 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultivAgents: Cultivating Relationship-Centered Multi-Agent Systems for Personalized Gardening
May 22, 2026Gardening is critical to support well-being, cultural continuity, and food autonomy, yet existing digital tools often provide generic advice that overlooks gardeners' skills, local ecologies, seasons, and cultural contexts. We introduce CultivAgents, a relationship-centered multi-agent system for personalized, socio-culturally grounded gardening support. Grounded in ethics of care, CultivAgents coordinates multiple specialized agents: an Experience Agent that adapts guidance to users' skill levels, an Environmental Agent that grounds advice in local and seasonal conditions, and an Ethnobotanical Agent that connects plants to cultural knowledge and histories. We evaluated CultivAgents through a three-phase mixed-methods study with domain experts (n=3), HCI researchers (n=7), and community gardeners (n=5), analyzing expert feedback, pre/post surveys, and participatory design activities. Results suggest that CultivAgents helped gardeners translate interest into situated action: community gardeners reported increased confidence (3.00 to 3.60), motivation (4.00 to 4.40), and trust in acting on AI advice (3.20 to 4.00). Participants valued hyperlocal ecological guidance and complementary agent perspectives, while also identifying limits in cultural specificity, ecological grounding, and agent coordination. The work advances relationship-centered AI, offering design implications for multi-agent systems that support food sovereignty, community resilience, and cultural preservation.
TextReg: Mitigating Prompt Distributional Overfitting via Regularized Text-Space Optimization
May 20, 2026Large language models (LLMs) are highly sensitive to the prompts used to specify task objectives and behavioral constraints. Many recent prompt optimization methods iteratively rewrite prompts using LLM-generated feedback, but the resulting prompts often become longer, accumulate narrow sample-specific rules, and generalize poorly beyond the training distribution. We study this failure mode as prompt distributional overfitting and argue that it reflects a lack of representation control in discrete text-space optimization. We formalize this view through representational inefficiency, a dual-factor measure that decomposes prompt inefficiency into capacity cost and scope narrowness, attributing distributional prompt overfitting to their coupled growth during optimization. We propose TextReg, a regularization framework that realizes a soft-penalty objective through regularized textual gradients, combining Dual-Evidence Gradient Purification, Semantic Edit Regularization, and Regularization-Guided Prompt Update. Across multiple reasoning benchmarks, TextReg substantially improves out-of-distribution (OOD) generalization, with accuracy gains of up to +11.8% over TextGrad and +16.5% over REVOLVE.
UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
May 07, 2026Self-distillation (SD) offers a promising path for adapting large language models (LLMs) without relying on stronger external teachers. However, SD in autoregressive LLMs remains challenging because self-generated trajectories are free-form, correctness is task-dependent, and plausible rationales can still provide unstable or unreliable supervision. Existing methods mainly examine isolated design choices, leaving their effectiveness, roles, and interactions unclear. In this paper, we propose UniSD, a unified framework to systematically study self-distillation. UniSD integrates complementary mechanisms that address supervision reliability, representation alignment, and training stability, including multi-teacher agreement, EMA teacher stabilization, token-level contrastive learning, feature matching, and divergence clipping. Across six benchmarks and six models from three model families, UniSD reveals when self-distillation improves over static imitation, which components drive the gains, and how these components interact across tasks. Guided by these insights, we construct UniSDfull, an integrated pipeline that combines complementary components and achieves the strongest overall performance, improving over the base model by +5.4 points and the strongest baseline by +2.8 points. Extensive evaluation highlights self-distillation as a practical and steerable approach for efficient LLM adaptation without stronger external teachers.
AI Driven Soccer Analysis Using Computer Vision
Apr 09, 2026Sport analysis is crucial for team performance since it provides actionable data that can inform coaching decisions, improve player performance, and enhance team strategies. To analyze more complex features from game footage, a computer vision model can be used to identify and track key entities from the field. We propose the use of an object detection and tracking system to predict player positioning throughout the game. To translate this to positioning in relation to the field dimensions, we use a point prediction model to identify key points on the field and combine these with known field dimensions to extract actual distances. For the player-identification model, object detection models like YOLO and Faster R-CNN are evaluated on the accuracy of our custom video footage using multiple different evaluation metrics. The goal is to identify the best model for object identification to obtain the most accurate results when paired with SAM2 (Segment Anything Model 2) for segmentation and tracking. For the key point detection model, we use a CNN model to find consistent locations in the soccer field. Through homography, the positions of points and objects in the camera perspective will be transformed to a real-ground perspective. The segmented player masks from SAM2 are transformed from camera perspective to real-world field coordinates through homography, regardless of camera angle or movement. The transformed real-world coordinates can be used to calculate valuable tactical insights including player speed, distance covered, positioning heatmaps, and more complex team statistics, providing coaches and players with actionable performance data previously unavailable from standard video analysis.
MASCOT: Towards Multi-Agent Socio-Collaborative Companion Systems
Jan 20, 2026Multi-agent systems (MAS) have recently emerged as promising socio-collaborative companions for emotional and cognitive support. However, these systems frequently suffer from persona collapse--where agents revert to generic, homogenized assistant behaviors--and social sycophancy, which produces redundant, non-constructive dialogue. We propose MASCOT, a generalizable framework for multi-perspective socio-collaborative companions. MASCOT introduces a novel bi-level optimization strategy to harmonize individual and collective behaviors: 1) Persona-Aware Behavioral Alignment, an RLAIF-driven pipeline that finetunes individual agents for strict persona fidelity to prevent identity loss; and 2) Collaborative Dialogue Optimization, a meta-policy guided by group-level rewards to ensure diverse and productive discourse. Extensive evaluations across psychological support and workplace domains demonstrate that MASCOT significantly outperforms state-of-the-art baselines, achieving improvements of up to +14.1 in Persona Consistency and +10.6 in Social Contribution. Our framework provides a practical roadmap for engineering the next generation of socially intelligent multi-agent systems.
GDRO: Group-level Reward Post-training Suitable for Diffusion Models
Jan 05, 2026Recent advancements adopt online reinforcement learning (RL) from LLMs to text-to-image rectified flow diffusion models for reward alignment. The use of group-level rewards successfully aligns the model with the targeted reward. However, it faces challenges including low efficiency, dependency on stochastic samplers, and reward hacking. The problem is that rectified flow models are fundamentally different from LLMs: 1) For efficiency, online image sampling takes much more time and dominates the time of training. 2) For stochasticity, rectified flow is deterministic once the initial noise is fixed. Aiming at these problems and inspired by the effects of group-level rewards from LLMs, we design Group-level Direct Reward Optimization (GDRO). GDRO is a new post-training paradigm for group-level reward alignment that combines the characteristics of rectified flow models. Through rigorous theoretical analysis, we point out that GDRO supports full offline training that saves the large time cost for image rollout sampling. Also, it is diffusion-sampler-independent, which eliminates the need for the ODE-to-SDE approximation to obtain stochasticity. We also empirically study the reward hacking trap that may mislead the evaluation, and involve this factor in the evaluation using a corrected score that not only considers the original evaluation reward but also the trend of reward hacking. Extensive experiments demonstrate that GDRO effectively and efficiently improves the reward score of the diffusion model through group-wise offline optimization across the OCR and GenEval tasks, while demonstrating strong stability and robustness in mitigating reward hacking.
CompanionCast: A Multi-Agent Conversational AI Framework with Spatial Audio for Social Co-Viewing Experiences
Dec 11, 2025Social presence is central to the enjoyment of watching content together, yet modern media consumption is increasingly solitary. We investigate whether multi-agent conversational AI systems can recreate the dynamics of shared viewing experiences across diverse content types. We present CompanionCast, a general framework for orchestrating multiple role-specialized AI agents that respond to video content using multimodal inputs, speech synthesis, and spatial audio. Distinctly, CompanionCast integrates an LLM-as-a-Judge module that iteratively scores and refines conversations across five dimensions (relevance, authenticity, engagement, diversity, personality consistency). We validate this framework through sports viewing, a domain with rich dynamics and strong social traditions, where a pilot study with soccer fans suggests that multi-agent interaction improves perceived social presence compared to solo viewing. We contribute: (1) a generalizable framework for orchestrating multi-agent conversations around multimodal video content, (2) a novel evaluator-agent pipeline for conversation quality control, and (3) exploratory evidence of increased social presence in AI-mediated co-viewing. We discuss challenges and future directions for applying this approach to diverse viewing contexts including entertainment, education, and collaborative watching experiences.
DiffCamera: Arbitrary Refocusing on Images
Sep 30, 2025
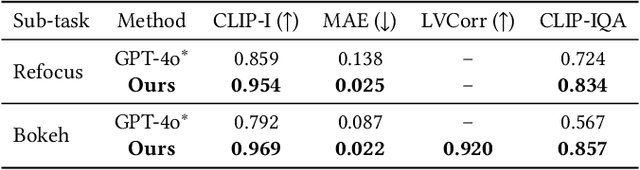
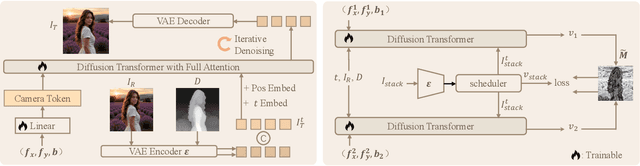

The depth-of-field (DoF) effect, which introduces aesthetically pleasing blur, enhances photographic quality but is fixed and difficult to modify once the image has been created. This becomes problematic when the applied blur is undesirable~(e.g., the subject is out of focus). To address this, we propose DiffCamera, a model that enables flexible refocusing of a created image conditioned on an arbitrary new focus point and a blur level. Specifically, we design a diffusion transformer framework for refocusing learning. However, the training requires pairs of data with different focus planes and bokeh levels in the same scene, which are hard to acquire. To overcome this limitation, we develop a simulation-based pipeline to generate large-scale image pairs with varying focus planes and bokeh levels. With the simulated data, we find that training with only a vanilla diffusion objective often leads to incorrect DoF behaviors due to the complexity of the task. This requires a stronger constraint during training. Inspired by the photographic principle that photos of different focus planes can be linearly blended into a multi-focus image, we propose a stacking constraint during training to enforce precise DoF manipulation. This constraint enhances model training by imposing physically grounded refocusing behavior that the focusing results should be faithfully aligned with the scene structure and the camera conditions so that they can be combined into the correct multi-focus image. We also construct a benchmark to evaluate the effectiveness of our refocusing model. Extensive experiments demonstrate that DiffCamera supports stable refocusing across a wide range of scenes, providing unprecedented control over DoF adjustments for photography and generative AI applications.
LayerFlow: A Unified Model for Layer-aware Video Generation
Jun 04, 2025We present LayerFlow, a unified solution for layer-aware video generation. Given per-layer prompts, LayerFlow generates videos for the transparent foreground, clean background, and blended scene. It also supports versatile variants like decomposing a blended video or generating the background for the given foreground and vice versa. Starting from a text-to-video diffusion transformer, we organize the videos for different layers as sub-clips, and leverage layer embeddings to distinguish each clip and the corresponding layer-wise prompts. In this way, we seamlessly support the aforementioned variants in one unified framework. For the lack of high-quality layer-wise training videos, we design a multi-stage training strategy to accommodate static images with high-quality layer annotations. Specifically, we first train the model with low-quality video data. Then, we tune a motion LoRA to make the model compatible with static frames. Afterward, we train the content LoRA on the mixture of image data with high-quality layered images along with copy-pasted video data. During inference, we remove the motion LoRA thus generating smooth videos with desired layers.
DiffDoctor: Diagnosing Image Diffusion Models Before Treating
Jan 21, 2025



In spite of the recent progress, image diffusion models still produce artifacts. A common solution is to refine an established model with a quality assessment system, which generally rates an image in its entirety. In this work, we believe problem-solving starts with identification, yielding the request that the model should be aware of not just the presence of defects in an image, but their specific locations. Motivated by this, we propose DiffDoctor, a two-stage pipeline to assist image diffusion models in generating fewer artifacts. Concretely, the first stage targets developing a robust artifact detector, for which we collect a dataset of over 1M flawed synthesized images and set up an efficient human-in-the-loop annotation process, incorporating a carefully designed class-balance strategy. The learned artifact detector is then involved in the second stage to tune the diffusion model through assigning a per-pixel confidence map for each synthesis. Extensive experiments on text-to-image diffusion models demonstrate the effectiveness of our artifact detector as well as the soundness of our diagnose-then-treat design.