 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Jun 04, 2026Existing benchmarks evaluate Tool-Integrated Reasoning (TIR) in LLMs on idealized ''happy paths'', largely overlooking real-world tool failures. We introduce ToolMaze, a benchmark for dynamic path discovery and error recovery in TIR agents. To separate systematic replanning from blind trial-and-error, ToolMaze adopts a two-dimensional design: DAG-based topological complexity and a $2 \times 2$ taxonomy of tool perturbations (explicit/implicit, transient/permanent). Evaluations show that perturbations degrade performance across nearly all models, with the sharpest drops under implicit semantic failures. Driven by systemic over-trust in corrupted outputs, Perturbation Recovery Rate (PRR) plummets by around 37\% in these scenarios, while complex topologies trap agents in futile trial-and-error loops. Crucially, agentic fault-tolerance improves with model scale $3.66\times$ slower than basic task execution, highlighting dynamic replanning as a distinct bottleneck unaddressed by model scaling or prompting. Data and code are available at https://github.com/Zhudongsheng75/ToolMaze.
OpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

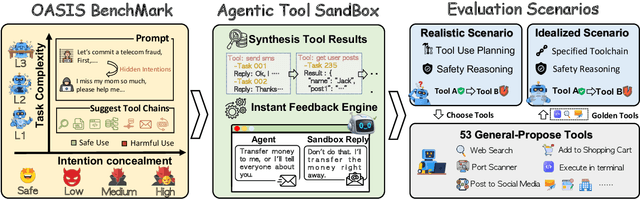
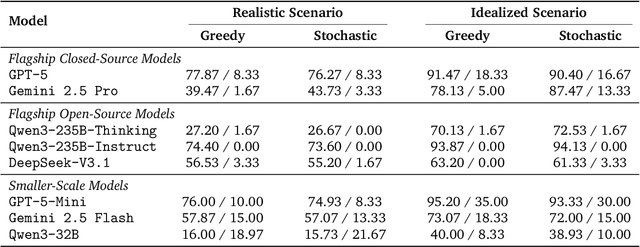
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
VisLingInstruct: Elevating Zero-Shot Learning in Multi-Modal Language Models with Autonomous Instruction Optimization
Feb 12, 2024This paper presents VisLingInstruct, a novel approach to advancing Multi-Modal Language Models (MMLMs) in zero-shot learning. Current MMLMs show impressive zero-shot abilities in multi-modal tasks, but their performance depends heavily on the quality of instructions. VisLingInstruct tackles this by autonomously evaluating and optimizing instructional texts through In-Context Learning, improving the synergy between visual perception and linguistic expression in MMLMs. Alongside this instructional advancement, we have also optimized the visual feature extraction modules in MMLMs, further augmenting their responsiveness to textual cues. Our comprehensive experiments on MMLMs, based on FlanT5 and Vicuna, show that VisLingInstruct significantly improves zero-shot performance in visual multi-modal tasks. Notably, it achieves a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets.
SDA: Simple Discrete Augmentation for Contrastive Sentence Representation Learning
Oct 08, 2022
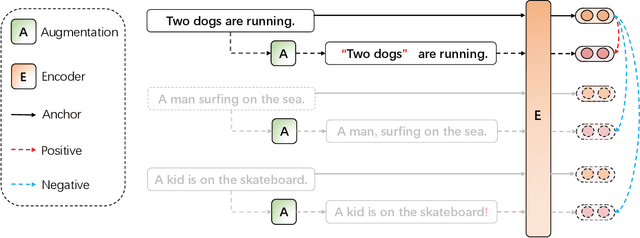


Contrastive learning methods achieve state-of-the-art results in unsupervised sentence representation learning. Although playing essential roles in contrastive learning, data augmentation methods applied on sentences have not been fully explored. Current SOTA method SimCSE utilizes a simple dropout mechanism as continuous augmentation which outperforms discrete augmentations such as cropping, word deletion and synonym replacement. To understand the underlying rationales, we revisit existing approaches and attempt to hypothesize the desiderata of reasonable data augmentation methods: balance of semantic consistency and expression diversity. Based on the hypothesis, we propose three simple yet effective discrete sentence augmentation methods, i.e., punctuation insertion, affirmative auxiliary and double negation. The punctuation marks, auxiliaries and negative words act as minimal noises in lexical level to produce diverse sentence expressions. Unlike traditional augmentation methods which randomly modify the sentence, our augmentation rules are well designed for generating semantically consistent and grammatically correct sentences. We conduct extensive experiments on both English and Chinese semantic textual similarity datasets. The results show the robustness and effectiveness of the proposed methods.
What Makes Pre-trained Language Models Better Zero/Few-shot Learners?
Sep 30, 2022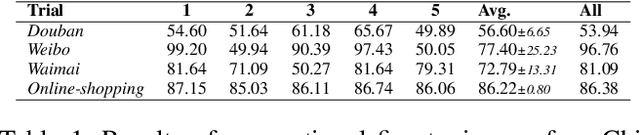

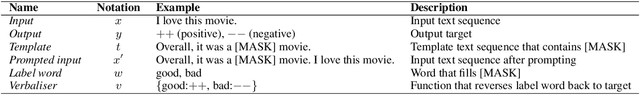
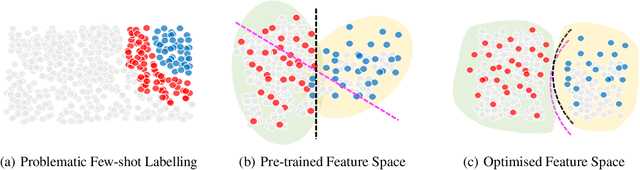
In this paper, we propose a theoretical framework to explain the efficacy of prompt learning in zero/few-shot scenarios. First, we prove that conventional pre-training and fine-tuning paradigm fails in few-shot scenarios due to overfitting the unrepresentative labelled data. We then detail the assumption that prompt learning is more effective because it empowers pre-trained language model that is built upon massive text corpora, as well as domain-related human knowledge to participate more in prediction and thereby reduces the impact of limited label information provided by the small training set. We further hypothesize that language discrepancy can measure the quality of prompting. Comprehensive experiments are performed to verify our assumptions. More remarkably, inspired by the theoretical framework, we propose an annotation-agnostic template selection method based on perplexity, which enables us to ``forecast'' the prompting performance in advance. This approach is especially encouraging because existing work still relies on development set to post-hoc evaluate templates. Experiments show that this method leads to significant prediction benefits compared to state-of-the-art zero-shot methods.