 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
Feb 15, 2024
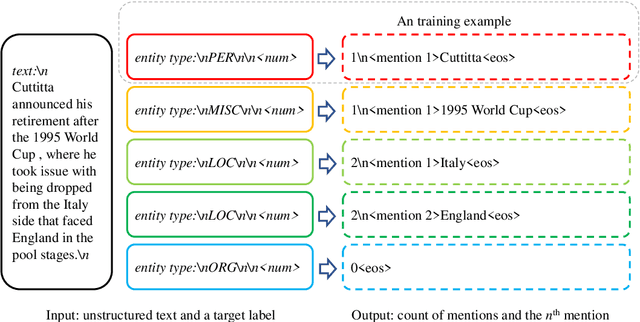
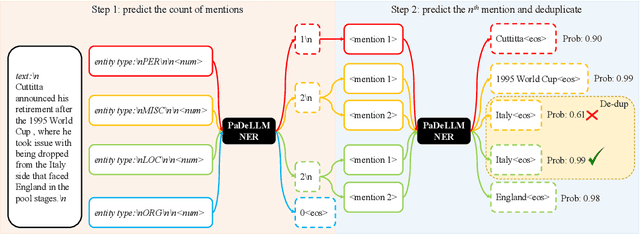
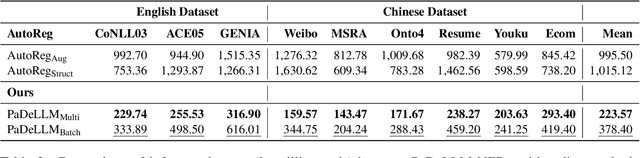
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
Explaining Knock-on Effects of Bias Mitigation
Dec 01, 2023In machine learning systems, bias mitigation approaches aim to make outcomes fairer across privileged and unprivileged groups. Bias mitigation methods work in different ways and have known "waterfall" effects, e.g., mitigating bias at one place may manifest bias elsewhere. In this paper, we aim to characterise impacted cohorts when mitigation interventions are applied. To do so, we treat intervention effects as a classification task and learn an explainable meta-classifier to identify cohorts that have altered outcomes. We examine a range of bias mitigation strategies that work at various stages of the model life cycle. We empirically demonstrate that our meta-classifier is able to uncover impacted cohorts. Further, we show that all tested mitigation strategies negatively impact a non-trivial fraction of cases, i.e., people who receive unfavourable outcomes solely on account of mitigation efforts. This is despite improvement in fairness metrics. We use these results as a basis to argue for more careful audits of static mitigation interventions that go beyond aggregate metrics.
Distance-Aware eXplanation Based Learning
Sep 11, 2023



eXplanation Based Learning (XBL) is an interactive learning approach that provides a transparent method of training deep learning models by interacting with their explanations. XBL augments loss functions to penalize a model based on deviation of its explanations from user annotation of image features. The literature on XBL mostly depends on the intersection of visual model explanations and image feature annotations. We present a method to add a distance-aware explanation loss to categorical losses that trains a learner to focus on important regions of a training dataset. Distance is an appropriate approach for calculating explanation loss since visual model explanations such as Gradient-weighted Class Activation Mapping (Grad-CAMs) are not strictly bounded as annotations and their intersections may not provide complete information on the deviation of a model's focus from relevant image regions. In addition to assessing our model using existing metrics, we propose an interpretability metric for evaluating visual feature-attribution based model explanations that is more informative of the model's performance than existing metrics. We demonstrate performance of our proposed method on three image classification tasks.
Unlearning Spurious Correlations in Chest X-ray Classification
Aug 03, 2023Medical image classification models are frequently trained using training datasets derived from multiple data sources. While leveraging multiple data sources is crucial for achieving model generalization, it is important to acknowledge that the diverse nature of these sources inherently introduces unintended confounders and other challenges that can impact both model accuracy and transparency. A notable confounding factor in medical image classification, particularly in musculoskeletal image classification, is skeletal maturation-induced bone growth observed during adolescence. We train a deep learning model using a Covid-19 chest X-ray dataset and we showcase how this dataset can lead to spurious correlations due to unintended confounding regions. eXplanation Based Learning (XBL) is a deep learning approach that goes beyond interpretability by utilizing model explanations to interactively unlearn spurious correlations. This is achieved by integrating interactive user feedback, specifically feature annotations. In our study, we employed two non-demanding manual feedback mechanisms to implement an XBL-based approach for effectively eliminating these spurious correlations. Our results underscore the promising potential of XBL in constructing robust models even in the presence of confounding factors.
Learning from Exemplary Explanations
Jul 12, 2023eXplanation Based Learning (XBL) is a form of Interactive Machine Learning (IML) that provides a model refining approach via user feedback collected on model explanations. Although the interactivity of XBL promotes model transparency, XBL requires a huge amount of user interaction and can become expensive as feedback is in the form of detailed annotation rather than simple category labelling which is more common in IML. This expense is exacerbated in high stakes domains such as medical image classification. To reduce the effort and expense of XBL we introduce a new approach that uses two input instances and their corresponding Gradient Weighted Class Activation Mapping (GradCAM) model explanations as exemplary explanations to implement XBL. Using a medical image classification task, we demonstrate that, using minimal human input, our approach produces improved explanations (+0.02, +3%) and achieves reduced classification performance (-0.04, -4%) when compared against a model trained without interactions.
Weighted Siamese Network to Predict the Time to Onset of Alzheimer's Disease from MRI Images
Apr 14, 2023Alzheimer's Disease (AD), which is the most common cause of dementia, is a progressive disease preceded by Mild Cognitive Impairment (MCI). Early detection of the disease is crucial for making treatment decisions. However, most of the literature on computer-assisted detection of AD focuses on classifying brain images into one of three major categories: healthy, MCI, and AD; or categorising MCI patients into one of (1) progressive: those who progress from MCI to AD at a future examination time during a given study period, and (2) stable: those who stay as MCI and never progress to AD. This misses the opportunity to accurately identify the trajectory of progressive MCI patients. In this paper, we revisit the brain image classification task for AD identification and re-frame it as an ordinal classification task to predict how close a patient is to the severe AD stage. To this end, we select progressive MCI patients from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and construct an ordinal dataset with a prediction target that indicates the time to progression to AD. We train a siamese network model to predict the time to onset of AD based on MRI brain images. We also propose a weighted variety of siamese networks and compare its performance to a baseline model. Our evaluations show that incorporating a weighting factor to siamese networks brings considerable performance gain at predicting how close input brain MRI images are to progressing to AD.
Identifying Spurious Correlations and Correcting them with an Explanation-based Learning
Dec 05, 2022
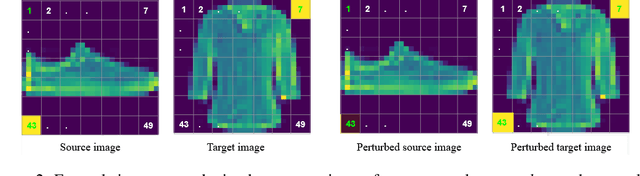
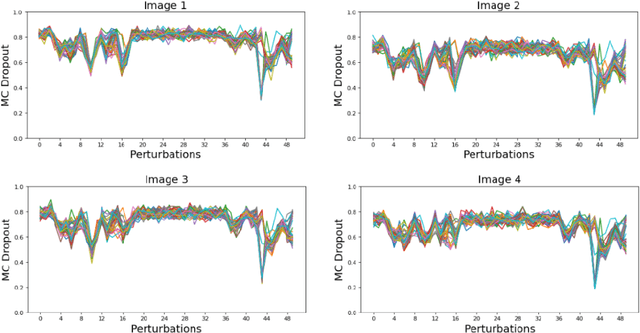
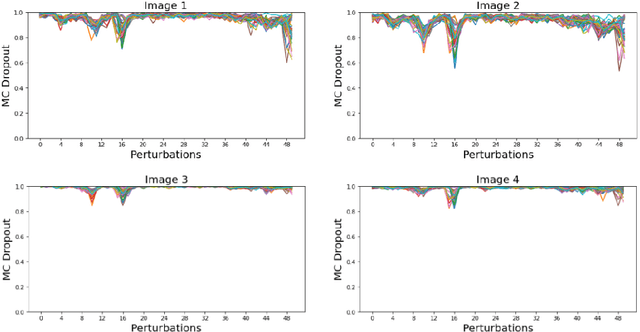
Identifying spurious correlations learned by a trained model is at the core of refining a trained model and building a trustworthy model. We present a simple method to identify spurious correlations that have been learned by a model trained for image classification problems. We apply image-level perturbations and monitor changes in certainties of predictions made using the trained model. We demonstrate this approach using an image classification dataset that contains images with synthetically generated spurious regions and show that the trained model was overdependent on spurious regions. Moreover, we remove the learned spurious correlations with an explanation based learning approach.
PUnifiedNER: a Prompting-based Unified NER System for Diverse Datasets
Nov 27, 2022



Much of named entity recognition (NER) research focuses on developing dataset-specific models based on data from the domain of interest, and a limited set of related entity types. This is frustrating as each new dataset requires a new model to be trained and stored. In this work, we present a ``versatile'' model -- the Prompting-based Unified NER system (PUnifiedNER) -- that works with data from different domains and can recognise up to 37 entity types simultaneously, and theoretically it could be as many as possible. By using prompt learning, PUnifiedNER is a novel approach that is able to jointly train across multiple corpora, implementing intelligent on-demand entity recognition. Experimental results show that PUnifiedNER leads to significant prediction benefits compared to dataset-specific models with impressively reduced model deployment costs. Furthermore, the performance of PUnifiedNER can achieve competitive or even better performance than state-of-the-art domain-specific methods for some datasets. We also perform comprehensive pilot and ablation studies to support in-depth analysis of each component in PUnifiedNER.
What Makes Pre-trained Language Models Better Zero/Few-shot Learners?
Sep 30, 2022

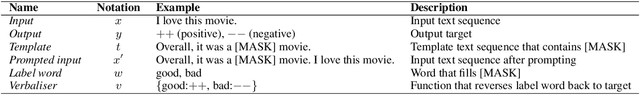
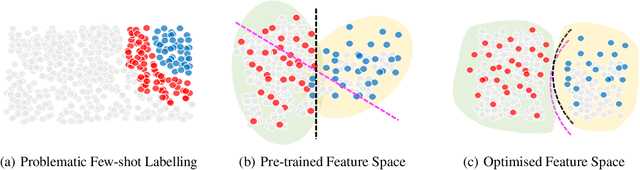
In this paper, we propose a theoretical framework to explain the efficacy of prompt learning in zero/few-shot scenarios. First, we prove that conventional pre-training and fine-tuning paradigm fails in few-shot scenarios due to overfitting the unrepresentative labelled data. We then detail the assumption that prompt learning is more effective because it empowers pre-trained language model that is built upon massive text corpora, as well as domain-related human knowledge to participate more in prediction and thereby reduces the impact of limited label information provided by the small training set. We further hypothesize that language discrepancy can measure the quality of prompting. Comprehensive experiments are performed to verify our assumptions. More remarkably, inspired by the theoretical framework, we propose an annotation-agnostic template selection method based on perplexity, which enables us to ``forecast'' the prompting performance in advance. This approach is especially encouraging because existing work still relies on development set to post-hoc evaluate templates. Experiments show that this method leads to significant prediction benefits compared to state-of-the-art zero-shot methods.
Impact of Feedback Type on Explanatory Interactive Learning
Sep 26, 2022Explanatory Interactive Learning (XIL) collects user feedback on visual model explanations to implement a Human-in-the-Loop (HITL) based interactive learning scenario. Different user feedback types will have different impacts on user experience and the cost associated with collecting feedback since different feedback types involve different levels of image annotation. Although XIL has been used to improve classification performance in multiple domains, the impact of different user feedback types on model performance and explanation accuracy is not well studied. To guide future XIL work we compare the effectiveness of two different user feedback types in image classification tasks: (1) instructing an algorithm to ignore certain spurious image features, and (2) instructing an algorithm to focus on certain valid image features. We use explanations from a Gradient-weighted Class Activation Mapping (GradCAM) based XIL model to support both feedback types. We show that identifying and annotating spurious image features that a model finds salient results in superior classification and explanation accuracy than user feedback that tells a model to focus on valid image features.