 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDA: Simple Discrete Augmentation for Contrastive Sentence Representation Learning
Paper and Code

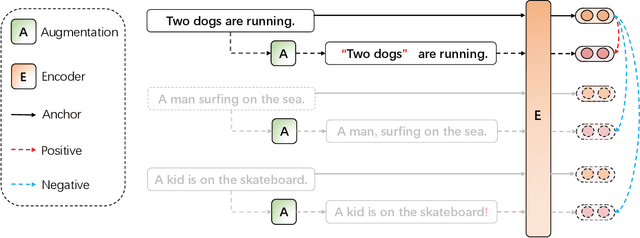


Contrastive learning methods achieve state-of-the-art results in unsupervised sentence representation learning. Although playing essential roles in contrastive learning, data augmentation methods applied on sentences have not been fully explored. Current SOTA method SimCSE utilizes a simple dropout mechanism as continuous augmentation which outperforms discrete augmentations such as cropping, word deletion and synonym replacement. To understand the underlying rationales, we revisit existing approaches and attempt to hypothesize the desiderata of reasonable data augmentation methods: balance of semantic consistency and expression diversity. Based on the hypothesis, we propose three simple yet effective discrete sentence augmentation methods, i.e., punctuation insertion, affirmative auxiliary and double negation. The punctuation marks, auxiliaries and negative words act as minimal noises in lexical level to produce diverse sentence expressions. Unlike traditional augmentation methods which randomly modify the sentence, our augmentation rules are well designed for generating semantically consistent and grammatically correct sentences. We conduct extensive experiments on both English and Chinese semantic textual similarity datasets. The results show the robustness and effectiveness of the proposed methods.