 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKUNPENG: An Embodied Large Model for Intelligent Maritime
Jul 12, 2024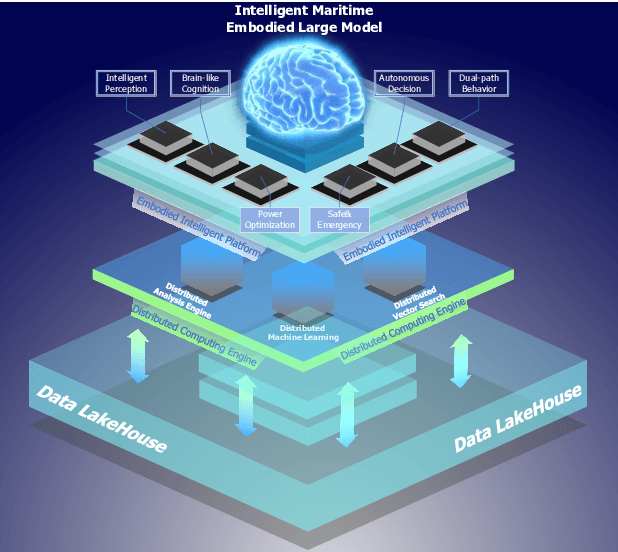
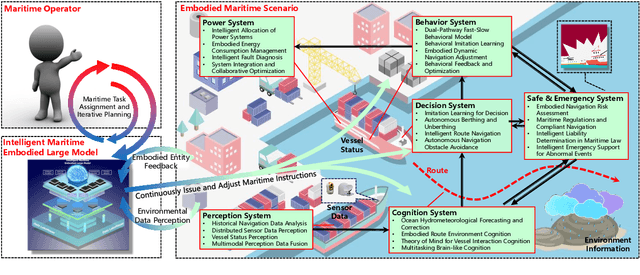
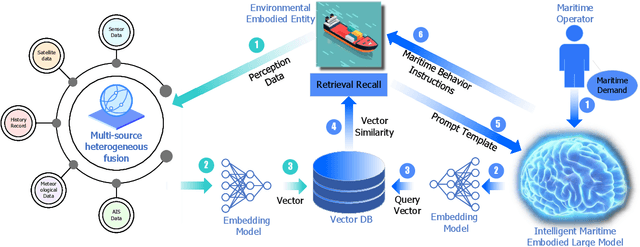
Intelligent maritime, as an essential component of smart ocean construction, deeply integrates advanced artificial intelligence technology and data analysis methods, which covers multiple aspects such as smart vessels, route optimization, safe navigation, aiming to enhance the efficiency of ocean resource utilization and the intelligence of transportation networks. However, the complex and dynamic maritime environment, along with diverse and heterogeneous large-scale data sources, present challenges for real-time decision-making in intelligent maritime. In this paper, We propose KUNPENG, the first-ever embodied large model for intelligent maritime in the smart ocean construction, which consists of six systems. The model perceives multi-source heterogeneous data for the cognition of environmental interaction and make autonomous decision strategies, which are used for intelligent vessels to perform navigation behaviors under safety and emergency guarantees and continuously optimize power to achieve embodied intelligence in maritime. In comprehensive maritime task evaluations, KUNPENG has demonstrated excellent performance.
CGGM: A conditional graph generation model with adaptive sparsity for node anomaly detection in IoT networks
Feb 27, 2024



Dynamic graphs are extensively employed for detecting anomalous behavior in nodes within the Internet of Things (IoT). Generative models are often used to address the issue of imbalanced node categories in dynamic graphs. Nevertheless, the constraints it faces include the monotonicity of adjacency relationships, the difficulty in constructing multi-dimensional features for nodes, and the lack of a method for end-to-end generation of multiple categories of nodes. This paper presents a novel graph generation model, called CGGM, designed specifically to generate a larger number of nodes belonging to the minority class. The mechanism for generating an adjacency matrix, through adaptive sparsity, enhances flexibility in its structure. The feature generation module, called multidimensional features generator (MFG) to generate node features along with topological information. Labels are transformed into embedding vectors, serving as conditional constraints to control the generation of synthetic data across multiple categories. Using a multi-stage loss, the distribution of synthetic data is adjusted to closely resemble that of real data. In extensive experiments, we show that CGGM's synthetic data outperforms state-of-the-art methods across various metrics. Our results demonstrate efficient generation of diverse data categories, robustly enhancing multi-category classification model performance.