 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation of Language Evolution under Regulated Social Media Platforms: A Synergistic Approach of Large Language Models and Genetic Algorithms
Feb 26, 2025Social media platforms frequently impose restrictive policies to moderate user content, prompting the emergence of creative evasion language strategies. This paper presents a multi-agent framework based on Large Language Models (LLMs) to simulate the iterative evolution of language strategies under regulatory constraints. In this framework, participant agents, as social media users, continuously evolve their language expression, while supervisory agents emulate platform-level regulation by assessing policy violations. To achieve a more faithful simulation, we employ a dual design of language strategies (constraint and expression) to differentiate conflicting goals and utilize an LLM-driven GA (Genetic Algorithm) for the selection, mutation, and crossover of language strategies. The framework is evaluated using two distinct scenarios: an abstract password game and a realistic simulated illegal pet trade scenario. Experimental results demonstrate that as the number of dialogue rounds increases, both the number of uninterrupted dialogue turns and the accuracy of information transmission improve significantly. Furthermore, a user study with 40 participants validates the real-world relevance of the generated dialogues and strategies. Moreover, ablation studies validate the importance of the GA, emphasizing its contribution to long-term adaptability and improved overall results.
KUNPENG: An Embodied Large Model for Intelligent Maritime
Jul 12, 2024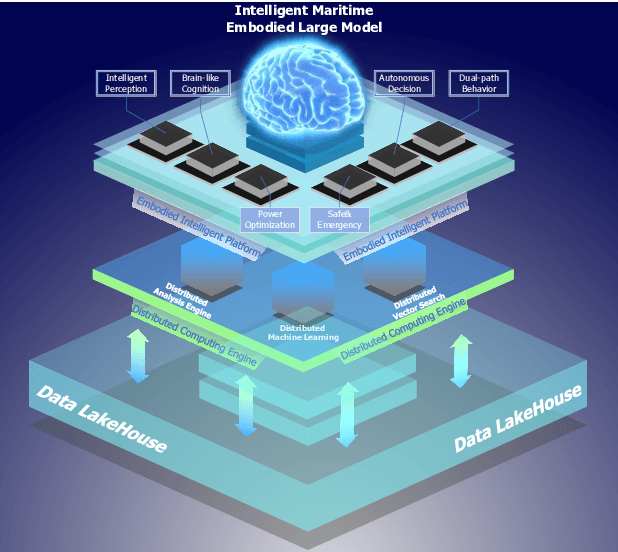
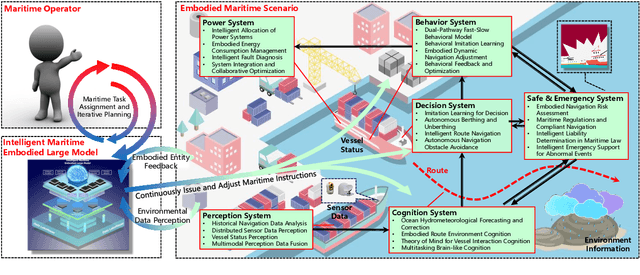
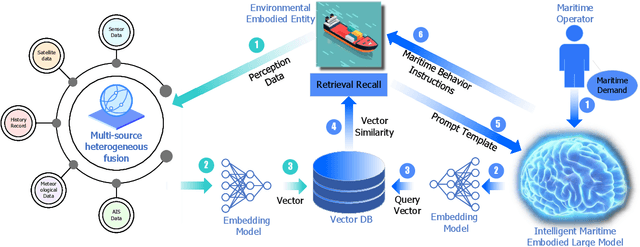
Intelligent maritime, as an essential component of smart ocean construction, deeply integrates advanced artificial intelligence technology and data analysis methods, which covers multiple aspects such as smart vessels, route optimization, safe navigation, aiming to enhance the efficiency of ocean resource utilization and the intelligence of transportation networks. However, the complex and dynamic maritime environment, along with diverse and heterogeneous large-scale data sources, present challenges for real-time decision-making in intelligent maritime. In this paper, We propose KUNPENG, the first-ever embodied large model for intelligent maritime in the smart ocean construction, which consists of six systems. The model perceives multi-source heterogeneous data for the cognition of environmental interaction and make autonomous decision strategies, which are used for intelligent vessels to perform navigation behaviors under safety and emergency guarantees and continuously optimize power to achieve embodied intelligence in maritime. In comprehensive maritime task evaluations, KUNPENG has demonstrated excellent performance.
Language Evolution for Evading Social Media Regulation via LLM-based Multi-agent Simulation
May 05, 2024



Social media platforms such as Twitter, Reddit, and Sina Weibo play a crucial role in global communication but often encounter strict regulations in geopolitically sensitive regions. This situation has prompted users to ingeniously modify their way of communicating, frequently resorting to coded language in these regulated social media environments. This shift in communication is not merely a strategy to counteract regulation, but a vivid manifestation of language evolution, demonstrating how language naturally evolves under societal and technological pressures. Studying the evolution of language in regulated social media contexts is of significant importance for ensuring freedom of speech, optimizing content moderation, and advancing linguistic research. This paper proposes a multi-agent simulation framework using Large Language Models (LLMs) to explore the evolution of user language in regulated social media environments. The framework employs LLM-driven agents: supervisory agent who enforce dialogue supervision and participant agents who evolve their language strategies while engaging in conversation, simulating the evolution of communication styles under strict regulations aimed at evading social media regulation. The study evaluates the framework's effectiveness through a range of scenarios from abstract scenarios to real-world situations. Key findings indicate that LLMs are capable of simulating nuanced language dynamics and interactions in constrained settings, showing improvement in both evading supervision and information accuracy as evolution progresses. Furthermore, it was found that LLM agents adopt different strategies for different scenarios.
Multi-role Consensus through LLMs Discussions for Vulnerability Detection
Mar 21, 2024

Recent advancements in large language models (LLMs) have highlighted the potential for vulnerability detection, a crucial component of software quality assurance. Despite this progress, most studies have been limited to the perspective of a single role, usually testers, lacking diverse viewpoints from different roles in a typical software development life-cycle, including both developers and testers. To this end, this paper introduces an approach to employ LLMs to act as different roles to simulate real-life code review process, engaging in discussions towards a consensus on the existence and classification of vulnerabilities in the code. Preliminary evaluation of the proposed approach indicates a 4.73% increase in the precision rate, 58.9% increase in the recall rate, and a 28.1% increase in the F1 score.
CGGM: A conditional graph generation model with adaptive sparsity for node anomaly detection in IoT networks
Feb 27, 2024



Dynamic graphs are extensively employed for detecting anomalous behavior in nodes within the Internet of Things (IoT). Generative models are often used to address the issue of imbalanced node categories in dynamic graphs. Nevertheless, the constraints it faces include the monotonicity of adjacency relationships, the difficulty in constructing multi-dimensional features for nodes, and the lack of a method for end-to-end generation of multiple categories of nodes. This paper presents a novel graph generation model, called CGGM, designed specifically to generate a larger number of nodes belonging to the minority class. The mechanism for generating an adjacency matrix, through adaptive sparsity, enhances flexibility in its structure. The feature generation module, called multidimensional features generator (MFG) to generate node features along with topological information. Labels are transformed into embedding vectors, serving as conditional constraints to control the generation of synthetic data across multiple categories. Using a multi-stage loss, the distribution of synthetic data is adjusted to closely resemble that of real data. In extensive experiments, we show that CGGM's synthetic data outperforms state-of-the-art methods across various metrics. Our results demonstrate efficient generation of diverse data categories, robustly enhancing multi-category classification model performance.