 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyABD: The Abdominal Muscle Segmentation in Dynamic MRI Benchmark
Apr 25, 2026This work introduces DyABD, a novel and complex benchmark dataset of dynamic abdominal MRIs from patients with abdominal hernias and associated high quality abdominal muscle annotations. DyABD is the first-of-its-kind in four key ways; (1) it proposes the first abdominal muscle segmentation task, (2) the dynamic MRIs are acquired whilst the patients perform various exercises, introducing extreme anatomical variability, making it one of the most challenging segmentation datasets to date, (3) it includes both pre and post corrective MRIs and (4) DyABD promotes clinical research into the high recurrence rates of abdominal hernias. Beyond dataset introduction, this work provides a comprehensive evaluation of the generalisation capabilities of existing segmentation models across Supervised, Few Shot and Zero Shot paradigms on the unseen DyABD dataset. This work reveals that there is still room for substantial improvement in the field of medical image segmentation, with the majority of techniques achieving a Dice Coefficient of 0.82. This work therefore sheds light on the true progress of the field and redefines the benchmark for progress in medical image segmentation.
An AI System for Continuous Knee Osteoarthritis Severity Grading Using Self-Supervised Anomaly Detection with Limited Data
Jul 16, 2024The diagnostic accuracy and subjectivity of existing Knee Osteoarthritis (OA) ordinal grading systems has been a subject of on-going debate and concern. Existing automated solutions are trained to emulate these imperfect systems, whilst also being reliant on large annotated databases for fully-supervised training. This work proposes a three stage approach for automated continuous grading of knee OA that is built upon the principles of Anomaly Detection (AD); learning a robust representation of healthy knee X-rays and grading disease severity based on its distance to the centre of normality. In the first stage, SS-FewSOME is proposed, a self-supervised AD technique that learns the 'normal' representation, requiring only examples of healthy subjects and <3% of the labels that existing methods require. In the second stage, this model is used to pseudo label a subset of unlabelled data as 'normal' or 'anomalous', followed by denoising of pseudo labels with CLIP. The final stage involves retraining on labelled and pseudo labelled data using the proposed Dual Centre Representation Learning (DCRL) which learns the centres of two representation spaces; normal and anomalous. Disease severity is then graded based on the distance to the learned centres. The proposed methodology outperforms existing techniques by margins of up to 24% in terms of OA detection and the disease severity scores correlate with the Kellgren-Lawrence grading system at the same level as human expert performance. Code available at https://github.com/niamhbelton/SS-FewSOME_Disease_Severity_Knee_Osteoarthritis.
Distance-Aware eXplanation Based Learning
Sep 11, 2023



eXplanation Based Learning (XBL) is an interactive learning approach that provides a transparent method of training deep learning models by interacting with their explanations. XBL augments loss functions to penalize a model based on deviation of its explanations from user annotation of image features. The literature on XBL mostly depends on the intersection of visual model explanations and image feature annotations. We present a method to add a distance-aware explanation loss to categorical losses that trains a learner to focus on important regions of a training dataset. Distance is an appropriate approach for calculating explanation loss since visual model explanations such as Gradient-weighted Class Activation Mapping (Grad-CAMs) are not strictly bounded as annotations and their intersections may not provide complete information on the deviation of a model's focus from relevant image regions. In addition to assessing our model using existing metrics, we propose an interpretability metric for evaluating visual feature-attribution based model explanations that is more informative of the model's performance than existing metrics. We demonstrate performance of our proposed method on three image classification tasks.
Weighted Siamese Network to Predict the Time to Onset of Alzheimer's Disease from MRI Images
Apr 14, 2023Alzheimer's Disease (AD), which is the most common cause of dementia, is a progressive disease preceded by Mild Cognitive Impairment (MCI). Early detection of the disease is crucial for making treatment decisions. However, most of the literature on computer-assisted detection of AD focuses on classifying brain images into one of three major categories: healthy, MCI, and AD; or categorising MCI patients into one of (1) progressive: those who progress from MCI to AD at a future examination time during a given study period, and (2) stable: those who stay as MCI and never progress to AD. This misses the opportunity to accurately identify the trajectory of progressive MCI patients. In this paper, we revisit the brain image classification task for AD identification and re-frame it as an ordinal classification task to predict how close a patient is to the severe AD stage. To this end, we select progressive MCI patients from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and construct an ordinal dataset with a prediction target that indicates the time to progression to AD. We train a siamese network model to predict the time to onset of AD based on MRI brain images. We also propose a weighted variety of siamese networks and compare its performance to a baseline model. Our evaluations show that incorporating a weighting factor to siamese networks brings considerable performance gain at predicting how close input brain MRI images are to progressing to AD.
FewSOME: Few Shot Anomaly Detection
Jan 20, 2023



Recent years have seen considerable progress in the field of Anomaly Detection but at the cost of increasingly complex training pipelines. Such techniques require large amounts of training data, resulting in computationally expensive algorithms. We propose Few Shot anomaly detection (FewSOME), a deep One-Class Anomaly Detection algorithm with the ability to accurately detect anomalies having trained on 'few' examples of the normal class and no examples of the anomalous class. We describe FewSOME to be of low complexity given its low data requirement and short training time. FewSOME is aided by pretrained weights with an architecture based on Siamese Networks. By means of an ablation study, we demonstrate how our proposed loss, 'Stop Loss', improves the robustness of FewSOME. Our experiments demonstrate that FewSOME performs at state-of-the-art level on benchmark datasets MNIST, CIFAR-10, F-MNIST and MVTec AD while training on only 30 normal samples, a minute fraction of the data that existing methods are trained on. Most notably, we found that FewSOME outperforms even highly complex models in the setting where only few examples of the normal class exist. Moreover, our extensive experiments show FewSOME to be robust to contaminated datasets. We also report F1 score and Balanced Accuracy in addition to AUC as a benchmark for future techniques to be compared against.
Optimising Knee Injury Detection with Spatial Attention and Validating Localisation Ability
Aug 18, 2021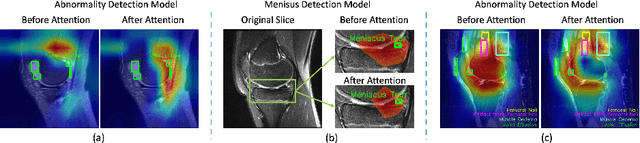


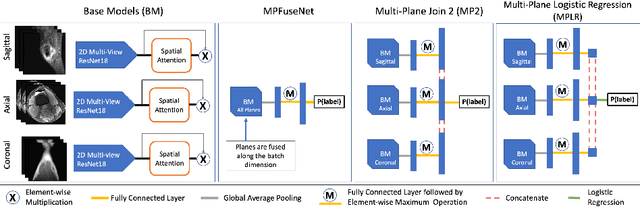
This work employs a pre-trained, multi-view Convolutional Neural Network (CNN) with a spatial attention block to optimise knee injury detection. An open-source Magnetic Resonance Imaging (MRI) data set with image-level labels was leveraged for this analysis. As MRI data is acquired from three planes, we compare our technique using data from a single-plane and multiple planes (multi-plane). For multi-plane, we investigate various methods of fusing the planes in the network. This analysis resulted in the novel 'MPFuseNet' network and state-of-the-art Area Under the Curve (AUC) scores for detecting Anterior Cruciate Ligament (ACL) tears and Abnormal MRIs, achieving AUC scores of 0.977 and 0.957 respectively. We then developed an objective metric, Penalised Localisation Accuracy (PLA), to validate the model's localisation ability. This metric compares binary masks generated from Grad-Cam output and the radiologist's annotations on a sample of MRIs. We also extracted explainability features in a model-agnostic approach that were then verified as clinically relevant by the radiologist.
Semi-Supervised Siamese Network for Identifying Bad Data in Medical Imaging Datasets
Aug 16, 2021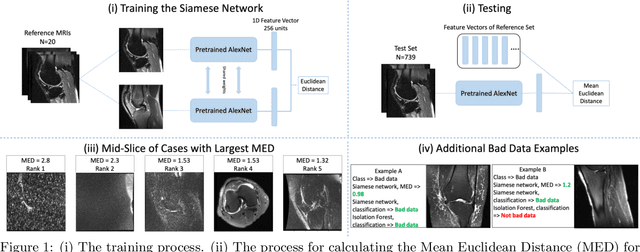
Noisy data present in medical imaging datasets can often aid the development of robust models that are equipped to handle real-world data. However, if the bad data contains insufficient anatomical information, it can have a severe negative effect on the model's performance. We propose a novel methodology using a semi-supervised Siamese network to identify bad data. This method requires only a small pool of 'reference' medical images to be reviewed by a non-expert human to ensure the major anatomical structures are present in the Field of View. The model trains on this reference set and identifies bad data by using the Siamese network to compute the distance between the reference set and all other medical images in the dataset. This methodology achieves an Area Under the Curve (AUC) of 0.989 for identifying bad data. Code will be available at https://git.io/JYFuV.
A Simplistic Machine Learning Approach to Contact Tracing
Dec 10, 2020
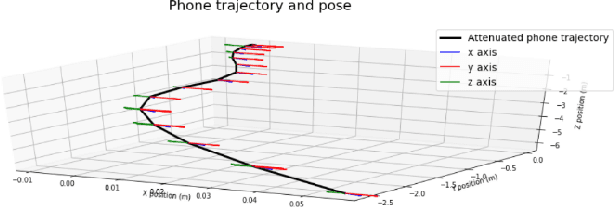
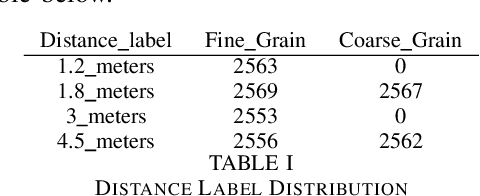
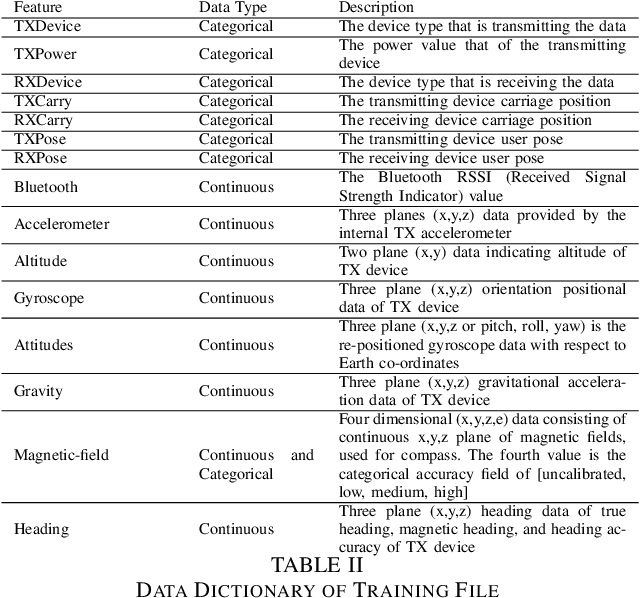
This report is based on the modified NIST challenge, Too Close For Too Long, provided by the SFI Centre for Machine Learning (ML-Labs). The modified challenge excludes the time calculation (too long) aspect. By handcrafting features from phone instrumental data we develop two machine learning models, a GBM and an MLP, to estimate distance between two phones. Our method is able to outperform the leading NIST challenge result by the Hong Kong University of Science and Technology (HKUST) by a significant margin.