, and how vectors lying on this subspace are the optimal solutions for an objective function related to the sum of the prediction function over the training data. Then, we present an approach that directly leverages the eigenvectors to emulate the solution obtained through graph convolution, eliminating the requirement for a time-consuming gradient descent training procedure while also delivering higher performance on three real-world datasets.
Item Graph Convolution Collaborative Filtering for Inductive Recommendations
Mar 28, 2023Graph Convolutional Networks (GCN) have been recently employed as core component in the construction of recommender system algorithms, interpreting user-item interactions as the edges of a bipartite graph. However, in the absence of side information, the majority of existing models adopt an approach of randomly initialising the user embeddings and optimising them throughout the training process. This strategy makes these algorithms inherently transductive, curtailing their ability to generate predictions for users that were unseen at training time. To address this issue, we propose a convolution-based algorithm, which is inductive from the user perspective, while at the same time, depending only on implicit user-item interaction data. We propose the construction of an item-item graph through a weighted projection of the bipartite interaction network and to employ convolution to inject higher order associations into item embeddings, while constructing user representations as weighted sums of the items with which they have interacted. Despite not training individual embeddings for each user our approach achieves state of-the-art recommendation performance with respect to transductive baselines on four real-world datasets, showing at the same time robust inductive performance.
FewSOME: Few Shot Anomaly Detection
Jan 20, 2023



Recent years have seen considerable progress in the field of Anomaly Detection but at the cost of increasingly complex training pipelines. Such techniques require large amounts of training data, resulting in computationally expensive algorithms. We propose Few Shot anomaly detection (FewSOME), a deep One-Class Anomaly Detection algorithm with the ability to accurately detect anomalies having trained on 'few' examples of the normal class and no examples of the anomalous class. We describe FewSOME to be of low complexity given its low data requirement and short training time. FewSOME is aided by pretrained weights with an architecture based on Siamese Networks. By means of an ablation study, we demonstrate how our proposed loss, 'Stop Loss', improves the robustness of FewSOME. Our experiments demonstrate that FewSOME performs at state-of-the-art level on benchmark datasets MNIST, CIFAR-10, F-MNIST and MVTec AD while training on only 30 normal samples, a minute fraction of the data that existing methods are trained on. Most notably, we found that FewSOME outperforms even highly complex models in the setting where only few examples of the normal class exist. Moreover, our extensive experiments show FewSOME to be robust to contaminated datasets. We also report F1 score and Balanced Accuracy in addition to AUC as a benchmark for future techniques to be compared against.