 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedLAD: A Modular and Adaptive Testbed for Federated Log Anomaly Detection
Dec 09, 2025Log-based anomaly detection (LAD) is critical for ensuring the reliability of large-scale distributed systems. However, most existing LAD approaches assume centralized training, which is often impractical due to privacy constraints and the decentralized nature of system logs. While federated learning (FL) offers a promising alternative, there is a lack of dedicated testbeds tailored to the needs of LAD in federated settings. To address this, we present FedLAD, a unified platform for training and evaluating LAD models under FL constraints. FedLAD supports plug-and-play integration of diverse LAD models, benchmark datasets, and aggregation strategies, while offering runtime support for validation logging (self-monitoring), parameter tuning (self-configuration), and adaptive strategy control (self-adaptation). By enabling reproducible and scalable experimentation, FedLAD bridges the gap between FL frameworks and LAD requirements, providing a solid foundation for future research. Project code is publicly available at: https://github.com/AA-cityu/FedLAD.
Multi-Strategy Enhanced COA for Path Planning in Autonomous Navigation
Mar 04, 2025



Autonomous navigation is reshaping various domains in people's life by enabling efficient and safe movement in complex environments. Reliable navigation requires algorithmic approaches that compute optimal or near-optimal trajectories while satisfying task-specific constraints and ensuring obstacle avoidance. However, existing methods struggle with slow convergence and suboptimal solutions, particularly in complex environments, limiting their real-world applicability. To address these limitations, this paper presents the Multi-Strategy Enhanced Crayfish Optimization Algorithm (MCOA), a novel approach integrating three key strategies: 1) Refractive Opposition Learning, enhancing population diversity and global exploration, 2) Stochastic Centroid-Guided Exploration, balancing global and local search to prevent premature convergence, and 3) Adaptive Competition-Based Selection, dynamically adjusting selection pressure for faster convergence and improved solution quality. Empirical evaluations underscore the remarkable planning speed and the amazing solution quality of MCOA in both 3D Unmanned Aerial Vehicle (UAV) and 2D mobile robot path planning. Against 11 baseline algorithms, MCOA achieved a 69.2% reduction in computational time and a 16.7% improvement in minimizing overall path cost in 3D UAV scenarios. Furthermore, in 2D path planning, MCOA outperformed baseline approaches by 44% on average, with an impressive 75.6% advantage in the largest 60*60 grid setting. These findings validate MCOA as a powerful tool for optimizing autonomous navigation in complex environments. The source code is available at: https://github.com/coedv-hub/MCOA.
Optimal Brain Iterative Merging: Mitigating Interference in LLM Merging
Feb 17, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities, but their high computational costs pose challenges for customization. Model merging offers a cost-effective alternative, yet existing methods suffer from interference among parameters, leading to performance degradation. In this work, we propose Optimal Brain Iterative Merging (OBIM), a novel method designed to mitigate both intra-model and inter-model interference. OBIM consists of two key components: (1) A saliency measurement mechanism that evaluates parameter importance based on loss changes induced by individual weight alterations, reducing intra-model interference by preserving only high-saliency parameters. (2) A mutually exclusive iterative merging framework, which incrementally integrates models using a binary mask to avoid direct parameter averaging, thereby mitigating inter-model interference. We validate OBIM through experiments on both Supervised Fine-Tuned (SFT) models and post-pretrained checkpoints. The results show that OBIM significantly outperforms existing merging techniques. Overall, OBIM provides an effective and practical solution for enhancing LLM merging.
Multi-role Consensus through LLMs Discussions for Vulnerability Detection
Mar 21, 2024

Recent advancements in large language models (LLMs) have highlighted the potential for vulnerability detection, a crucial component of software quality assurance. Despite this progress, most studies have been limited to the perspective of a single role, usually testers, lacking diverse viewpoints from different roles in a typical software development life-cycle, including both developers and testers. To this end, this paper introduces an approach to employ LLMs to act as different roles to simulate real-life code review process, engaging in discussions towards a consensus on the existence and classification of vulnerabilities in the code. Preliminary evaluation of the proposed approach indicates a 4.73% increase in the precision rate, 58.9% increase in the recall rate, and a 28.1% increase in the F1 score.
SDA: Simple Discrete Augmentation for Contrastive Sentence Representation Learning
Oct 08, 2022
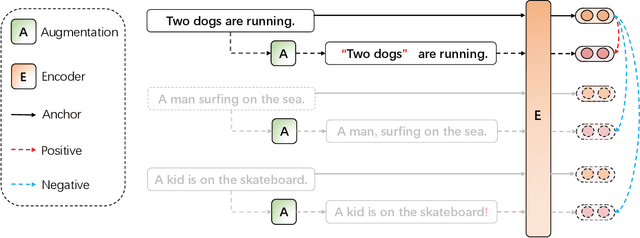


Contrastive learning methods achieve state-of-the-art results in unsupervised sentence representation learning. Although playing essential roles in contrastive learning, data augmentation methods applied on sentences have not been fully explored. Current SOTA method SimCSE utilizes a simple dropout mechanism as continuous augmentation which outperforms discrete augmentations such as cropping, word deletion and synonym replacement. To understand the underlying rationales, we revisit existing approaches and attempt to hypothesize the desiderata of reasonable data augmentation methods: balance of semantic consistency and expression diversity. Based on the hypothesis, we propose three simple yet effective discrete sentence augmentation methods, i.e., punctuation insertion, affirmative auxiliary and double negation. The punctuation marks, auxiliaries and negative words act as minimal noises in lexical level to produce diverse sentence expressions. Unlike traditional augmentation methods which randomly modify the sentence, our augmentation rules are well designed for generating semantically consistent and grammatically correct sentences. We conduct extensive experiments on both English and Chinese semantic textual similarity datasets. The results show the robustness and effectiveness of the proposed methods.
Jointly Contrastive Representation Learning on Road Network and Trajectory
Sep 14, 2022


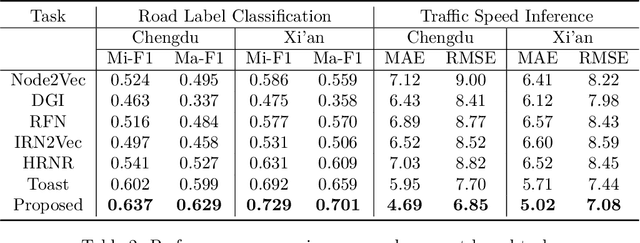
Road network and trajectory representation learning are essential for traffic systems since the learned representation can be directly used in various downstream tasks (e.g., traffic speed inference, and travel time estimation). However, most existing methods only contrast within the same scale, i.e., treating road network and trajectory separately, which ignores valuable inter-relations. In this paper, we aim to propose a unified framework that jointly learns the road network and trajectory representations end-to-end. We design domain-specific augmentations for road-road contrast and trajectory-trajectory contrast separately, i.e., road segment with its contextual neighbors and trajectory with its detour replaced and dropped alternatives, respectively. On top of that, we further introduce the road-trajectory cross-scale contrast to bridge the two scales by maximizing the total mutual information. Unlike the existing cross-scale contrastive learning methods on graphs that only contrast a graph and its belonging nodes, the contrast between road segment and trajectory is elaborately tailored via novel positive sampling and adaptive weighting strategies. We conduct prudent experiments based on two real-world datasets with four downstream tasks, demonstrating improved performance and effectiveness. The code is available at https://github.com/mzy94/JCLRNT.